







一个引人入胜的场景:每周都涌现出大量的生物信息学数据,需要按照预定周期进行公示,以便在各个业务部门中找到相应的责任人、运营经理和生信专家,进而进行数据删除。这一流程还需要确保超期周期的可调整性。通过巧妙地运用 AWK 的 ARGIND 模块结合哈希算法,我们摆脱了以往 Bash 脚本在文件合并过程中所遭遇的缓慢、CPU 和内存资源占用过多的困扰。如今,文件合并不过是在短短几十秒内完成,而以前的 Bash 脚本在分析 279TB 的超期数据时需要耗费约 3 分钟,而 Python 脚本生成 Excel 表格并进行数据透视也只需大约 4 分钟。我们还打造了定时任务计划,确保数据的准确性,从而在自动化的同时,将网络界面上的公示与生信人员的主动获取结果巧妙地结合在一起。
[toc]
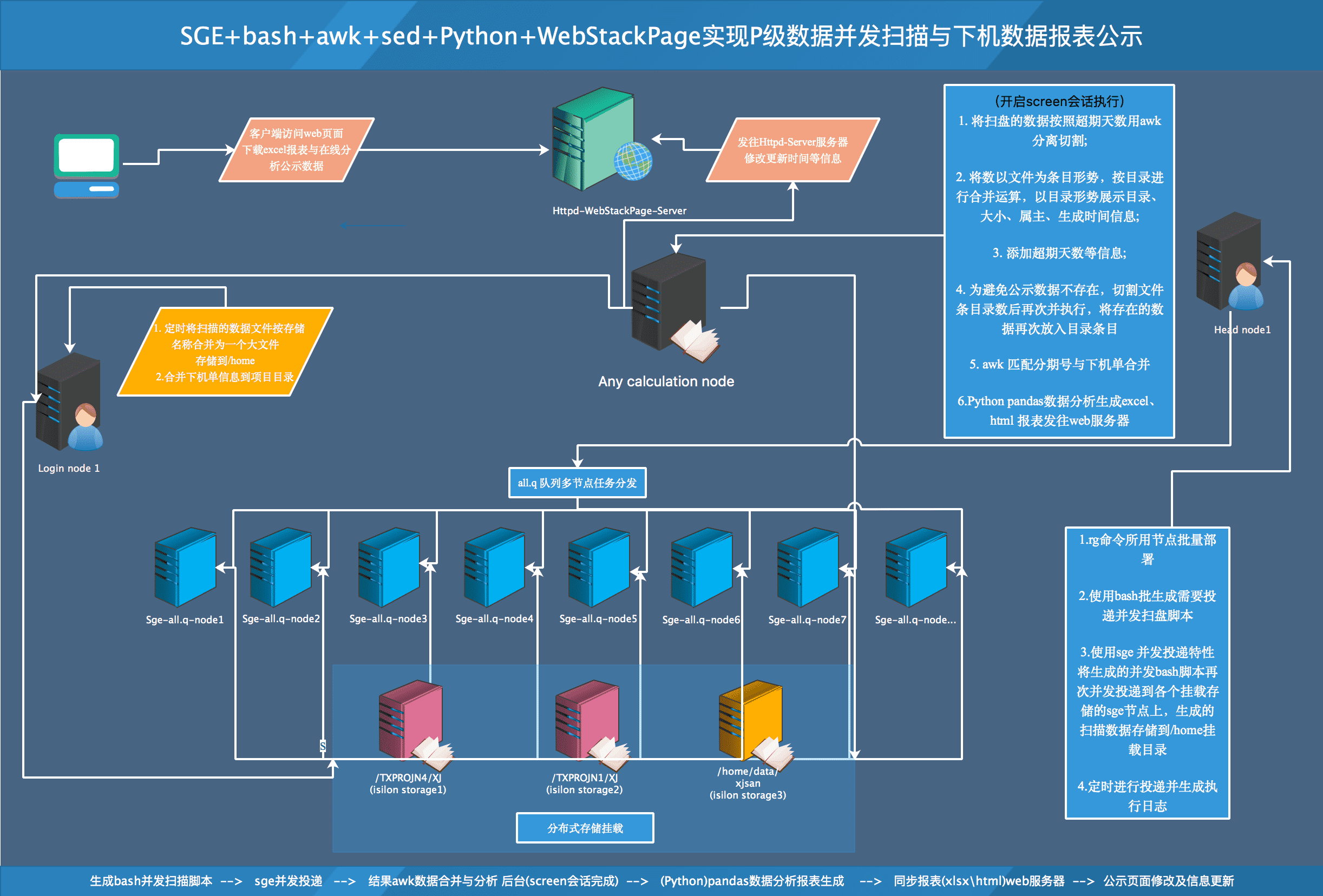
SGE+bash+awk+sed+Python+WebStackPage 实现P级数据并发扫描与数据报表公示系统
- 需求与实现初衷
- 生信类数据每周有大量的下机数据,需要按照超期周期公示到各个业务部门找对应的负责人、运营经理、生信分息等进行删除,并且要保证超期周期可调整;
- 想把下机公示的脚本写成高效扫盘的脚本,实现分发投递,与数据扫盘时数据中断的可控性;不影响每周的下机数据公示; 扫盘数据匹配人员,数据分析、数据透视的准确性,超期周期,任务进度把控与匹配,要确保每次公示数据的存在性,计算的准确性等等;
- 每次定任务删除进度时,只发送邮件,由使用各管理员自己去web 页面下载分析好的超期数据;进行实时分析与更新,主动把控数据的清除进度与任务推进。
- 实现与突破
使用rg命令结合 stat 命令、bash 并发、qsub 多任务的投递,突破了扫盘慢的问题,P级扫盘共需2-8小时左右,2小时基本可以把很大部分数据量扫下来,因个别目录文件比较碎,在8小时左右全部扫完,但是碎方件占用量不大,基本不影响数据的总量;
使用awk 的 ARGIND模块结合hash算法,突破了bash脚本两文件合并慢,占用cpu,内存资源慢的问题,可以10几秒内完成合并,现bash脚本分析(279T)超期数据,需3分钟左右的时间,python脚本 excel 表格生成,数据透视共需4分钟左右。定义扫盘定时任务计划,确认数据的准确性,自动化结合这块,web 页面公示与生信人员自主获取公示结果。
- 环境需求
- SGE 高性能集群;
- 分布式挂载存储;
实现逻辑图
扫盘命令挑选— rg 命令
- 如果说目录下文件个数较少,数据量较小时,我们大可不必考虑扫盘效率的问题;
- 但当文件数目超过几千万、甚至1亿总数据量超过P时,我们要挑选性能优的扫盘命令工具做底层是毋庸置疑的;
- 经查找资源,测试发现,rg 命令可以代替ls 和find 进行快的扫盘,大的目录扫描时效率较高;相传要比find快n倍;
- 命令如下
rg --files /PATH/DIR | xargs -I {} stat -c \"%n####%s####%U####%z\" {}
首先要统计部门-管理员等相关信息
这里可以看一下类似的信息,敏感信息已用xx隐藏
xj_id_class 文件,用于根据扫出的条目列表中的利润编号匹配管理员,部门详情,管理员邮箱等信息
02xx,TESTDPART1,leixxx,XX中心-XX中心-XX转化研究部-生信分析组,leixxx@xxx.com
19xx,TESTANI1,zhangxxx,XX中心-XX医学研究部-生信分析,zhangxxx@xxx.com
19xx,TESTCAN,leixxx,XX中心-XX作物研究部-生信分析,leixxx@xxx.com
10xx,TESTHEAL,jianxxx,XX中心-XX事业部-生信分析组,jianxxx@xxx.com
14xx,TESTHW,weixxx,海外XX-交付组,weixxx.xxx.com
定义xjscan 主脚本全局变量
source /etc/profile
source /root/.bashrc
source /root/.bash_profile
project_dir='/test/data/xjscan/'
other_storage_txxj1='/TXPORJ1/XJ'
other_storage_txxj4='/XXPROJ4/XJ'
xxxj5_name='XXPROJ5'
xxxj1_name='XXPROJ1'
id_group_file='xj_id_class'
library_file='project_library.xls'
s5_dir='/XXPROJ4/XJ/S5_production'
dir_10x='/XXPROJ4/XJ/Data_production/10xgen/'
share_dir='/XXPROJ4/XJ/department_data/shared'
s5_dir='/XXPROJ4/XJ/S5_produ'
now_time=`date +"%Y-%m"`
[ -d $now_time ] || mkdir $now_time
other_storage_dir="$now_time/other"
[ -d $other_storage_dir ] || mkdir $other_storage_dir
other_storage_data="$other_storage_dir/data/"
[ -d $other_storage_data ] || mkdir $other_storage_data
other_storage_cache="$other_storage_dir/cache/"
[ -d $other_storage_cache ] || mkdir $other_storage_cache
other_storage_shell="$other_storage_dir/shell/"
[ -d $other_storage_shell ] || mkdir $other_storage_shell
主脚本各模块实现与功能
create_data_tx1 函数模块
将XXPROJ1盘下的XJ 盘扫描生成并发执行脚本,并投递到all.q 等多个计算节点上;
为避免投递后投行完shell脚本本身的一个并发退出,需要在并发后添加& ,即{} & 的形势;
或者自己在生成的扫盘脚本中检测进程是否存在,进程不存时,再退出投递的脚本;
create_data_xx1() {
### 将存储的二级目录的文件统计下来 ###
> $other_storage_data/$xjxx1_name.FINDF2
for i in `find $other_storage_xxxj1 -maxdepth 2 -type f `; do
echo $i | xargs -I {} stat -c "%n####%s####%U####%z" {} >> $other_storage_data/$xjxx1_name.FINDF2
done
## 将存储的二级目录的目录统计下来,并生成投递的命令 ###
for i in `find $other_storage_xjxx1 -maxdepth 2 -mindepth 2 -type d`;
do
shell_name=`echo $i |sed 's/^\///g' | sed 's/\//_/g' | awk '{print $0".rg.qsub.sh"}'`
data_name=`echo $i | sed 's/^\///g' | sed 's/\//_/g' | awk '{print $0".FINDD2"}'`
file_num=`ls -l $i | sed '1d' |wc -l`
## 判断目录个数来切分脚本中的并发数;
if [ $file_num -le 10 ] ;then
echo "#!/bin/bash" > $other_storage_shell$shell_name
echo "rg --files $i | xargs -I {} stat -c \"%n####%s####%U####%z\" {} &> $project_dir$other_storage_data$data_name" &>> $other_storage_shell$shell_name
fi
## 判断子目录个数来切分脚本中的并发数
if [ $file_num -gt 10 ] ; then
echo "#!/bin/bash " > $other_storage_shell$shell_name
echo "{" >> $other_storage_shell$shell_name
num=0
echo "> $project_dir$other_storage_data$data_name" >>$other_storage_shell$shell_name
for b in `ls -l $i| sed '1d' | awk '{print $8}' `;
do
echo "rg --files $i/$b | xargs -I {} stat -c \"%n####%s####%U####%z\" {} &>> $project_dir$other_storage_data$data_name$num & " &>> $other_storage_shell$shell_name
num=$[$num+1]
done
echo "}" >> $other_storage_shell$shell_name
echo "wait" >> $other_storage_shell$shell_name
cat <<EOF >> $other_storage_shell$shell_name
rg_ps_num=\`ps aux | grep 'rg --files' | wc -l \`
while [ \$rg_ps_num -gt 1 ] ; do
sleep 60
rg_ps_num=\`ps aux | grep 'rg --files' | wc -l \`
done
EOF
fi
done
## 将生成的脚本投递到挂载存储盘的多个节点上进行扫描(开始并发执行)
for i in ` cd $project_dir$other_storage_shell && ls $xjxx1_name*"rg"*"sh"`;do
qsub -l vf=0,p=0 $project_dir$other_storage_shell$i
sleep 2.5
done
}
data_agregation 函数模块
- 将扫盘的数据文件合并成一个大的文件,方便于分离超期数据,与数据分析;
- 执行get_proj_info.sh 将原有的下机人员记录的信息做数据全并,存入项目目录中,用于后面详情匹配;
data_aggregation () {
time_dxx1ays=`date +"%Y-%m-%d-"`
cd $project_dir && mv $other_storage_cache$xxxj1_name $other_storage_cache.$time_days$xxxj1_name
cd $project_dir && find $other_storage_data -name "$xxxj1_name*FIND*" | xargs -I {} cat {} |awk '{$NF=""}{print $0}'| awk '{$NF=""}{print $0}' &> $other_storage_cache$xxxj1_name
cd $project_dir && bash get_proj_info.sh
}
over_due_xx1 函数模块
- 实现功能
- 将合并的大的扫盘数据文件,按指定的超期周期进合切割与分离;
- 将以文件为条录的数据信息,合并为目录的形势,并按照目录提取文件信息,目录信息,及~以目录的形势来合并计算目录的大小;
- 再次处理数据,将目录中的信息与定义好的xj_id_class中的部门等信息做匹配存放到临时的缓存文件中;
- 分离匹配不到部门与特殊目录的信息,存入其它缓存中,做二次处理;
over_due_xx1 () {
### Separate overdue files from all data sources ###
awk -v ntime="$ntime" -v cycle="$cycle" -v stop_cycle="$stop_cycle" -F '####' '{split($4,ti,"-");filetime=mktime(ti[1]" "ti[2]" "ti[3]" ""0 0 0")}{moretime=(ntime-filetime)/86400}{if(moretime > cycle && moretime <stop_cycle){print $0}}' $other_storage_cache$xxxj1_name &> $other_storage_cache$xxxj1_name$over_due_name
### Merge file size to directory size ###
cat $other_storage_cache$xxxj1_name$over_due_name | grep -v "$s5_dir" | awk -F '####' '{OFS="####"}{dirname = gensub("/*[^/]*/*$", "", "", $1);print dirname,$2,$3,$4}' | awk -F '####' '{a[$1"####"$3"####"$4]+=$2}END{for(i in a) print i"####"a[i]}' &> $other_storage_cache.$xxxj1_name$over_due_name
cat $other_storage_cache$xxxj1_name$over_due_name | grep "$s5_dir" | awk -F '####' -v OFS='####' '{print $1,$3,$4,$2}' &>> $other_storage_cache.$xxxj1_name$over_due_name
#awk -F '####' '{OFS="####"}{dirname = gensub("/*[^/]*/*$", "", "", $1);print dirname,$2,$3,$4}' $other_storage_cache$xxxj1_name$over_due_name | awk -F '####' '{OFS="####"}{dirname = gensub("/*[^/]*/*$", "", "", $1);print dirname,$2,$3,$4}' | awk -F '####' '{a[$1"####"$3"####"$4]+=$2}END{for(i in a) print i"####"a[i]}' &> $other_storage_cache.$xxxj1_name$over_due_name
mv $other_storage_cache.$xxxj1_name$over_due_name $other_storage_cache$xxxj1_name$over_due_name
### Add the group and ID project Numbers ###
awk -F '####' -v OFS='####' '{gsub(/ /,"",$3)}{print $0}' $other_storage_cache$xxxj1_name$over_due_name &> $other_storage_cache.$xxxj1_name$over_due_name
mv $other_storage_cache.$xxxj1_name$over_due_name $other_storage_cache$xxxj1_name$over_due_name
grep_group_id=''
