







corosync + pacemaker 高可用集群详解
- 负载均衡,基础环境说明
- RR 轮询机制;
- WRR 加权轮询机制;
- LC 最少连接数;
- WLC 加权最少连接数;
- 源HASH; 实现类似会话保持的功能;
- 环境参考
- classroom: 提供yum源 DNS解析 路由功能等;
- workstation: IP-SAN存储;
- nodea-noded 四个集群节点;
- pacemaker 集群软件;
- corosync 集群内部通信组件;
- pcs: 命令行工具;
- pcsd: 集群后台运行的服务;
安装配置相关组件
安装相关组件
在所有的节点上安装软件包
yum install pcs fence-agents-all.x86_64 fence-agents-rht
放行高可用服务组件相关的端口
firewall-cmd --permanent --add-service=high-availability
firewall-cmd --reload
启动相关的服务组件
systemctl enable pcsd.service
systemctl start pcsd.service
创建集群
默认会建立一个用户叫 hacluster
id hacluster
修改 hacluster 用户的密码,用于集群节点之间认证,只有经过认证的计算机才能加入集群;
# passwd hacluster
# pcs cluster auth nodea.private.example.com nodeb.private.example.com
创建集群
# pcs cluster setup --start --name cluster0 nodea.private.example.com nodeb.private.example.com
# pcs cluster enable --all
# pcs status
- 两个都往一个地方写,就会导致数据不一致;
- fence机制: 隔离主机到存储的连接;
- 远程管理卡 IPMI 智能网卡管理接口;
- 华为: 智能远程管理卡接IBMC
- fennce-agents 发送指令就是发送ipmi 的指令
- IPMI 是可以ssh登录的,里面封装了IPMI 的所有指令
- fence-agent 是什么硬件就要选择什么样的agent, fence-agent 支持众多硬件的 IBMC封装包
# pcs stonith show # 列出配置
# pcs stonith list # 列出所有的支持的agent
# pcs status # 查看当前集群的配置状态信息
创建管理stonith
创建 stonith
# pcs stonith create fence_nodea fence_ilo3 ipaddr=192.168.2.100 login=Admnistrator passwd=Admin@9000
# pcs stonith create fence_nodeb fence_ilo3 ipaddr=192.168.2.200 login=Adminstrator passwd=Admin@9000
# pcs stonith show
删除 stonith
# pcs stonith delete fence_nodea
# pcs stonith delete fance_nodeb
没有fenace卡时, 实验包 fence-agents-rht ,这里rht 的意思是 redhat training ,用于这门课程学习用的
# pcs stonith describe fence_rht
# pcs stonith create fence_nodea fence_rht port="nodea" pcmk_host_list="nodea.private.example.com" ipaddr="classroom.example.com"
# pcs stonith create fence_nodeb fence_rht_port="nodeb" pcmk_host_list="nodeb.private.example.com" ipaddr="classroom.example.com"
fence机制
- fence机制: 隔离主机到存储的连接
- 如果配置 fence_xvm步骤 KVM fence 物理机器需要实真的fence设备么 ?
- 配置fence_xvm 步骤 KVM fence
配置宿主机fence
- 将物理机器(宿主机) f0配置成fence设备
- 宿主机上执行
- 安装fence设备软件包
# yum -y install fence-virtd-libvirt.x86_64 fence-virtd fence-virtd-multicast.x86_64
- 生成一个对称的密钥对
# mkdir /etc/cluster
# dd if=/dev/urandom of=/etc/cluster/fance_xvm.key bs=1k count=4
- 给f0设备的virbr1 设备对应的IP地址, 如:192.168.0.99,该IP地址必须能与nodea与nodeb的集群网络通讯
# cat /etc/libvirt/qemu/nodea.xml
<interface type='bridge'>
<mac address='52:54:00:02:00:0a'/>
<source bridge='virbr1'/> ##查看此处
<modelt type='virtio'/>
<address type='pci' domain='0x0000' bus='0x00' slot='0x05' function='0x0'/>
</interface>
# cat /etc/libvirt/qemu/networks/privnet.xml
<network ipv6='yes'>
<name>privnet</name>
<uuid>b2eb5995-3e5b-49ad-bc00-62d38a06ff4</uuid>
<bridge name='virbr1' stp='on' delay='0'/>
<mac address='52:54:00:13:83:3f'/>
<ip address='192.168.0.99' netmask='255.255.255.0'> ## 修改这几行
<dhcp> ## 注: 加上dhcp 会导致fence失败 ?? 待测试
<range start='192.168.0.31' end='192.168.0.50'> ## 收尾符要不要加/ 待测定 ??
</dhcp> ##
</ip> ##
</network>
重启kvm 后生效
# systemctl restart libvrtd.service
# systemctl restart fence_virtd.service
或者实时生效的方法
# ifconfig virbr1 192.168.0.99
- 在两个集群虚拟机node节点上分别创建 /etc/cluster 目录
# mkdir /etc/cluster
- 将 f0上面的 /etc/cluster/fence_xvm.key 密钥分别复制到集群节点的对应目录,目录和文件名必须保持一致
f0 # scp /etc/cluster/fence_xvm.key root@nodea:/etc/cluster
f0 # scp /etc/cluster/fence_xvm.key root@nodeb:/etc/cluster
- 配置f0 fence
# fence_virtd -c # 配置kvm fence
Interface[virbr0]: virbr1 # 具体要看情况,哪个物理机的虚拟网卡接口与集群进行的通信;
# systemctl enable fence_virtd && systemctl start fence_virtd
至此f0 配置完成
集群节点配置fence
- 在所有的集群节点上开启1229端口;
# firewall-cmd --permanent --add-port=1229/tcp
success
# firewall-cmd --permanent --add-port=1229/udp
success
# firewall-cmd --reload
- 创建 fence 设备(在集群任一节点做即可)
# pcs stonith create fence_nodea fence_xvm port='nodea' pcmk_host_list='nodea.private.example.com'
# pcs stonith create fence_nodeb fence_xvm port='nodeb' pcmk_host_list='nodeb.private.example.com'
# pcs stonith show
fence_nodea (stonith:fence_xvm): Started
Fence_nodeb (stonith:fence_xvm): Strated
- 查看具体的参数是怎么配置的
# pcs stonith show --full
- 测试fence
方式一 手动将fence 下线
# pcs stonith fence nodea.private.example.com
方式二 将节点宕机
# ssh root@servera
# ifdown eth1
所有的集群节点都在同一个多播域内;
正常物理机环境创建
# pcs stonith create fence_node123 fence_ilo3 ipaddr=192.168.2.100 login=Administrator passwd=Admin@9000 pcmk_host_list="nodea.private.example.com "
pcs 重启集群
# pcs cluster stop --all # 生产环境不能轻易这样操作
# pcs cluster start --all # 注,启动环境较慢
- 为了防止集群发生了切换,但没有记录日志,因此,debug 功能要开启
- HA 主备时,有一套集群会浪费资源,因此要两个节点运行两套集群服务
- 仲裁机制: 判断是否运行
- 超过两个节点的集群中,使用票数解决方案来解决脑裂
- 运算机制
total = sum/2 + 1 - 得票数必须大于一半,集群才能存活
- 当前集群得票数=SUM/2 + 1
- 超过半数以上票数,则集群存活
节点扩容
扩容 nodec,noded 到集群中
- 安装集群软件包(两个新节点)
# yum -y install pcs fence-agents-all
- 启动服务(两个节新点)
# systemctl enabled pcsd && systemctl start pcsd
- 防火墙放行规则(两个新节点)
# firewall-cmd --permanent --add-service=high-availability
# firewall-cmd --reload
- 设置hacluster 密码为redhat(两个新节点)
echo "redhat" | passwd --stdin hacluster
- 将nodec 和noded加入认证
# pcs cluster auth nodec.private.example.com noded.private.example.com
- 将 nodea 和nodeb 加入集群
# pcs cluster node add nodec.private.example.com
# pcs cluster node add noded.private.example.com
- 让节点自动加入集群
# pcs cluster enable --all
- 启动集群中当前的两个节点
# pcs cluster start nodec.private.example.com
# pcs cluster start noded.private.exmpale.com
- 给两节点配置防火墙,并添加fence
# mkdir /etc/cluster #(两个新节点执行)
# scp /etc/cluster/fence_xvm.key root@nodec:/etc/cluster #(宿主机本地执行)
# firewall-cmd --permanent --add-port=1229/tcp
# firewall-cmd --permenent --add-port=1229/udp
# firewall-cmd --reload
# pcs stonith create fence_nodec fence_xvm port="nodec" pcmk_host_list="nodec.private.example.com"
# pcs stonith create fence_noded fence_xvm port="noded" pcmk_host_list="noded.private.example.com"
- 查看加入的节点状态
# pcs status
corosync 仲裁机制
# corosync-quorumtool -m # 查看集群的状态
- 票数类型
- 期待票数
- 总票数
- 期待票数 = 总票数
- 总票数是所有存活节点票数之和 ?