for i in `cat $id_group_file`; do
group_id=`echo $i | awk -F ',' '{print $1}'`
group_name=`echo $i | awk -F ',' '{print $2}'`
awk -v group_id="$group_id" -v group_name="$group_name" -v OFS="\t" -F '####' '{split($1,wenku,"/");wenku_num=length(wenku)}{if($1 ~ "/"group_id"/"){print $4,$3,group_id,$2,$1,wenku[wenku_num],group_name}}' $other_storage_cache$xxxj1_name$over_due_name &>> $other_storage_cache$libproj
grep_group_id="$grep_group_id/$group_id/|"
done
grep_group_id_v=`echo $grep_group_id | sed s'/.$//'`
cat $other_storage_cache$xxxj1_name$over_due_name | egrep -v "$grep_group_id_v" | awk -F "####" -v OFS="\t" '{print $1,$2,$3,$4}' &>> $other_storage_cache$other_file
awk -F '\t' -v cycle="$cycle" '{sum+=$4}END{print "Expiration date "cycle,sum}' $other_storage_cache$other_file &>> $other_storage_cache$other_file
}
add_over_date 函数模块
计算并添加目录条目录的超期天数项
add_over_date() {
awk -F '\t' -v ntime="$ntime" -v OFS='\t' '{split($2,ti,"-");filetime=mktime(ti[1]" "ti[2]" "ti[3]" ""0 0 0")}{moretime=(ntime-filetime)/86400}{print $0,moretime}' $other_storage_cache$libproj &> $other_storage_cache.$libproj
mv $other_storage_cache.$libproj $other_storage_cache$libproj
awk -F '\t' -v ntime="$ntime" -v OFS='\t' '{split($3,ti,"-");filetime=mktime(ti[1]" "ti[2]" "ti[3]" ""0 0 0")}{moretime=(ntime-filetime)/86400}{print $4,$3,$2,$1,moretime}' $other_storage_cache$other_file &> $other_storage_cache.$other_file
mv $other_storage_cache.$other_file $other_storage_cache$other_file
}
overall_xx 函数模块
- 首先根据目录中的分期号等信息等值关联合并查询;
- 注
a[s]=$4"\t"$6"\t"$7"\t"这个就是建哈希,a是哈希名。以s键,后边为值,num就是第一列/分割长度,s=wenku[num]就是取最后一个, c就是另一个文件的key值,如果在哈希里有值,就执行下边的语句。 此项分析也是脚本实现高效运算的核心所在; - 详情页数据大小为B, 汇总分析页数据大小合并运算为G。
> $other_storage_cache$overall
## 详情页的生成
## 匹配到相关信息的人员数据精确匹配与合并
awk -F '\t' -v OFS='\t' 'ARGIND==1{split($1,wenku,"/");num=length(wenku);s=wenku[num]""$5;t=wenku[num]"-"$2""$5;a[s]=$6"\t"$7"\t"$8"\t"$9"\t"$10;b[t]=$6"\t"$7"\t"$8"\t"$9"\t"$10}ARGIND==2{c=$6""$3;if(a[c]){print $0,a[c]} else if(b[c]){print $0,b[c]}}' $library_file $other_storage_cache$libproj &> $other_storage_cache.$libproj_location
## 未匹配到相关信息人员的数据输出与合并
awk -F '\t' -v OFS='\t' 'ARGIND==1{split($1,wenku,"/");num=length(wenku);s=wenku[num]""$5;t=wenku[num]"-"$2""$5;a[s]=$6"\t"$7"\t"$8"\t"$9;b[t]=$6"\t"$7"\t"$8"\t"$9}ARGIND==2{c=$6""$3;if(!a[c] && ! b[c]){print $0,"-","-","-","-","-"}}' $library_file $other_storage_cache$libproj &>> $other_storage_cache.$libproj_location
mv $other_storage_cache.$libproj_location $other_storage_cache$libproj_location
## 汇总页的数据生成与分析并匹配获取部门与管理人员相关信息
bash xjsan_nodepartment.sh $cycle $stop_cycle
cat $id_group_file | awk -F ',' -v OFS='\t' '{print $1,$2,$3,$4,$5}' &> .$id_group_file
awk -F '\t' -v OFS='\t' 'ARGIND==1{s=$1;a[s]=$4"-"$2"-"$3}ARGIND==2{c=$3;if(a[c]){print $0,a[c]} else {print $0,"-"}}' .$id_group_file $other_storage_cache$libproj_location | awk -F '\t' -v OFS='\t' '{print $14,$3,$6,$1,$9,$10,$11,$12,$8}' | awk -F'\t' -v OFS='\t' '{a[$1"\t"$2"\t"$6"\t"$7"\t"$8"\t"$5]+=$4;b[$1"\t"$2"\t"$6"\t"$7"\t"$8"\t"$5]=b[$1"\t"$2"\t"$6"\t"$7"\t"$8"\t"$5]$3",";c[$1"\t"$2"\t"$6"\t"$7"\t"$8"\t"$5]+=$9;d[$1"\t"$2"\t"$6"\t"$7"\t"$8"\t"$5]++}END{for (i in a)print i,a[i],c[i]/d[i],b[i]}' | sed 's/,$//g' | awk -F '\t' '{printf "%s\t%s\t%s\t%s\t%s\t%.2f\t%s\t%s\t%s\n",$1,$2,$3,$4,$6,$7/1024/1024/1024,$8,$5,$9}' &> $other_storage_cache.$overall
echo $other_storage_cache.$overall $other_storage_cache$overall
awk -F '\t' -v OFS='\t' 'ARGIND==1{split($1,wenku,"/");num=length(wenku);s=wenku[num]""$5;t=wenku[num]"-"$2""$5;a[s]=$6"\t"$7"\t"$8"\t"$9;b[t]=$6"\t"$7"\t"$8"\t"$9}ARGIND==2{c=$6""$3;if(!a[c] && ! b[c]){print $0,"-","-","-","-","-"}}' $library_file $other_storage_cache$libproj &>> $other_storage_cache.$libproj_location
mv $other_storage_cache.$overall $other_storage_cache$overall
xjsan_nodepartment.sh 无法精确匹配、使用正则
有一些特殊情况的数据需要使用正则来特殊处理
## 项目相关环境变量这里不再重复,可以调用, 主shell 脚本,也可以在这里重新定义。
stop_cycle="$2"
time_year_month_day=`date -d -$cycle\day +'%Y-%m-%d'`
libproj="able_lib.xls"
libproj_location="able.$time_year_month_day.lib.xls "
overall="$time_year_month_day.ProjInfo.XJpath.xls"
other_file="$time_year_month_day.other.xls"
pub_other_file="pub_$other_file"
work_other_file="work_$other_file"
dir_file="$time_year_month_day.dir.xls"
over_due_name='_overdue'
libproj_location="able.$time_year_month_day.lib.xls "
> $other_storage_cache$dir_file
dir10x_func() {
grep $dir_10x $other_storage_cache$pub_other_file | egrep "F[[:upper:]]{1,4}[[:digit:]]{6,13}-[[:alnum:]][[:alnum:]]" | sed -r 's/(.*)(F[[:upper:]]{1,4}[[:digit:]]{6,13}-[[:alnum:]][[:alnum:]])(.*)/\1\2\3\t\2/g' &> $other_storage_cache.$dir_file
awk -F '\t' -v OFS='\t' 'ARGIND==1{split($1,wenku,"/");num=length(wenku);s=wenku[num];a[s]=$5"\t"$6"\t"$7"\t"$8"\t"$9"\t"$10;}ARGIND==2{c=$6;if(a[c]){print $0,a[c]}}' $library_file $other_storage_cache.$dir_file &>> $other_storage_cache$dir_file
rm -f $other_storage_cache.$dir_file
grep $dir_10x $other_storage_cache$pub_other_file | egrep -v "F[[:upper:]]{1,4}[[:digit:]]{6,13}-[[:alnum:]][[:alnum:]]" |egrep "/.*[[:digit:]]{4,8}_[[:alnum:]]{4,8}_[[:digit:]]{3,5}_[[:alnum:]]{8,12}-?[[:alnum:]]{1,4}?-?[[:alnum:]]{1,4}?-?[[:alnum:]]{1,4}?" | sed -r 's#(.*)(/.*/.*/.*/.*/.*[[:digit:]]{4,8}_[[:alnum:]]{4,8}_[[:digit:]]{3,5}_[[:alnum:]]{8,12}-?[[:alnum:]]{1,4}?-?[[:alnum:]]{1,4}?-?[[:alnum:]]{1,4}?)(.*)#\1\2\3\t\2#g' &> $other_storage_cache.$dir_file
awk -F '\t' -v OFS='\t' 'ARGIND==1{split($1,wenku,"/");s="/"wenku[2]"/"wenku[3]"/"wenku[4]"/"wenku[5]"/"wenku[6];a[s]=$5"\t"$6"\t"$7"\t"$8"\t"$9"\t"$10;}ARGIND==2{c=$6;if(a[c]){print $0,a[c]}}' $library_file $other_storage_cache.$dir_file &>> $other_storage_cache$dir_file
rm -f $other_storage_cache.$dir_file
}
dirs5_func() {
grep $s5_dir $other_storage_cache$pub_other_file | egrep "F[[:upper:]]{1,4}[[:alnum:]]{6,13}-?[[:alnum:]][[:alnum:]]" | sed -r 's/(.*)(F[[:upper:]]{1,4}[[:alnum:]]{6,13}-?[[:alnum:]][[:alnum:]])(.*)/\1\2\3\t\2/g' &> $other_storage_cache.$dir_file
awk -F '\t' -v OFS='\t' 'ARGIND==1{split($1,wenku,"/");num=length(wenku);s=wenku[num];a[s]=$5"\t"$6"\t"$7"\t"$8"\t"$9"\t"$10;}ARGIND==2{c=$6;if(a[c]){print $0,a[c]}}' $library_file $other_storage_cache.$dir_file &>> $other_storage_cache$dir_file
rm -f $other_storage_cache.$dir_file
}
share_func() {
grep $share_dir $other_storage_cache$pub_other_file | egrep "F[[:upper:]]{1,4}[[:alnum:]]{6,13}-?[[:alnum:]][[:alnum:]]" | sed -r 's/(.*)(F[[:upper:]]{1,4}[[:alnum:]]{6,13}-?[[:alnum:]][[:alnum:]])(.*)/\1\2\3\t\2/g' &> $other_storage_cache.$dir_file
awk -F '\t' -v OFS='\t'
'ARGIND==1{split($1,wenku,"/");num=length(wenku);s=wenku[num];a[s]="share\t-\t-\t-\t"$9"\t-\t-";} ARGIND==2{c=$6;if(a[c]){print $0,a[c]}}' $library_file $other_storage_cache.$dir_file &>> $other_storage_cache$dir_file
rm -f $other_storage_cache.$dir_file
}
create_func() {
awk -F '\t' -v OFS='\t' '{print $1,$2,$7,$3,$4,$6,"-",$5,$8,$9,$10,$11,$12}' $other_storage_cache$dir_file &> $other_storage_cache.$dir_file