- 期待票数是可以被人为修改的
- 例: 4个节点,必须有3个节点才能存活
- 一旦有一个节点故障,总票数会随着节点下线重新变更,而待待票数不会,期待票数来进行计算;
- 默认期待票数= 总票数
- 得票数 >= 期待票数/2+1 集群才能正常工作
- 两个node 排队在外,一旦节点,只有两个节点,将不会启用票数解决方案
因为2/2+1=2
一旦集群初始化完成,不管集群节点是否在线,期待票数默认不会改变
修改集群仲裁配置
# cat /etc/corosync/corosync.conf
quorum {
provider: corosync_votequorum
wait_for_all: 1
auto_tie_breaker: 1
auto_tie_breaker_node: lowest
}
# pcs cluster sync # 将配置分发给集群的其它节点;
# pcs cluster stop --all
# pcs cluster start --all
# pcs status
# cat /etc/corosync/corosync.conf
quorum {
provider: corosync_votequorum
wait_for_all: 1
auto_tie_breaker: 1
auto_tie_breaker_node: lowest
last_man_stading: 1
}
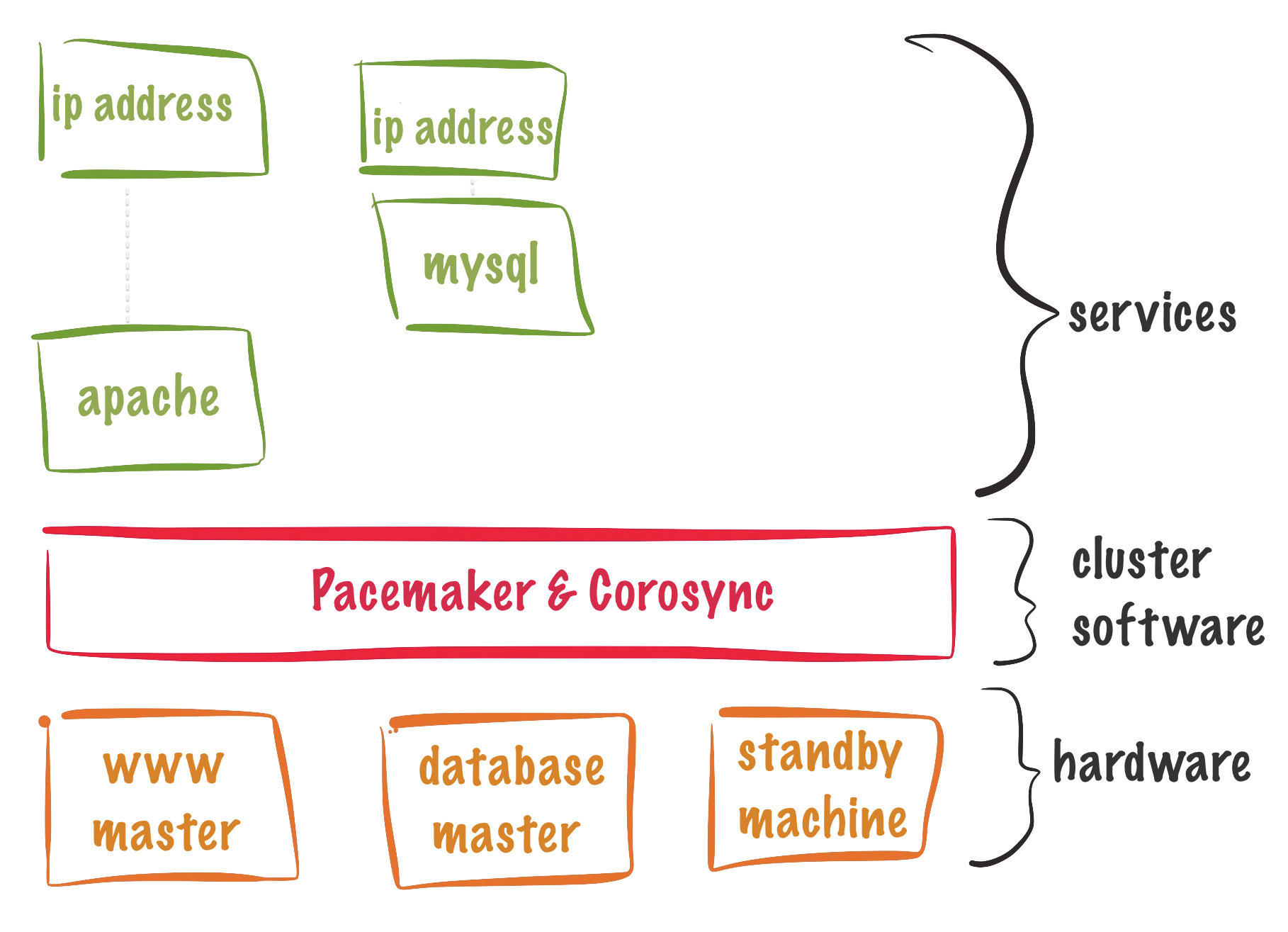
集群资源
资源组包括多个集群资源:(webgroup: vip、集群文件系统、集群服务)
集群服务是由一个或者多个集群资源组成,可以将一个集群服务用到的资源加入到同一个资源组中,一个资源组中的资源同时会运行在一个节点上
集群的资源分为三类: 1. LSB 2.OCF 3. systemd
# pcs resource list # 查看支持systemd 服务
# pcs resource descirbe IPaddr2 # 查看IPaddr2帮助配置等信息
查看resource帮助信息与创建的示例
# pcs resource create --help # 查看Example 字段可以看到帮助示例信息
# pcs resource list | grep -i filesystem
# pcs resource describe Filesystem
案例: 创建一个httpd web HA集群
- 查询集群资源
# pcs resource list
- 查询某一个资源详细信息
# psc resource describe IPaddr2
- 集群所有节点开启防火墙规则
# firewall-cmd --permanent --add-service=http
# firewall-cmd-cmd --reload
- 集群所有节点安装需要的服务软件包, 以httpd 为例
# yum -y install httpd
- 集群所有节点设置SElinux, 这里是nfs 为例
# setsebool -P httpd_use_nfs=1
- 搭建nfs 服务 在workstaion节点上
# yum -y install nfs
# vim /etc/exports.d/www.exports
/exports/www 192.168.1.0/24(ro) 192.168.2.0/24(ro)
# systemctl restart nfs
# firewall-cmd --permanent --add-service=nfs
# firewall-cmd --permanent --add-service=rpc-bind
# firewall-cmd --permanent --add-service=mountd
# firewall-cmd --reload
创建集群资源
注: cidr_netmask=24 这个参数不支持 255.255.255.x 这种格式# pcs resource create myip Ipaddr2 ip=172.25.0.99 cidr_netmask=24 --group myweb # pcs resource create myfs Filesystem device=192.168.1.9:/exports/www direcotry=/var/www fstype=nfs --group myweb # pcs resource create myservice systemd:httpd --group myweb # pcs resource show # pcs stats测试
# pcs stonith fence nodea.private.example.com
# pcs status # 查看集群服务运行在哪个节点上
- 删除资源
# pcs resource show
# pcs delete myweb # 这里可以删除整个资源组
# pcs delete myfs # 也可以删除单个资源
- 假如创建了资源忘记了加组
# pcs resource group add mygroup myresource
# pcs resource group remove mygroup myresource
创建资源组 myftp (1.vip、2.文件系统 3. 服务)
- 集群所有节点上安装
ftp 默认的目录在# yum -y insstall vsftpd # getsetbool -a | grep ftp | grep nfs # setsebool ftp_use_nfs=on/var/ftp/pub目录下面
# pcs resource create ftpvip IPaddr2 ip=172.25.0.88 cidr_netmask=24 --group myftp
# pcs resource create ftpfs Filesystem deveice=192.168.1.9:/exports/ftp directory=/var/ftp fstype=nfs --group myftp
# pcs resouce list | grep -i ftp
# pcs resource create ftp systemd:vsftpd --group myftp
# pcs resource show
# pcs status
- 集群所有节点防火墙放行ftp服务
# firewall-cmd --permanent --add-service=ftp
# firewall-cmd --permanent --reload
- 测试
# pcs stonith fence servera.private.examplte.com
# pcs status
资源的高级控制
将myfs 资源组监测action机制定义为 fence
先测试# umount /var/www # tail -f /var/log/messages可以看到默认的机制是尝试重启服务