mv $other_storage_cache.$dir_file $other_storage_cache$dir_file
cat $other_storage_cache$dir_file &>> $other_storage_cache$libproj_location
}
dir10x_func
dirs5_func
share_func
create_func
delete_old 函数模块
将精匹配的详情数据,切割大小,并发检测目录的存在性;
注: 因为数据的特殊性,下机类的数据删除后,目录为空或者目录不存在;
因此,这里使用以下函数来实现数据的时效性。
delete_old () {
rm -f $project_dir$other_storage_cache\ablelib-split*
rm -f $project_dir$other_storage_cache$libproj\_cache*
cd $project_dir$other_storage_cache && split $libproj ablelib-split -l 2000
num=0
for i in `ls $project_dir$other_storage_cache\ablelib-split*`; do
awk '{cmd="ls -A " $5 " 2> /dev/null | wc -w"}{cmd| getline dir;close(cmd)}{if(dir>0){print $0}}' $i &> $project_dir$other_storage_cache$libproj\_cache$num &
num=$[$num+1]
sleep 0.5
done
awk_ps_num=`ps aux | grep 'awk' | grep 'cmd' | grep 'getline' |wc -l`
while [ $awk_ps_num -gt 1 ] ; do
sleep 10
awk_ps_num=`ps aux | grep 'awk' | grep 'cmd' | grep 'getline' |wc -l`
done
cat $project_dir$other_storage_cache$libproj\_cache* &> $project_dir$other_storage_cache$libproj
rm -f $project_dir$other_storage_cache\ablelib-split*
rm -f $project_dir$other_storage_cache$libproj\_cache*
}
delete_no_exists 函数模块
确保没有匹配到部门的数据,使用正则二次匹配的数据条目的实效性;
delete_no_exists () {
cat $project_dir$other_storage_cache$other_file | egrep "($dir_10x|$share_dir|$s5_dir)" &> $project_dir$other_storage_cache$pub_other_file
cat $project_dir$other_storage_cache$other_file | egrep -v "($dir_10x|$share_dir|$s5_dir)" &> $project_dir$other_storage_cache$work_other_file
rm -f $project_dir$other_storage_cache\other-file-split*
rm -f $project_dir$other_storage_cache$other_file\_other\_cache*
cd $project_dir$other_storage_cache && split $pub_other_file other-file-split -l 2000
num=0
for i in `ls $project_dir$other_storage_cache\other-file-split*`; do
awk '{cmd="ls -A " $4 " 2> /dev/null | wc -w"}{cmd| getline dir;close(cmd)}{if(dir>0){print $0}}' $i &> $project_dir$other_storage_cache$other_file\_other\_cache$num &
num=$[$num+1]
sleep 0.5
done
awk_ps_num=`ps aux | grep 'awk' | grep 'cmd' | grep 'getline' |wc -l`
while [ $awk_ps_num -gt 1 ] ; do
sleep 10
awk_ps_num=`ps aux | grep 'awk' | grep 'cmd' | grep 'getline' |wc -l`
done
cat $project_dir$other_storage_cache$other_file\_other\_cache* &> $project_dir$other_storage_cache$pub_other_file
rm -f $project_dir$other_storage_cache\other-file-split*
rm -f $project_dir$other_storage_cache$other_file\_other\_cache*
}
函数的整合
if [ ! $1 ];then
echo -e "Please input (delivery: 'Post generated data' OR merge: 'Merge the generated data' OR 38:'Are days overdue')"
exit 1
fi
if [ $1 == "delivery" ] ; then
if_days=`date +"%d"`
if [ $if_days -ge 27 ]; then
now_time=`date +"%Y-%m"`
now_time=`date -d +1\Month +'%Y-%m'`
[ -d $now_time ] || mkdir $now_time
other_storage_dir="$now_time/other"
[ -d $other_storage_dir ] || mkdir $other_storage_dir
other_storage_data="$other_storage_dir/data/"
[ -d $other_storage_data ] || mkdir $other_storage_data
other_storage_cache="$other_storage_dir/cache/"
[ -d $other_storage_cache ] || mkdir $other_storage_cache
other_storage_shell="$other_storage_dir/shell/"
[ -d $other_storage_shell ] || mkdir $other_storage_shell
fi
cd $project_dir && rm -f $other_storage_data$XXxj5_name*FIND*2
cd $project_dir && rm -f $other_storage_data$XXxj4_name*FIND*2
cd $project_dir && rm -f $other_storage_data$XX5test_name*FIND*2
cd $project_dir && rm -f $other_storage_shell$XXxj5_name*sh
cd $project_dir && rm -f $other_storage_shell$XXxj4_name*sh
cd $project_dir && rm -f $other_storage_shell$XX5test_name*sh
create_data_xx1
fi
if [ $1 == "merge" ] ; then
data_aggregation
fi
if [[ $1 =~ [0-9] ]] && [[ $2 =~ [0-9] ]] ; then
over_due_name='_overdue'
cycle="$1"
stop_cycle="$2"
time_year_month_day=`date -d -$cycle\day +'%Y-%m-%d'`
libproj="able_lib.xls"
libproj_location="able.$time_year_month_day.lib.xls "
overall="$time_year_month_day.ProjInfo.XJpath.xls"
other_file="$time_year_month_day.other.xls"
ntime=`date +%s`
pub_other_file="pub_$other_file"
work_other_file="work_$other_file"
dir_file="$time_year_month_day.dir.xls"
over_due_name='_overdue'
> $other_storage_cache$dir_file
> $other_storage_cache$libproj
> $other_storage_cache$other_file
over_due_xx1
add_over_date
delete_old
delete_no_exists
fi
if [ $1 == "create" ] && [[ $2 =~ [0-9] ]] ;then
over_due_name='_overdue'
cycle=$2
time_year_month_day=`date -d -$cycle\day +'%Y-%m-%d'`
echo $time_year_month_day
libproj="able_lib.xls"
libproj_location="able.$time_year_month_day.lib.xls "
overall="$time_year_month_day.ProjInfo.XJpath.xls"
other_file="$time_year_month_day.other.xls"
ntime=`date +%s`
overall_XX
fi
补充获取信息获取
#!/bin/bash
#!/bin/bash
project_dir='/test/data/xjscan/'
library_file='project_library.xls'
lms_dir_01='/home/xxx/xxx/'
lms_dir_02='/home/xxx/xxx/'
> $project_dir$library_file
for i in `ls $lms_dir_02[0-9][0-9][0-9][0-9].[0-9][0-9]`;do
awk -F '\t' -v OFS='\t' '{gsub(/;/,"-",$13)}{gsub(/;/,"-",$12)}{print $20"/"$10,$12,$13,$1,$24,$3,$22,$23,$4,$"there is over days num" }' $i &>> $project_dir$library_file
done
for j in `ls $lms_dir_01[0-9][0-9][0-9][0-9].[0-9][0-9]`;do
awk -F '\t' -v OFS='\t' '{gsub(/;/,"-",$13)}{gsub(/;/,"-",$12)}{print $20"/"$10,$12,$13,$1,$24,$3,$22,$23,$4,$"there is over days num" }' $j &>> $project_dir$library_file
done
各报表生成脚本
截止目前为止,数据扫描、数据合并、数据分离、数据分析、生成文档报表等模块已完成;
下面实现的,是使用python生成web页面表格、excel表格、vlookup数据透视(任务推进)
各项表格的生成包涵以下内容
概况 : 部门-属组-集群管理人员 信息分析人员 涉及数据量 平均超期天数;
总体情况: 包涵部门名称 部门编号 运营 信息分析人员 项目编号 涉及数据量 项目名称 等信息;
未匹配到相关负责任人的数据:包涵 部门编号和数据量信息;
详情页 即所有目录条录与之对应的人员 部门 编号 数据量 超期天数等相关信息。
web页面表格生成
生成web页面形势的表格最后可以发送nginx httpd 等相关服务器的uri路径;
使用WebStackPage开源javascript静态页url路径调用至同步生成的数据表格静态页;
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
import os
import datetime
import sys
import pandas as pd
import html
report_dir = "./report/"
cycle=float(sys.argv[1])
time_year_month_day = str(datetime.date.today()-datetime.timedelta(days=cycle))
def proj_xls_to_html(file_path,sheet_name,save_name,table_title):
lst1 = []
with open(file_path) as f:
data = f.readlines()
for d in data:
value = d.split('\t')
value[-1] = value[-1].replace('\n','')
try:
value[5]=float(value[5])
except:
pass
lst1.append(value)
pd.set_option('display.width', 1000)
pd.set_option('colheader_justify', 'center')
frame = pd.DataFrame(lst1,index=None,columns=table_title)
frame = pd.DataFrame(frame)
#print(frame['超期天数'])
frame['超期天数'] = frame['超期天数'].map(lambda x: f'<font color="red">{x}<font>' if float(x) >= 44 else x)
pd.set_option('colheader_justify', 'center') # FOR TABLE <th>
html_string = '''
<html>
<head>
<title>####</title>
<link rel="stylesheet" type="text/css" href="gs_style.css"/>
<script type="text/javascript" src="jquery.min.js"></script>
<style>
.df tbody tr:last-child { background-color: #FF0000;}
</style>
<body>
<p align="center"> <br><input id="myInput" name="myInput"> <span class="search"> 搜索 </span> <br> </p>
<div>
<canvas width="1777" height="841" style="position: fixed; left: 0px; top: 0px; z-index: 2147483647; pointer-events: none;"></canvas>