# pcs resource update myfs op monitor on-fail=fence # pcs resource show myfs再测试
# umount /var/www # tail -f /var/log/messages修改检测机制与超时时间
注意:修改Operations 参数时,它是配套添加,就是把要修改的一次配置完,不然之前的配置会丢
# pcs resource update myfs op monitor interval=10s timeout=20s on-fail=fence
- 启停资源组
# pcs resource disable myfs
# pcs resource enable myfs
涉及相关的优先级
例: 将myweb 资源移到nodec 上, myweb 在 nodec 上的优先级会最高
# pcs resource move myweb nodec.private.example.com
将myftp 移走,那此时 ftp 的优先级在原运行的节点nodeb 上的优先级会最底
# pcs resouce move mftp
查看优先级
# pcs constraint list
清空配置的优先级规则
# pcs resource clear myftp nodeb.private.example.com
# pcs resource clear myweb nodec.private.example.com
再次查看
# pcs constraint list
驱逐服务于某节点
# pcs resource ban myweb nodea.private.example.com
# pcs resource ban myweb nodeb.private.example.com
# pcs resource ban myweb nodec.private.example.com
# pcs resource ban myweb noded.private.example.com
# pcs constraint list
# pcs status
当所有节点都驱逐某服务组时,即此服务组在所有节点上的优先级为负无穷大时服务组会自杀,即停掉
清空规则
# pcs resource clear myweb # 规则一清,服务组就会再自行启动
# pcs constraint list
# pcs status
- 手动指定指定服务指定节点的优先级
# pcs constraint location myweb perfers nodec.private.example.com=500
# pcs constraint location myweb perfers nodeb.private.example.com=400
# pcs constraint location myweb perfers nodea.private.example.com=300
# pcs constraint location myweb perfers noded.private.example.com=200
此时mweb 资源组会优先运行在nodec上
# pcs constraint location myftp perfers nodea.private.example.com=900
# pcs constraint location myftp perfers nodeb.private.example.com=800
# pcs constraint location myftp perfers nodec.priavte.example.com=700
# pcs constraint location myftp perfers noded.priavte.example.com=600
此时mwftp 资源组会优先运行在nodea 上
查看状态
# pcs constraint list
# pcs staus
当noda 停掉时,myftp服务会优先运行在 nodeb上
# pcs stonith fence nodea
# pcs status # 可以看到 myftp 会运行在 nodeb 上
过一会儿当服务自动恢复时,myftp 资源组会再次运行在nodea上
# pcs status
- 删除单条规则
# pcs constraint list --full # 查看规则
# pcs constraint remove location-myftp-nodeb.private.example.com-800
# pcs constraint remove location-myftp-nodec.private.example.com-700
# pcs constraint remove location-myftp-noded.private.example.com-600
- order 关系建立,即先启哪个服务,再启哪个服务
# pcs constraint order myfs then myservice
# pcs resource disable myweb
# pcs resouce enable myweb
一些有依赖关系的两资源一定只能运行在一个节点上
<— 后续涉及相关的技术 —>
排错、存储、多路径技术、udev规则 、 集群级逻辑卷 、 集群级文件系统、综合练习和实验
管理集群日志方便排错
- 单独定义志
# pcs resource show --full
# journalctl -u pacemaker.service -u corosync.service # 使用 journalctl 工具查看相关日志
# cd /etc/corosync/
# vim corosync.conf # 修改loggin 字段
logging {
to_syslog: yes
to_file: yes
logfile: /var/log/cluster.log
deubg: on
}
# pcs cluster sync # 同步配置到所有节点
一旦把debug 打开,日志就会非常的详细,所要做日志轮论,即日志滚动更新;
pacemaker 开启debug 并步到其余三个节点
# vim /etc/sysconfig/pacemaker # 找到 PCMK_debug,添加开启 PCMK_debug=yes # scp /etc/sysconfig/pacemaker root@nodeb:/etc/sysconfig/ # scp /etc/sysconfig/pacemaker root@nodec:/etc/sysconfig/ # scp /etc/sysconfig/pacemaker root@noded:/etc/sysconfig/开启日志轮询,同步配置到其余三个节点
# cp /etc/logrotate.d/pacemaker /etc/logrotate.d/cluster
# vim /etc/logrotate.d/cluster # 修改日志文件保存位置
/var/log/cluster.log {
compress
dateext