<script src="maodian.js"></script>
<canvas width="1390" height="797" style="position: fixed; left: 0px; top: 0px; z-index: 2147483647; pointer-events: none;"></canvas>
##table##
</div>
<script>
$(function() {
$('.search').on('click', function() {
// console.log($('#myInput').val());
$('table tbody tr').hide()
.filter(":contains('" + ($('#myInput').val()) + "')")
.show();
})
})
</script>
</body>
</html>
'''.replace('####',sheet_name)
with open(save_name, 'w') as f:
f.write(html.unescape(html_string.replace("##table##",frame.to_html(classes='mystyle',table_id='mytable'))))
def proj_xls2_to_html(file_path,sheet_name,save_name,table_title):
lst1 = []
with open(file_path) as f:
data = f.readlines()
for d in data:
value = d.split('\t')
value[-1] = value[-1].replace('\n','')
value = value[0:-1]
try:
value[5]=float(value[5])
except:
pass
lst1.append(value)
pd.set_option('display.width', 1000)
pd.set_option('colheader_justify', 'center')
frame = pd.DataFrame(lst1,index=None,columns=table_title)
frame = pd.DataFrame(frame)
#print(frame['超期天数'])
pd.set_option('colheader_justify', 'center') # FOR TABLE <th>
html_string = '''
<html>
<head>
<title>####</title>
<link rel="stylesheet" type="text/css" href="gs_style.css"/>
<script type="text/javascript" src="jquery.min.js"></script>
<style>
.df tbody tr:last-child { background-color: #FF0000;}
</style>
<body>
<p align="center"> <br><input id="myInput" name="myInput"> <span class="search"> 搜索 </span> <br> </p>
<div>
<canvas width="1777" height="841" style="position: fixed; left: 0px; top: 0px; z-index: 2147483647; pointer-events: none;"></canvas>
<script src="maodian.js"></script>
<canvas width="1390" height="797" style="position: fixed; left: 0px; top: 0px; z-index: 2147483647; pointer-events: none;"></canvas>
##table##
</div>
<script>
$(function() {
$('.search').on('click', function() {
// console.log($('#myInput').val());
$('table tbody tr').hide()
.filter(":contains('" + ($('#myInput').val()) + "')")
.show();
})
})
</script>
</body>
</html>
'''.replace('####',sheet_name)
with open(save_name, 'w') as f:
f.write(html.unescape(html_string.replace("##table##",frame.to_html(classes='mystyle',table_id='mytable'))))
def projother_xls_to_html(file_path,sheet_name,save_name,table_title):
lst1 = []
with open(file_path) as f:
data = f.readlines()
for d in data:
value = d.split('\t')
value[-1] = value[-1].replace('\n','')
try:
value[5]=float(value[5])
except:
pass
lst1.append(value)
pd.set_option('display.width', 1000)
pd.set_option('colheader_justify', 'center')
frame = pd.DataFrame(lst1,index=None,columns=table_title)
frame = pd.DataFrame(frame)
pd.set_option('colheader_justify', 'center') # FOR TABLE <th>
html_string = '''
<html>
<head>
<title>####</title>
<link rel="stylesheet" type="text/css" href="gs_style.css"/>
<script type="text/javascript" src="jquery.min.js"></script>
<style>
.df tbody tr:last-child { background-color: #FF0000;}
</style>
<body>
<p align="center"> <br><input id="myInput" name="myInput"> <span class="search"> 搜索 </span> <br> </p>
<div>
<canvas width="1777" height="841" style="position: fixed; left: 0px; top: 0px; z-index: 2147483647; pointer-events: none;"></canvas>
<script src="maodian.js"></script>
<canvas width="1390" height="797" style="position: fixed; left: 0px; top: 0px; z-index: 2147483647; pointer-events: none;"></canvas>
##table##
</div>
<script>
$(function() {
$('.search').on('click', function() {
// console.log($('#myInput').val());
$('table tbody tr').hide()
.filter(":contains('" + ($('#myInput').val()) + "')")
.show();
})
})
</script>
</body>
</html>
'''.replace('####',sheet_name)
with open(save_name, 'w') as f:
f.write(html.unescape(html_string.replace("##table##",frame.to_html(classes='mystyle',table_id='mytable'))))
def proj_ztxls_to_html(file_path,sheet_name,save_name,table_title):
lst1 = []
with open(file_path) as f:
data = f.readlines()
for d in data:
value = d.split('\t')
value[-1] = value[-1].replace('\n','')
try:
value[5]=float(value[5])
except:
pass
lst1.append(value)
pd.set_option('display.width', 1000)
pd.set_option('colheader_justify', 'center')
frame = pd.DataFrame(lst1,index=None,columns=table_title)
frame = pd.DataFrame(frame)
pd.set_option('colheader_justify', 'center') # FOR TABLE <th>
html_string = '''
<html>
<head>
<title>####</title>
<link rel="stylesheet" type="text/css" href="gs_style.css"/>
<script type="text/javascript" src="jquery.min.js"></script>
<style>
.df tbody tr:last-child { background-color: #FF0000;}
</style>
<body>
<p align="center"> <br><input id="myInput" name="myInput"> <span class="search"> 搜索 </span> <br> </p>
<div>
<canvas width="1777" height="841" style="position: fixed; left: 0px; top: 0px; z-index: 2147483647; pointer-events: none;"></canvas>
<script src="maodian.js"></script>
<canvas width="1390" height="797" style="position: fixed; left: 0px; top: 0px; z-index: 2147483647; pointer-events: none;"></canvas>
##table##
</div>
<script>
$(function() {
$('.search').on('click', function() {
// console.log($('#myInput').val());
$('table tbody tr').hide()
.filter(":contains('" + ($('#myInput').val()) + "')")
.show();
})
})
</script>
</body>
</html>
'''.replace('####',sheet_name)
with open(save_name, 'w') as f:
f.write(html.unescape(html_string.replace("##table##",frame.to_html(classes='mystyle',table_id='mytable'))))
def crate_shuju_toushi(file_path,sheet_name2,index_name,values_name,
department_name,new_department_name,personnel_name,table_title,values_name_over,over_name):
f = pd.read_table(file_path,sep='\t',header=None)
f.columns=table_title
res = pd.pivot_table(f, index=[index_name], values=[values_name, values_name_over],
aggfunc={values_name: np.sum, values_name_over: np.mean}, margins=True)
all_xinxi_title = list(zip(list((res.index)), list(res[values_name]),list(res[values_name_over])))
# print(all_xinxi_title)
department_personnel = list(zip(f[department_name], f[index_name],f[values_name_over]))
department_personnel_size_list = []
#
#
for user in all_xinxi_title:
for department_personnel_list in department_personnel:
if user[0] in department_personnel_list:
if user[0] == '-':
continue
if user[0] == ' ':
continue
department_personnel_size_list.append((department_personnel_list[0],user[0],user[1],user[2]))
end_department_personnel_size_list = sorted(list(set(department_personnel_size_list)), key=lambda x:x[2] ,reverse=True)
all_xinxi_title_end = all_xinxi_title[-1]
all_xinxi_title_end = list(all_xinxi_title_end)
all_xinxi_title_end.insert(0,'')
end_department_personnel_size_list.append(all_xinxi_title_end)
#end_department_personnel_size_list.insert(0,[new_department_name,personnel_name,values_name])
end_department_personnel_size_list.pop()
input_list=[]
user_volue = []
for user2 in end_department_personnel_size_list:
user2 = list(user2)
if user2[1] == user_volue:
continue
user_volue = user2[1]
input_list.append(user2)
sum_list = np.array(input_list)
all_size = sum(list(map(float,sum_list[:,-2][:])))
input_list.append([" ","ALL size",all_size])
pd.set_option('display.width', 1000)
pd.set_option('colheader_justify', 'center')
#frame = pd.DataFrame(input_list,index=None)
frame = pd.DataFrame(input_list,columns=[new_department_name,personnel_name,values_name,over_name])
pd.set_option('colheader_justify', 'center') # FOR TABLE <th>
html_string = '''
<html>
<head>
<title>####</title>
<link rel="stylesheet" type="text/css" href="gs_style.css"/>
<script type="text/javascript" src="jquery.min.js"></script>
<style>
.df tbody tr:last-child { background-color: #FF0000;}
</style>
<body>
<p align="center"> <br><input id="myInput" name="myInput"> <span class="search"> 搜索 </span> <br> </p>
<div>
<canvas width="1777" height="841" style="position: fixed; left: 0px; top: 0px; z-index: 2147483647; pointer-events: none;"></canvas>
<script src="maodian.js"></script>
<canvas width="1390" height="797" style="position: fixed; left: 0px; top: 0px; z-index: 2147483647; pointer-events: none;"></canvas>
##table##
</div>
<script>
$(function() {
$('.search').on('click', function() {
// console.log($('#myInput').val());
$('table tbody tr').hide()
.filter(":contains('" + ($('#myInput').val()) + "')")
.show();
})
})
</script>
</body>
</html>
'''.replace('####',sheet_name2)
with open(save_name, 'w') as f:
f.write(html.unescape(html_string.replace("##table##",frame.to_html(classes='mystyle',table_id='mytable'))))
def create_space_toushi(save_name,sheet_name2,department_num,
sum_name,data_total,index_name,values_name,
file_path,table_title,values_name_over,over_name):
f = pd.read_table(file_path,sep='\t',header=None,dtype={'业务部门利润编号':str})
f.columns = table_title
res = pd.pivot_table(f, index=index_name, values=[values_name,values_name_over], aggfunc={values_name:np.sum,values_name_over:np.mean},margins=True)
all_list = list(zip(list(res.index), list(res[values_name]),list(res[values_name_over])))
space_list = []
for user in all_list:
user2 = list(user)[1]
user4 = list(user)[2]
user3 = list(list(user)[0])
if user3[0] == '-':
space_list.append((user3[1],user2,user4))
if user3[0] == ' ':
space_list.append((user3[1],user2,user4))
sum_list = []
space_data = pd.DataFrame(space_list)
space_data_group = space_data.groupby([0]).agg({[1][0]:'sum',[2][0]:'mean'})
space_list_list = list(zip(space_data_group.index.tolist(), space_data_group.values.tolist()))
space_list = []
for space in space_list_list:
print(space)
space_index_value = space[0], space[1][0], space[1][1]
space_list.append(space_index_value)
for slist in space_list:
sum_list.append(slist[1])
sum_list=sum(sum_list)
sort_space_list = sorted(list(set(space_list)), key=lambda x:x[1] ,reverse=True)
sort_space_list.append((sum_name, sum_list))
#sort_space_list.insert(0,(department_num,data_total))
pd.set_option('display.width', 1000)
pd.set_option('colheader_justify', 'center')
frame = pd.DataFrame(sort_space_list,index=None,columns=[department_num,data_total,over_name])
#frame = pd.DataFrame(sort_space_list,index=None)
#frame = pd.DataFrame(frame)
pd.set_option('colheader_justify', 'center') # FOR TABLE <th>
html_string = '''
<html>
<head>
<title>####</title>
<link rel="stylesheet" type="text/css" href="gs_style.css"/>
<script type="text/javascript" src="jquery.min.js"></script>
<style>
.df tbody tr:last-child { background-color: #FF0000;}
</style>
<body>
<p align="center"> <br><input id="myInput" name="myInput"> <span class="search"> 搜索 </span> <br> </p>
<div>
<canvas width="1777" height="841" style="position: fixed; left: 0px; top: 0px; z-index: 2147483647; pointer-events: none;"></canvas>
<script src="maodian.js"></script>
<canvas width="1390" height="797" style="position: fixed; left: 0px; top: 0px; z-index: 2147483647; pointer-events: none;"></canvas>
##table##
</div>
<script>
$(function() {
$('.search').on('click', function() {
// console.log($('#myInput').val());
$('table tbody tr').hide()
.filter(":contains('" + ($('#myInput').val()) + "')")
.show();
})
})
</script>
</body>
</html>
'''.replace('####',sheet_name2)
with open(save_name, 'w') as f:
f.write(html.unescape(html_string.replace("##table##",frame.to_html(classes='mystyle',table_id='mytable'))))
# for all_space_list in sort_space_list:
# sheet.append(all_space_list)
# wb.save(save_name)
if __name__=='__main__':
sheet_name = '详情'
save_name = report_dir + 'XX-XJ-DATASHOW-' + sheet_name + '.html'
file_path = report_dir + 'able.' + time_year_month_day +'.lib.xls'
table_title = ['数据大小B','文件生成时间','部门编号',
'文件属主','项目目录','文库编号','所属组','超期天数',
'项目编号', '运营经理', '信息分析', '项目名称','分期号']
proj_xls_to_html(file_path=file_path,
sheet_name=sheet_name,
table_title=table_title,
save_name=save_name)
sheet_name2 = '概况'
file_path = report_dir + time_year_month_day + '.ProjInfo.XJpath.xls'
save_name = report_dir + 'XX-XJ-DATASHOW-' + sheet_name2 + '.html'
table_title = ['业务部门名称','业务部门XX编号',
'运营经理','信息分析','项目编号',
'涉及数据量大小(G)','项目平均超期(天)','项目名称','文库编号',]
index_name = '信息分析'
values_name = '涉及数据量大小(G)'
department_name = '业务部门名称'
new_department_name = '部门'
personnel_name = '人员'
values_name_over = '项目平均超期(天)'
over_name = '总体平均超期(天)'
crate_shuju_toushi(
sheet_name2=sheet_name2,
index_name=index_name,
values_name=values_name,
department_name=department_name,
new_department_name=new_department_name,
file_path = file_path,
personnel_name=personnel_name,
table_title=table_title,
over_name=over_name,
values_name_over=values_name_over,)
sheet_name2 = '未匹配人员数据量'
index_name = ['信息分析','业务部门XX编号']
file_path = report_dir + time_year_month_day + '.ProjInfo.XJpath.xls'
save_name = report_dir + 'XX-XJ-DATASHOW-' + sheet_name2 + '.html'
department_num = '部门编号'
data_total = '数据量(G)'
values_name = '涉及数据量大小(G)'
table_title = ['XX部门名称','XX部门利润编号',
'运营XX','XX信息分析','项目编号',
'涉及数据量大小(G)','项目平均超期(天)','项目名称','文库XX编号',]
sum_name = 'ALL'
values_name_over = '项目平均超期(天)'
over_name = '总体平均超期(天)'
create_space_toushi(index_name=index_name,
save_name=save_name,
department_num=department_num,
data_total=data_total,
file_path=file_path,
table_title=table_title,
values_name=values_name,
sheet_name2=sheet_name2,
sum_name=sum_name,
over_name=over_name,
values_name_over=values_name_over, )
sheet_name = '总体情况'
file_path = report_dir + time_year_month_day + '.ProjInfo.XJpath.xls'
save_name = report_dir + 'XX-XJ-DATASHOW-' + sheet_name + '.html'
table_title = ['XX部门名称','XX部门XX编号',
'运营XX','信息分析XX','XX项目编号',
'涉及数据量大小(G)','项目平均超期(天)','项目名称',]
proj_xls2_to_html(file_path=file_path,
sheet_name=sheet_name,
table_title=table_title,
save_name=save_name)
excel 表格生成
这个表格的生成,包涵页面中的所有数据和信息,由于详情页较大,不便上线上过滤,提供多种形势的分析与数据下载;
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import openpyxl as xl
import pandas as pd
import numpy as np
import os
import sys
import datetime
import re
from openpyxl.cell.cell import ILLEGAL_CHARACTERS_RE
report_dir = './report/'
cycle = float(sys.argv[1])
time_year_month_day = str(datetime.date.today()-datetime.timedelta(days=cycle))