weekly
rotate 99
maxage 365
notifempty
missingok
copytruncate
}
# scp /etc/logrotate.d/cluster root@nodeb:/etc/logrotate.d/
# scp /etc/logrotate.d/cluster root@nodec:/etc/logrotate.d/
# scp /etc/logrotate.d/cluster root@noded:/etc/logrotate.d/
# pcs cluster stop --all
# pcs cluster start --all
打开个一个终端查看日志
# tail -f /var/log/corosync.log
将服务从节点move可以看到具体的输出日志
# pcs resource show
# pcs resource move firstweb nodeb.private.example.com
或者将节点fence掉
# pcs stonith fence nodeb.private.example.com
监控报警
发生切换或者故障时,发送邮件或者调用脚本来进行报警
# pcs resource list | grep -i mailto
# pcs resouce describe MaileTo
有些集群资源只能同时运行在一个节点上,比如浮动ip(vip),而有些资源是可以同时运行成所有节点上的
pcs resource --clone 参数,可以创建单个资源在所有的节点上
- 这个实验,因脚本需求,需要reset集群
宿主机上执行
# rht-vmctl status --all
# rht-vmctl reset workstation
# rht-vmctl reset nodea
# rht-vmctl reset nodeb
# rht-vmctl reset nodec
# rht-vmctl reset noded
- setup 集群为红帽monitor集群
# lab monitor setup
- 创建一个资源为firstweb
# pcs resource create webmail MailTo email=student@workstation.cluster0.example.com subject="CLUSTER-NOTIFICATION" --group firstweb
登录workstation
# su - student
# mail # 可以看到添启动 firstweb MailTo的脚本 第一封邮件
驱逐资源
# pcs resouce remove firstweb
登录 workstation
# su - student
# mail # 可以看到第二封第三封邮件是发生停止与重启的邮件
# pcs resource create mailme ClusterMon extra_options="-e student@workstation.cluster.example.com -E /usr/local/bin/crm_notify.sh" --clone
故障排错
- 宿主机上执行
# rht-vmctl status --all
# rht-vmctl reset workstation
# rht-vmctl reset nodea
# rht-vmctl reset nodeb
# rht-vmctl reset nodec
# rht-vmctl reset noded
- setup 集群为红帽的 resourcefailure
# lab resourcefailure setup
# pcs status # 可以看到 firstwebserver 没能启动
# pcs resource enable firstwebserver
# pcs resource show #可以看到服务还是没能启动
debug-start 可以帮助排查错误等
# pcs resource debug-start ---full # 可以看查具体的启动信息, 发现httpd 读取配置文件不存在
# pcs resource describe apache # 可以查看apache 的属性,apache 属性能可以接哪参数
# pcs resource show firstwebserver --full # 可以看到定义apache 配置文件时,配置文件所在目录名称写错了
它在配置时应该执行了一个类似这样的功能
# pcs resource create firstwebserver apache configfile=/etc/htttpd/conf/httpd.confd
- 修复
# pcs resource update firstwebserver configfile=/etc/httpd/conf/httpd.conf
# pcs resource show firstwebserver --full
# pcs resource show
# pcs status # 可以看到服务已经启动了
- 交换机有没有开启多播网络;
- 防火墙有没有开启对应的高可用与服务资源端口;
- 多个节点在不同的交换机上,网络有没有打通,否则的话出现脑裂;
- 网络出现延迟,或者丢包、不可用,也会导致集群宕掉;
存储服务
root_squash: 当客户端以root用户来访问NFS服务端时,就被映射为服务器的匿名用户
no_root_squash: 当客户端以root 用户来访问nfs服务器时,就被映射为服务器的root权限
fsid=0: 伪根, 为了安全,将 myshare 目录当作根目录来给客户端挂载
例:/myshare *(rw,sync,no_root_squash,fsid=0)
环境准备
宿主机执行
# rht-vmctl reset all
- setup 集群为红帽的nfs
# lab nfs setup
当nodea 执行fidsk /dev/sda 创建一个1G的盘时,如果 mkfs.xfs /dev/sda1
这时 nodeb nodec noded 上是可以看到sda1的,但是不生效 需要执行 partprobe 或者重启节点才会生效,在创建服务时,要确保节点是生效的
- 格式化后将所有节点的本地锁关掉
# systemctl stop nfs-lock
# systemctl disable nfs-lock
- 建立高可用nfs_server
# pcs resource create nfsshare Filesystem device=/dev/sda1 directory=/nfsshare fsypte=xfs --group nfs
# pcs resource create nfsd nfsserver nfs_share_infodir=/nfsshare/nfsinfo --group nfs
# pcs resource create nfsroot exportfs clientspec="*" options=rw,sync,no_root_squash directory=/nfsshare fsid=0 --group nfs
# pcs resource create nfsip IPaddr2 ip=172.25.0.82 cidr_netmask=24 --group nfs
- 将集群所有节点的firewall nfs服务放行
# firewall-cmd --permanent --add-service=nfs
# firewall-cmd --permanent --add-service=rpc-bind
# firewall-cmd --permanent --add-service=mountd
# firewall-cmd --reload
- 查看集群状态
# pcs status
# showmount -e 172.25.0.82
pcs constraint order A then B 服务B的启动依赖于A,但服务A停止时B也会停止;
另: order关系创建只支持两个两服务的创建
Constraints 的三个特性
Location Constraints: 决定一个资源或者资源组运行在哪个节点上—> 根据优先级;
Ordering Constraints: 决定相依赖的集群资源运行的先后关系;
Colocation Constraints: 决定两个集群资源必须运行在相同的节点;
在同一个资源组中的资源一定会运行在同一个节点;--clone没有配置资源组,资源会运行在所有的节点上。
# pcs constraint order nfsshare then nfsd
# pcs constraint order nfsd then nfsroot
# pcs constraint list --full
# pcs resource show
# pcs resource disable nfs
# pcs resource enable nfs
# pcs status
# pcs constraint list --full
# pcs constraint remove order id # 这里id是通过 pcs constraint list --full 查看到的
优先级
# pcs constraint location id perfers node=500
# pcs constraint location id avoids node # 避免运行在哪个节点上
设置默认值
# pcs resource defaults resource-stickiness=1000
# pcs resource defaults
# pcs resource defaults resource-stickiness=
运行在一个节点上
# pcs constraint colocation add nfsshare with nfsd
# pcs constraint colocation add nfs with nfsroot
两个服务一定不会运行在同一个节点上
# pcs constraint colocation add B with A -INFINITY
存储网络: 主机到存储的网络
SAN: Storage Area Network 存储区域网络
FC-SAN Fibre Channel
IP-SAN 也称之为ISCSI 将SCSI协议封装到IP的网络中进行传输
- iscsi 设备创建
在workstation 上创建
在node节点上查看InitiatorName cat /etc/iscsi/initiatorname.iscsi
# fdisk /dev/vdb # 创建vdb1 后不要格式化
# tragetcli
> /backstores/block create name=storage1 dev=/dev/vdb1 # 关联storage1
> /iscsi create inq.2021-05.com.example.storage.workstation # 创建iscsi
> /iscsi/iqn.2021-05.com.example.storage.workstation/tpg1/luns create /backstores/block/storage1 # 创建iscsi lun
> /iscsi/iqn.2021-05.com.example.storage.workstation/tpg1/acls create iqn.2015-06.com.example:nodea # 授权node访问
> /iscsi/iqn.2021-05.com.example.storage.workstation/tpg1/acls create iqn.2015-06.com.example:nodeb # 授权node访问
> saveconfig # 保存配置
# systemctl restart target.service
# netstat -tnlup | grep :3260
# firewall-cmd --permanent --add-port=3260/tcp
# firewall-cmd --reload
至此workstation 端的存储已经配好
接下来在node上配置iscsi客户端连接
- 在的有node配置iscsi客户端连接
# iscsiadm -m discovery -t st -p 192.168.1.9:3260 # 这里配置了网络的双链路,以避免单点失败
# iscsiadm -m discovery -t st -p 192.168.2.9:3260 #
# iscsiadm -m node -T iqn.2021-05.example.storage.workstation -p 192.168.1.9:3260 -l
# iscsiadm -m node -T iqn.2021-05.example.storage.workstation -p 192.168.2.9:3260 -l
# iscsiadm -m session # 可以看到当前节点有几条链路
# fdisk -l # 可以看出node节点上增加了sda这块设备
多路径会在系统层面显示两块设备(如: sda sdb)但其实是一块设备
测试 —> 在nodea 上执行
# fdisk /dev/sda
# mkfs.ex4 /dev/sda1
# mkdir /data
# mount /dev/sda1 /data
# cp -a /etc /data
# cp -a /etc/passwd /data
# sync
测试 —> 在nodeb 上执行
# fdisk -l # 可以看已经有sda1了
# ll /dev/sda1 # 但是可以看到没有这个块设备文件
# partprobe
# ll /dev/sda1 # 再看块设备文件已经存在了
# mount /dev/sda1 /data #可以看nodea 上写入的数据,这就是共享存储
在两边多次写入数据测试会发现,两边看到的数据会不致,为什么会出现这种现象呢?