def proj_xls_to_xlsx(file_path,sheet_name,save_name,tableTitle=None):
with open(file_path) as f:
data = f.readlines()
if not os.path.exists(save_name):
wb = xl.Workbook()
wb.save(save_name)
else:
wb = xl.load_workbook(save_name)
ws1 = wb.create_sheet(0)
ws1.title = sheet_name
if tableTitle != None:
for n in range(len(tableTitle)):
c = n + 1
ws1.cell(row=1, column=c).value = tableTitle[n]
for d in data:
d = ILLEGAL_CHARACTERS_RE.sub(r'', str(d))
value = d.split('\t')
try:
# print(value)
value[5]=float(value[5])
except:
pass
ws1.append(value)
wb.save(save_name)
def crate_shuju_toushi(save_name, sheet_name, sheet_name2, index_name, values_name, department_name,values_name_over,
new_department_name, personnel_name,over_name):
f = pd.read_excel(io=save_name, sheet_name=sheet_name)
res = pd.pivot_table(f, index=[index_name], values=[values_name,values_name_over], aggfunc={values_name:np.sum, values_name_over:np.mean},margins=True)
wb = xl.load_workbook(save_name)
old_title = wb.worksheets[0]
old_title.title = sheet_name2
#
all_xinxi_title = list(zip(list((res.index)), list(res[values_name]),list(res[values_name_over])))
# print(all_xinxi_title)
department_personnel = list(zip(f[department_name], f[index_name],f[values_name_over]))
# print(department_personnel)
department_personnel_size_list = []
#
for user in all_xinxi_title:
for department_personnel_list in department_personnel:
if user[0] in department_personnel_list:
if user[0] == '-':
continue
if user[0] == ' ':
continue
department_personnel_size_list.append((department_personnel_list[0], user[0], user[1],user[2]))
end_department_personnel_size_list = sorted(list(set(department_personnel_size_list)), key=lambda x: x[2],
reverse=True)
all_xinxi_title_end = all_xinxi_title[-1]
all_xinxi_title_end = list(all_xinxi_title_end)
all_xinxi_title_end.insert(0, '')
end_department_personnel_size_list.append(all_xinxi_title_end)
end_department_personnel_size_list.insert(0, [new_department_name, personnel_name, values_name,over_name])
end_department_personnel_size_list.pop()
user_volue = []
for user2 in end_department_personnel_size_list:
user2 = list(user2)
if user2[1] == user_volue:
continue
user_volue = user2[1]
old_title.append(user2)
wb.save(save_name)
def create_space_toushi(save_name, sheet_name, sheet_name2, department_num, sum_name, data_total, index_name,over_name,values_name_over,
values_name):
f = pd.read_excel(io=save_name, sheet_name=sheet_name, dtype={'业务部门利润编号': str})
res = pd.pivot_table(f, index=index_name, values=[values_name,values_name_over], aggfunc={values_name:np.sum,values_name_over:np.mean},margins=True)
all_list = list(zip(list(res.index), list(res[values_name]),list(res[values_name_over])))
wb = xl.load_workbook(save_name)
sheet = wb.create_sheet(sheet_name2)
space_list = []
for user in all_list:
user2 = list(user)[1]
user4 = list(user)[2]
user3 = list(list(user)[0])
if user3[0] == '-':
space_list.append((user3[1], user2,user4))
if user3[0] == ' ':
space_list.append((user3[1], user2,user4))
sum_list = []
space_data = pd.DataFrame(space_list)
space_data_group = space_data.groupby([0]).agg({[1][0]:'sum',[2][0]:'mean'})
space_list_list = list(zip(space_data_group.index.tolist(), space_data_group.values.tolist()))
space_list = []
for space in space_list_list:
print(space)
space_index_value = space[0], space[1][0], space[1][1]
space_list.append(space_index_value)
for slist in space_list:
print(slist)
sum_list.append(slist[1])
sum_list = sum(sum_list)
sort_space_list = sorted(list(set(space_list)), key=lambda x: x[1], reverse=True)
sort_space_list.append((sum_name, sum_list))
sort_space_list.insert(0, (department_num, data_total,over_name))
for all_space_list in sort_space_list:
print(all_space_list)
sheet.append(all_space_list)
wb.save(save_name)
if __name__=='__main__':
sheet_name = '详情'
SAVE_name = report_dir + 'XX-XJ-DATASHOW-' + time_year_month_day + '.xlsx'
save_name = report_dir + 'XX-XJ-DATASHOW-' + time_year_month_day + '.xlsx'
file_path = report_dir + 'able.' + time_year_month_day +'.lib.xls'
table_title = ['数据大小B','文件生成时间','部门编号',
'文件属主','项目目录','文库编号','所属组','超期天数',
'项目编号','运营XX','信息分析','项目名称','分期号']
proj_xls_to_xlsx(file_path=file_path,
sheet_name=sheet_name,
save_name=save_name,
tableTitle=table_title,)
sheet_name = '总体情况'
save_name = report_dir + 'XX-XJ-DATASHOW-' + time_year_month_day + '.xlsx'
file_path = report_dir + time_year_month_day + '.ProjInfo.XJpath.xls'
table_title = ['业务部门名称','业务部门利润编号',
'运营经理','信息分析','项目编号',
'涉及数据量大小(G)','项目平均超期(天)','项目名称','文库编号',]
proj_xls_to_xlsx(file_path=file_path,
sheet_name=sheet_name,
tableTitle=table_title,
save_name=save_name)
save_name = report_dir + 'XX-XJ-DATASHOW-' + time_year_month_day + '.xlsx'
sheet_name = '总体情况'
sheet_name2 = '概况'
index_name = '信息分析'
values_name = '涉及数据量大小(G)'
department_name = '业务部门名称'
new_department_name = '部门'
personnel_name = '人员'
values_name_over = '项目平均超期(天)'
over_name = '总体平均超期(天)'
crate_shuju_toushi(save_name=save_name,
sheet_name=sheet_name,
sheet_name2=sheet_name2,
index_name=index_name,
values_name=values_name,
department_name=department_name,
new_department_name=new_department_name,
personnel_name=personnel_name,
values_name_over=values_name_over,
over_name=over_name
)
index_name = ['信息分析','业务部门利润编号']
save_name = report_dir + 'XX-XJ-DATASHOW-' + time_year_month_day + '.xlsx'
sheet_name = '总体情况'
department_num = '部门编号'
data_total = '数据量(G)'
values_name = '涉及数据量大小(G)'
sheet_name2 = '未匹配人员数据量'
sum_name = 'ALL'
values_name_over = '项目平均超期(天)'
over_name = '总体平均超期(天)'
create_space_toushi(index_name=index_name,
save_name=save_name,
sheet_name=sheet_name,
department_num=department_num,
data_total=data_total,
values_name=values_name,
sheet_name2=sheet_name2,
sum_name=sum_name,
values_name_over=values_name_over,
over_name=over_name)
数据提交、删除进度把控
多表格vlookup进度分析;
有一部份变量采用主脚本的环境变量,这里不再列出;
把主脚本公示当天生成的数据拷贝过来,按删除的进度再进行二次表格生成;
id_group_file='xj_id_class'
library_file='project_library.xls'
over_due_name='_overdue'
now_time=`date +"%Y-%m"`
report_dir='./report/'
send_dir='./send/'
[ -d $now_time ] || mkdir $now_time
other_storage_dir="$now_time/other"
[ -d $other_storage_dir ] || mkdir $other_storage_dir
other_storage_data="$other_storage_dir/data/"
[ -d $other_storage_data ] || mkdir $other_storage_data
other_storage_cache="$other_storage_dir/cache/"
[ -d $other_storage_cache ] || mkdir $other_storage_cache
other_storage_shell="$other_storage_dir/shell/"
[ -d $other_storage_shell ] || mkdir $other_storage_shell
cycle="$1"
time_year_month_day=`date -d -$cycle\day +'%Y-%m-%d'`
libproj="able_lib.xls"
libproj_location="able.$time_year_month_day.lib.xls "
overall="$time_year_month_day.ProjInfo.XJpath.xls"
other_file="$time_year_month_day.other.xls"
ntime=`date +%s`
vlook_up () {
if ! [ -f $send_dir/XX-XJ-DATASHOW-$time_year_month_day-old.xlsx ] ; then
cp -a $other_storage_cache$libproj_location $send_dir
cp -a $other_storage_cache$overall $send_dir