格式化的文件系统是单机板的文件系统,单机版的文件没有销机制,因此无法保证数据的一致性
因此需要格式化成集群式的文件系统,有锁机制可以保证文件系统的一致性
脑裂: 导致数据不一致,或者数据损坏
OCFS2:Oracle FileSystem2 第二代
# pcs resource create myip IPaddr2 ip=172.25.0.99 cidr_netmask=24 --group mweb
# pcs resource show
# pcs resource describe Filesystem
# pcs resource create myfs Filesystem device=/dev/sda1 directory=/var/www/html fstype=ext4 --group myweb
# pcs resource list | grep httpd
# pcs resource create systemd:httpd --group web
# pcs resource show --full
- 其余节点将/data 目录取消挂载,并配置安全策略
# mount /data # 将之前测试的sda1空余出来
# firewall-cmd --permanent --add-port=80/tcp
# firewall-cmd --reload
# chcon -R httpd_sys_content_t /var/www/html
测试
# pcs resouce remove myweb
这时可以看到nodea已经不在挂载了,而漂移到了nodeb上面了
补充多路径软件
- 在存储设备上的同一个LUN, 由于主机到存储设备的有多条链路时,在主机端呈现的多个磁盘,多路径软件能够屏蔽这些磁盘
- 而生成一个虚拟的磁盘,读写操作通过虚拟的磁盘进行
- 多路径软件通常还要提供以下功能
- 路径I/O负载均衡
- 最优路径选择
- 故障切换 failover 万一有条链路故障了,下一条i/o过来会切换到另一条链路
- 故障恢复 failback 故障的链路恢复了,下一条i/o回到原有的链路
- 目前存储厂商提供的多路径方案分为三大类:
- 使用厂商自研多路径,如EMC的 PowerPath, HDS的HDLM, 华为的UltraPath;
- 直接使用操作系统自带的多路径;
- 存储厂商提供基于操作系统的自带多路径的适配插件。如IBM和HP;
- 相关算法: 轮询:RR 最少队列长度 最少服务时间(综合);
红帽的多路径软件
device-mapper-multipath
- 所有node节点上安装并配置
# yum -y install device-mapper-multipath
# mpathconf --enable --with_multipathd y # 生成配置文件
# systemctl restart mutipathd.service
# systemctl enable mutipathd.service
这时候fdisk -l可以看到节点上多出了一个设备 /dev/mapper/mpatha1
# ls -l /dev/mapper/mpatha
/dev/mapper/mpatha -->../dm-0 # 它是一个软链文件
dm-0 : device mapper 像LVM 也属于dm设备,第三方功能实现的设备在系统层面实别都叫device mapper 设备
配置文件函数优先级/etc/multipath.conf
multipaths —> devices —> defaults
scsci 设备唯一idwwid查询
# /usr/lib/udev/scsi_id -g -u /dev/sda
将sda 与 sdb 合成了一个设备 /dev/mapper/mpatha1,即这个设备是一个多路径的一个设备
# mount /dev/mapper/mpatha1 /var/www/html
- 更新resource 资源配置
# pcs resource disable myweb
# pcs resource update myfs device=/dev/mapper/mpatha1
# pcs resouce enable myweb
- 变更设备名称并同步到其它的节点
# vim /etc/multipath.conf # 更改设备别名
multipaths {
multipath {
wwid 360014050ad1b7a43a124f0c83ba2b0fd
alias storage1
path_grouping_policy multibus
path_selector "round-robin 0"
}
# scp /etc/multipath.conf root@nodeb.private.example.com:/etc/
# scp /etc/multipath.conf root@nodec.private.example.com:/etc/
# scp /etc/multipath.conf root@noded.private.example.com:/etc/
# systemctl restart mutipathd # 重启mutipathd 服务,生效配置
当mutipathd服务重启后,设备名会变更为clusterstorage
multipath -ll 可以查看具体的配置信息
# pcs resource update myfs device=/dev/mapper/clusterstorage1
其余产家多路径软件 ,在安装配置完多路径软件后,需要重启系统才能生效,重启完成后,会将两个设备合并成一个设备 ,系统中只能看到一个设备
- 所有node iscsi 客户端配置
# vim /etc/iscsi/iscsid.conf
node.session.timeo.replacement_timeout = 5 # 失败后尝试重连时间,默认是120s 看这个是不是业务能接受的时间范围
# systemctl restart iscsi
当两条链路宕了时,资源是不会切走的,因为它只检测它的资源还在
因为设备名是由系统内核来进行分配的,因此用UDEV机制来来解决设备名的问题
dmesg | grep eth 可以看到系统中也用到udev 来管理设备名
udev 规则
/etc/udev/rules.d/ 对应的序号越大,越是最后读取到,最后读取到的同样的规则,最后读到的生效
udevadm info -a -p /sys/block/sda
# udevadm info -a -p /sys/block/sdb | grep -i serial
# cd /etc/udev/rules.d/
# vim 99-mydisk.rules
SUBSYSTEMS=="usb",ATTRS{serial}=="5758503141323730334485858",SYMLINK+="mydsik%n"
udev规则变更完之后即时生效
# /sbin/udevadm control --reload-rules
# /sbin/udevadm trigger --type=device --action=change
udev 的缺省配置
# vim /etc/udev/udev.conf
udev_root="/dev"
udev_rules="/etc/udev/rules.d"
# udevadm info -a -p /sys/block/sdb | grep usb
# cat /et/udev/rules.d/99-mydisk.rules
SUBSYSTEMS=="usb",ATTRS{serial}=="4C5300001100327208463", SYMLINK+="myusb%n",OWNER="oracle",GROUP="oracle",MODE="0666", RUN="/usr/bin/wall World"