LANG='en_US.UTF-8' && source py3_new/bin/activate && python re_create.py $cycle
mv $send_dir/XX-XJ-DATASHOW-$time_year_month_day.xlsx $send_dir/XX-XJ-DATASHOW-$time_year_month_day-old.xlsx
rm -f $send_dir$libproj_location
rm -f $send_dir$overall
fi
if [ -f $send_dir/XX-XJ-DATASHOW-$time_year_month_day\.xlsx ] ; then
rm -f $send_dir/XX-XJ-DATASHOW-$time_year_month_day\.xlsx
fi
if ! [ -f $send_dir/XX-XJ-DATASHOW-$time_year_month_day\.xlsx ] ; then
cp -a $other_storage_cache$libproj_location $send_dir
(cd $send_dir && split $libproj_location ablelib-split -l 2000)
num=0
for i in `ls $send_dir\ablelib-split*`; do
awk '{cmd="ls -A " $5 " 2> /dev/null | wc -w"}{cmd| getline dir;close(cmd)}{if(dir>0){print $0}}' $i &> $project_dir$send_dir\_cache$num &
num=$[$num+1]
sleep 0.5
done
awk_ps_num=`ps aux | grep 'awk' | grep 'cmd' | grep 'getline' |wc -l`
while [ $awk_ps_num -gt 1 ] ; do
sleep 10
awk_ps_num=`ps aux | grep 'awk' | grep 'cmd' | grep 'getline' |wc -l`
done
cat $send_dir\_cache* | awk -F ='\t' -v OFS='\t' '{print $1,$2,$3,$4,$5,$6,$7,$8}' &> $send_dir$libproj
rm -f $send_dir\ablelib-split*
rm -f $send_dir\_cache*
> $project_dir$send_dir$overall
awk -F '\t' -v OFS='\t' 'ARGIND==1{split($1,wenku,"/");num=length(wenku);s=wenku[num]""$5;t=wenku[num]"-"$2""$5;a[s]=$6"\t"$7"\t"$8"\t"$9;b[t]=$6"\t"$7"\t"$8"\t"$9}ARGIND==2{c=$6""$3;if(a[c]){print $0,a[c]} else if(b[c]){print $0,b[c]}}' $project_dir$library_file $project_dir$send_dir$libproj &> $project_dir$send_dir.$libproj_location
awk -F '\t' -v OFS='\t' 'ARGIND==1{split($1,wenku,"/");num=length(wenku);s=wenku[num]""$5;t=wenku[num]"-"$2""$5;a[s]=$6"\t"$7"\t"$8"\t"$9;b[t]=$6"\t"$7"\t"$8"\t"$9}ARGIND==2{c=$6""$3;if(!a[c] && ! b[c]){print $0,"-","-","-","-"}}' $project_dir$library_file $project_dir$send_dir$libproj &>> $project_dir$send_dir.$libproj_location
mv $project_dir$send_dir.$libproj_location $project_dir$send_dir$libproj_location
cat $project_dir$id_group_file | awk -F ',' -v OFS='\t' '{print $1,$2,$3,$4,$5}' &> $project_dir$send_dir.$id_group_file
awk -F '\t' -v OFS='\t' 'ARGIND==1{s=$1;a[s]=$4"-"$2"-"$3}ARGIND==2{c=$3;if(a[c]){print $0,a[c]} else {print $0,"-"}}' $project_dir$send_dir.$id_group_file $project_dir$send_dir$libproj_location | awk -F '\t' -v OFS='\t' '{print $14,$3,$6,$1,$9,$10,$11,$12,$8}' | awk -F'\t' -v OFS='\t' '{a[$1"\t"$2"\t"$6"\t"$7"\t"$8"\t"$5]+=$4;b[$1"\t"$2"\t"$6"\t"$7"\t"$8"\t"$5]=b[$1"\t"$2"\t"$6"\t"$7"\t"$8"\t"$5]$3",";c[$1"\t"$2"\t"$6"\t"$7"\t"$8"\t"$5]+=$9;d[$1"\t"$2"\t"$6"\t"$7"\t"$8"\t"$5]++}END{for (i in a)print i,a[i],c[i]/d[i],b[i]}' | sed 's/,$//g' | awk -F '\t' '{printf "%s\t%s\t%s\t%s\t%s\t%.2f\t%s\t%s\t%s\n",$1,$2,$3,$4,$6,$7/1024/1024/1024,$8,$5,$9}' &> $project_dir$send_dir.$overall
mv $project_dir$send_dir.$overall $project_dir$send_dir$overall
LANG='en_US.UTF-8' && source py3_new/bin/activate && python re_create.py $cycle
LANG='en_US.UTF-8' && source py3_new/bin/activate && python vlook_XXxc.py $cycle
fi
}
vlook_up
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import pandas as pd
import sys
import openpyxl as xl
import datetime
report_dir = './send/'
difference_cycle=float(sys.argv[1])
time_year_month_day = str(datetime.date.today()-datetime.timedelta(days=difference_cycle))
def add_last_excel(old_sheet,new_sheet,gaikuang):
pd01 = pd.read_excel(old_sheet,sheet_name=gaikuang,encoding='utf-8')
pd02 = pd.read_excel(new_sheet,sheet_name=gaikuang,encoding='utf-8')
pd11 = pd.read_excel(old_sheet,sheet_name='未匹配人员数据量',encoding='utf-8')
pd12 = pd.read_excel(new_sheet,sheet_name='未匹配人员数据量',encoding='utf-8')
result = pd.merge(pd01,pd02[['人员','涉及数据量大小(G)']],on='人员')
result_list = list(zip(list((result['部门'])),list((result['人员'])),list((result['涉及数据量大小(G)_x'])),list((result['涉及数据量大小(G)_y']))))
not_match = pd.merge(pd11,pd12[['部门编号','数据量(G)']],left_on='部门编号',right_on='部门编号')
print(not_match)
not_match_list = list(zip(list((not_match['部门编号'])),list((not_match['数据量(G)_x'])),list((not_match['数据量(G)_y']))))
wb2 = xl.load_workbook(new_sheet)
remove_sheet1 = wb2[gaikuang]
remove_sheet2 = wb2['未匹配人员数据量']
wb2.remove(remove_sheet1)
wb2.remove(remove_sheet2)
wb2.save(new_sheet)
wb2 = xl.load_workbook(new_sheet)
sheet21 = wb2.create_sheet(gaikuang,0)
sheet22 = wb2.create_sheet('未匹配人员数据量')
result_head = ['部门','人员','涉及数据量(G)','第二次涉及数据量(G)','任务额差']
result_list.insert(0,result_head)
result_for_num = 1
for i in result_list:
result_i = list(i)
if result_for_num != 1:
result_chae=i[2]-i[3]-i[2]*0.2
result_i.append(float('%.2f'% result_chae))
result_for_num = result_for_num + 1
sheet21.append(result_i)
not_match_head = ['部门编号','数据量(G)','第二次数据量(G)','任务额差']
not_match_list.insert(0,not_match_head)
not_match_for_num = 1
for j in not_match_list:
not_match_j = list(j)
if not_match_for_num != 1:
not_match_chae=j[1]-j[2]-j[1]*0.2
not_match_j.append(float('%.2f'% not_match_chae))
not_match_for_num = not_match_for_num + 1
sheet22.append(not_match_j)
wb2.save(new_sheet)
if __name__ == '__main__':
old_sheet=report_dir + 'XX-XJ-DATASHOW-' + time_year_month_day + '-old.xlsx'
new_sheet=report_dir + 'XX-XJ-DATASHOW-' + time_year_month_day + '.xlsx'
gaikuang='概况'
add_last_excel(old_sheet=old_sheet,new_sheet=new_sheet,gaikuang=gaikuang)
到此为止,主要核心部分已经完成;
这里这只是测试的形势列出了一个存储、一个地区的形势,按生产环境时的需求可以多地部署,多存储扫描。
下面呢,可以定义定时投递扫描盘,screen 中加入执行更新自动化
定义每月投递扫盘
定义每月投递扫盘,并记录执行日志
# crontab -e
47 15 26,14,1 * * cd /test/data/xjscan && bash -x xjsan_other.sh delivery &> /test/data/xjscan/logfile
定义整合数据分析脚本、自动结果同步;
#!/bin/bash
id_group_file='xj_id_class'
library_file='project_library.xls'
over_due_name='_overdue'
now_time=`date +"%Y-%m"`
report_dir='./report/'
[ -d $now_time ] || mkdir $now_time
other_storage_dir="$now_time/other"
[ -d $other_storage_dir ] || mkdir $other_storage_dir
other_storage_data="$other_storage_dir/data/"
[ -d $other_storage_data ] || mkdir $other_storage_data
other_storage_cache="$other_storage_dir/cache/"
[ -d $other_storage_cache ] || mkdir $other_storage_cache
other_storage_shell="$other_storage_dir/shell/"
[ -d $other_storage_shell ] || mkdir $other_storage_shell
cycle="# "there is over days num""
time_year_month_day=`date -d -$cycle\day +'%Y-%m-%d'`
libproj="able_lib.xls"
libproj_location="able.$time_year_month_day.lib.xls "
overall="$time_year_month_day.ProjInfo.XJpath.xls"
other_file="$time_year_month_day.other.xls"
ntime=`date +%s`
cd $project_dir && bash -x xjsan_other.sh $cycle 100000 &> real_time.log
cd $project_dir && bash -x xjsan_other.sh create $cycle &>> real_time.log
sleep 5
cd $project_dir && cp -a $other_storage_cache$libproj_location $report_dir &>> real_time.log
cd $project_dir && cp -a $other_storage_cache$overall $report_dir &>> real_time.log
cd $project_dir && cp -a $other_storage_cache$libproj_location $xiangqing_cache &>> real_time.log
LANG='en_US.UTF-8' && source py3_new/bin/activate && python html_create.py $cycle &>> real_time.log
LANG='en_US.UTF-8' && source py3_new/bin/activate && python create.py $cycle &>> real_time.log
ssh root@xx.xx.xx.10 "sed -i "s/XX-XJ-DATASHOW-20.*xlsx/XX-XJ-DATASHOW-$time_year_month_day.xlsx/g" /var/www/html/public/index.html" &>> real_time.log
scp $report_dir\XX-XJ-DATASHOW* root@xx.xx.xx.10:/var/www/html/public &>> real_time.log
cycle=""there is over days num" "
time_year_month_day=`date -d -$cycle\day +'%Y-%m-%d'`
libproj="able_lib.xls"
libproj_location="able.$time_year_month_day.lib.xls "
overall="$time_year_month_day.ProjInfo.XJpath.xls"
other_file="$time_year_month_day.other.xls"
ntime=`date +%s`
cd $project_dir && bash -x xjsan_other.sh $cycle "there is over days num" &> real_time.log
cd $project_dir && bash -x xjsan_other.sh create $cycle &>> real_time.log
sleep 5
cd $project_dir && cp -a $other_storage_cache$libproj_location $report_dir &>> real_time.log
cd $project_dir && cp -a $other_storage_cache$overall $report_dir &>> real_time.log
LANG='en_US.UTF-8' && source py3_new/bin/activate && python add_7days_create.py $cycle &>> real_time.log
scp $report_dir\XX-XJ-DATASHOW* root@xx.xx.xx.10:/var/www/html/public &>> real_time.log
update_time=`date +"%Y年%m月%d日%H时%M分"`
ssh root@xx.xx.xx.10 "sed -i "s/##.*##/##$update_time##/g" /var/www/html/public/index.html" &>> real_time.log
ssh root@xx.xx.xx.10 "sed -i "s/XX-XJ-DATASHOW-INTERVAL-.*xlsx/XX-XJ-DATASHOW-INTERVAL-$time_year_month_day.xlsx/g" /var/www/html/public/index.html" &>> real_time.log
cd $project_dir && rm -f $report_dir*xls &>> real_time.log
cd $project_dir && rm -f $report_dir\XX-XJ-DATASHOW* &>> real_time.log
找一台计算性质的节点,进行后台运算与结果同步
运算置入会话后台
# screen -S xjscan
# while sleep 1 ; do bash -x run_create.sh ; done
# ctrl + a,d #置入后台
WebStackPage开源地址与链接修改
web页面部署到httpd或(nginx)环境后修改链接地址与公示提示信息内容即可;
因这里结果涉及部门信息不再展示。
补充awk 统计相关
一条命令分类标签、并相加、标签对应的目录个数
格试如下
254522 oss://gentype-hz/hangzhou_project/xxx.depth.stat.xls “nj_project” “1”
对应size dir tags tag_num
实现功能: tags与 tag_num 列对应的位置相同,则size相加,统计目录个数,最后一列是各个目录明细用,号分隔
awk '{b[$3" "$4]=a[$3" "$4]++?b[$3" "$4]","$2:$2;c[$3" "$4]+=$1}END{for(i in b){if(a[i]>1)print i,a[i],c[i],b[i]}}'
最后输出tags tags_num dir_num size_sum dir_detail,dir_detail,dir_detail…
过滤超期的进程并清除
过滤超期的一样名称的进程 ,未自动消毁的,保留30天的周期的进程,并将以往的销毁
进程名以contabServertest 为例,天数以30天为例
ps axo pid,etimes,command | grep ' crontabServertest' | awk '{if($2>2592000) print $1}' | xargs -I {} kill -9 {}
20240429补充统计
- kubernetes container计算节点未正在使用有镜像统计;
- 可以投递一条命令直接抓取该差异信息,为智能运维助分析数据告警自恢复做铺垫。
awk 'BEGIN{ "crictl ps -a &> /tmp/crictl-cache-ps.txt" | getline; close("crictl ps -a &> /tmp/crictl-cache-ps.txt"); "crictl images --no-trunc &> /tmp/crictl-cache-images.txt" | getline; close("crictl images --no-trunc &> /tmp/crictl-cache-images.txt") } ARGIND==1{s=$2;a[$2]=$3"-"$4}ARGIND==2{split($3,imid,":");num=length(imid);iimid=imid[num];c=substr(iimid,1,13);if(!a[c]){print $0}}' /tmp/crictl-cache-ps.txt /tmp/crictl-cache-images.txt
20240625补充统计
- pre 和 pro 统计下来的两张表格做合并一列,并生成配置项
awk -F '\t' 'ARGIND==1{s=$5;a[s]="pre\t"$7"\t"$19}ARGIND==2{c=$5;if(a[c]){print $2"\t"$3"\t"$5"\tpro\t"$7"\t"$13"\t"a[c]}else{print $2"\t"$3"\t"$5"\tpro\t"$7"\t"$13"\tpre\t"$7"\t"$13}}' pre.txt prod.txt | awk -F '\t' -v OFS='\t' '{ printf "%s\tcpu: {{if eq .Env.FLOW_DIST_ENV \"pre\"}}\"%sm\"{{else}}\"%sm\"{{end}}\t memory: {{if eq .Env.FLOW_DIST_ENV \"pre\"}}\"%dMi\"{{else}}\"%dMi\"{{end}}\n", $0, $9, $6, $8, $5 }' &> all.txt
# 补Pre差集
awk -F '\t' 'ARGIND==1{s=$5;a[s]="pre\t"$7"\t"$13}ARGIND==2{c=$5;if(!a[c]){print $2"\t"$3"\t"$5"\tpro\t"$7"\t"$19"\tpre\t"$7"\t"$19}}' prod.txt pre.txt | awk -F '\t' -v OFS='\t' '{ printf "%s\tcpu: {{if eq .Env.FLOW_DIST_ENV \"pre\"}}\"%sm\"{{else}}\"%sm\"{{end}}\t memory: {{if eq .Env.FLOW_DIST_ENV \"pre\"}}\"%dMi\"{{else}}\"%dMi\"{{end}}\n", $0, $9, $6, $8, $5 }' &>> all.txt
- 为了加深理解和记还是补充一下详解
这两条命令使用 awk 和重定向操作从两个文件(pre.txt 和prod.txt)读取数据,处理数据并将结果保存到 all.txt 文件中。为了详细理解每个命令,我们需要分解并解释每个部分的作用。
第一条命令
awk -F '\t' 'ARGIND==1{s=$5;a[s]="pre\t"$7"\t"$19}ARGIND==2{c=$5;if(a[c]){print $2"\t"$3"\t"$5"\tpro\t"$7"\t"$13"\t"a[c]}else{print $2"\t"$3"\t"$5"\tpro\t"$7"\t"$13"\tpre\t"$7"\t"$13}}' pre.txt prod.txt | awk -F '\t' -v OFS='\t' '{ printf "%s\tcpu: {{if eq .Env.FLOW_DIST_ENV \"pre\"}}\"%sm\"{{else}}\"%sm\"{{end}}\t memory: {{if eq .Env.FLOW_DIST_ENV \"pre\"}}\"%dMi\"{{else}}\"%dMi\"{{end}}\n", $0, $9, $6, $8, $5 }' &> all.txt
第一部分
awk -F '\t' 'ARGIND==1{s=$5;a[s]="pre\t"$7"\t"$19}ARGIND==2{c=$5;if(a[c]){print $2"\t"$3"\t"$5"\tpro\t"$7"\t"$13"\t"a[c]}else{print $2"\t"$3"\t"$5"\tpro\t"$7"\t"$13"\tpre\t"$7"\t"$13}}' pre.txt prod.txt
-F '\t':指定输入字段分隔符为制表符(Tab)。ARGIND==1:当处理第一个文件pre.txt时执行以下操作:s=$5:将第5列的值存储在变量 s 中。a[s]="pre\t"$7"\t"$19:在数组 a 中,以 s 为键,存储值 pre、第7列和第19列,用制表符分隔。ARGIND==2:当处理第二个文件prod.txt时执行以下操作:c=$5:将第5列的值存储在变量 c 中。if(a[c]){print ...}:如果数组 a 中存在键 c,则打印以下内容:$2"\t"$3"\t"$5"\tpro\t"$7"\t"$13"\t"a[c]else{print ...}:如果数组 a 中不存在键 c,则打印以下内容:$2"\t"$3"\t"$5"\tpro\t"$7"\t"$13"\tpre\t"$7"\t"$13
第二部分
awk -F '\t' -v OFS='\t' '{ printf "%s\tcpu: {{if eq .Env.FLOW_DIST_ENV \"pre\"}}\"%sm\"{{else}}\"%sm\"{{end}}\t memory: {{if eq .Env.FLOW_DIST_ENV \"pre\"}}\"%dMi\"{{else}}\"%dMi\"{{end}}\n", $0, $9, $6, $8, $5 }' &> all.txt
-F '\t':指定输入字段分隔符为制表符(Tab)。-v OFS='\t':指定输出字段分隔符为制表符(Tab)。{ printf ... }:格式化打印每行,使用模板字符串:%s:当前行的完整内容 $0cpu: {{if eq .Env.FLOW_DIST_ENV \"pre\"}}\"%sm\"{{else}}\"%sm\"{{end}}:条件语句模板,插入第9列和第6列的值。memory: {{if eq .Env.FLOW_DIST_ENV \"pre\"}}\"%dMi\"{{else}}\"%dMi\"{{end}}:条件语句模板,插入第8列和第5列的值。&> all.txt:将输出重定向到文件 all.txt,覆盖现有内容。
第二条命令
awk -F '\t' 'ARGIND==1{s=$5;a[s]="pre\t"$7\t"$13}ARGIND==2{c=$5;if(!a[c]){print $2"\t"$3"\t"$5"\tpro\t"$7"\t"$19"\tpre\t"$7"\t"$19}}' prod.txt pre.txt | awk -F '\t' -v OFS='\t' '{ printf "%s\tcpu: {{if eq .Env.FLOW_DIST_ENV \"pre\"}}\"%sm\"{{else}}\"%sm\"{{end}}\t memory: {{if eq .Env.FLOW_DIST_ENV \"pre\"}}\"%dMi\"{{else}}\"%dMi\"{{end}}\n", $0, $9, $6, $8, $5 }' &>> all.txt
第一部分
awk -F '\t' 'ARGIND==1{s=$5;a[s]="pre\t"$7"\t"$13}ARGIND==2{c=$5;if(!a[c]){print $2"\t"$3"\t"$5"\tpro\t"$7"\t"$19"\tpre\t"$7"\t"$19}}' prod.txt pre.txt
-F '\t':指定输入字段分隔符为制表符(Tab)。ARGIND==1:当处理第一个文件 prod.txt 时执行以下操作:s=$5:将第5列的值存储在变量 s 中。a[s]="pre\t"$7"\t"$13:在数组 a 中,以 s 为键,存储值 pre、第7列和第13列,用制表符分隔。ARGIND==2:当处理第二个文件 pre.txt 时执行以下操作:c=$5:将第5列的值存储在变量 c 中。if(!a[c]){print ...}:如果数组 a 中不存在键 c,则打印以下内容:$2"\t"$3"\t"$5"\tpro\t"$7"\t"$19"\tpre\t"$7"\t"$19
第二部分
awk -F '\t' -v OFS='\t' '{ printf "%s\tcpu: {{if eq .Env.FLOW_DIST_ENV \"pre\"}}\"%sm\"{{else}}\"%sm\"{{end}}\t memory: {{if eq .Env.FLOW_DIST_ENV \"pre\"}}\"%dMi\"{{else}}\"%dMi\"{{end}}\n", $0, $9, $6, $8, $5 }' &>> all.txt
-F '\t':指定输入字段分隔符为制表符(Tab)。-v OFS='\t':指定输出字段分隔符为制表符(Tab)。{ printf ... }:格式化打印每行,使用模板字符串:%s:当前行的完整内容$0cpu: {{if eq .Env.FLOW_DIST_ENV \"pre\"}}\"%sm\"{{else}}\"%sm\"{{end}}:条件语句模板,插入第9列和第6列的值。memory: {{if eq .Env.FLOW_DIST_ENV \"pre\"}}\"%dMi\"{{else}}\"%dMi\"{{end}}:条件语句模板,插入第8列和第5列的值。&>> all.txt:将输出追加到文件 all.txt。
总结
这两条命令从两个文件中读取数据,合并和处理这些数据,然后将结果保存到 all.txt 文件中。每条命令的第一部分使用 awk 根据特定条件匹配和处理数据,而第二部分使用 awk 格式化输出结果并重定向到文件。
格言
主气常静,客气常动,客气先盛而后衰,主气先微而后壮