- udev 配置设备名称
# cat 99-myiscsi.rules
SUBSYSTEMS="scsi", PROGRAM=="/usr/lib/udev/scsi_id -whitelisted --replace-whitespace /de/$name", RESULT=="360014059DC7D1227D9E4399A8499296C",SYMLINK+="myiscsi%n"
- 如果配置的是红帽多路径,则不需要配置udev,因为红帽的多路径会把两个设备合并成一个
/dev/mapper/mpatha这样的设备- 如果是其他厂商自带的多路径,则多路径会将两个设备合并成一个标准设备,则需要额外配置udev
- 如果从存储上映射了两个或者以上的LUN,两个LUN生成的设备也会错乱
集群级文件系统
集群文件系统
为什么使用LVM技术 ? : 因为在集群中的文件系统也需要扩容,一旦扩容,最好使用LVM技术但单机的LVM只能用于一台机器,状态不能同步给集群的其他节点就需要使用集群级LVM
集群组LVM
1.HA-lVM 如果格式化的文件系统是ext4或者xfs,则使用HA-LVN,该LVM仅能同时在一个节点上激活,集群资源运行在哪个节点上,该LVM就在哪节点上被活动,其他节点不会激活
2.Cluster-LVM: 如果格式化的是GFS2 集群级文件系统,则使用cluster-LVM可以在同时在集群的所有节点上激活该LV,可以同时挂载所有的集群节点;
HA-LVM
- servera 创建逻辑卷
# pvcreate /dev/mapper/mpatha
# vgcreate clustervg /dev/mappper/mpatha
# lvcreate -L 2G -n data clustervg
- 所有集群节点创建
/data目录
# pcs resource create halvm LVM volgrpname=clustervg exclusive=true --group myweb
# pcs resource create myfs Filesystem device=/dev/clustervg/data directory=/data fsypte=ext4 --group myweb
- 同步lvm配置到其它节点
# vim /etc/lvm/lvm.conf # 找到 volume_list
volume_list = [""] # 表示不激活何卷组 ,由集群来控制它来激活
# scp /etc/lvm/lvm.conf root@nodeb:/etc/lvm/lvm.conf
# scp /etc/lvm/lvm.conf root@nodec:/etc/lvm/lvm.conf
# scp /etc/lvm/lvm.conf root@noded:/etc/lvm/lvm.conf
- 将集群所有节点修改的lvm配置写入到内核里
根据现有的内核版本,重新生成内核,会发生重启
# dracut -H -f /boot/initramfs-$(uname -r).img $(uname-r);reboot
HA-LVM
目前业务在nodea 上时,lvdisplay可以看到逻辑卷是激活并可以使用的,而有其余node 是卷组存在,但没有激活也没有使用的;即—> lv运行在哪里,对应的卷组就会在哪里进行激活;
集群级逻辑卷
locking_type=3 是一个集群锁,而 locking_type=1则是一个本地锁use_lvmetad=0表示不在用本地逻辑卷来维护它的原数据,而使用集群逻辑卷来维护它的原数据lvmconf --enable-cluster 把对应 /etc/lvm/lvm.conf的locking_type=3 与 use_lvmetad=0相关的参数发生改变
# pcs resource show # 清空之前测试的资源
- 集群所有的节点执行
# lvmconf --enable-cluster #
# cat /etc/lvm/lvm.conf | grep locking_type
# systemctl stop lvm2-lvmetad
- 添加集群级逻辑卷的资源
# pcs resource create mydlm controld op monitor interval=30s on-fail=fence clone interleave=true ordered=true
# pcs resource create myclvmd clvm op monitor interval=30s on-fail=fence clone interleave=true ordered=true
# pcs resource show
# pcs constraint order start mydlm-clone the myclvmd-clone
到目前为止只是把集群卷组创建好了,但是逻辑卷尚未创建,因此目前为止,集群资源还不能启动;
dlm是一个锁管理
- 所有节点安装对应的包
# yum -y install dlm
gfs2-utils集群级逻辑卷文件系统格式化
GFS2文件系统是支持SElinux策略,也包括quota 磁盘配额等等
GFS2是对称的共享的集群级文件系统
ruorum 的意思是最低法定人数,pacemaker 能够继续工作所需的最少的active的node个数,这个数是(num of node2)/2+1
如果不能达到法定人数时候行为如何呢 ?
ignore 表示继续运行,如果两个node的cluster只要有一个挂了,就小最小法定数目了,所以要设为ignore
freeze表示已经运行的resource 还是运行的,但是不能加入新的资源了;
- 安装分布式锁:dlm gfs2文件系统: gfs2-utils lvm2集群逻辑卷: lvm2-cluster
- 所有节点安装
# yum -y install dlm gfs2-utils lvm2-clustter # lvmconf --enable-cluster # pvcreate # systemctl stop lvm2-lvmetad # systemctl disable lvm2-lvmetad - 已经运行的资源还是运行,但不能加入新的资源
# pcs property set no-quorum-policy=freeze - 创建集群
# pcs resource create dlm controld op monitor interval=30s on-fail=fence clone interleave=true ordered=true # dlm 是名称 controld 是资源名称
# pcs resource create clvmd clvm op monitor interval=30s on-fail=fence clone interleave=true ordered=true # 因为都是集群集的,所以要 clone
# pcs constraint order start dlm-clone then clvmd-clone # 先启 dlm-clone 再启 clvmd-clone
# pcs constraint colocation add clvmd-clond with dlm-clone # 这两个资源在一起
# pcs resource list
# pcs status
- 集群创建好后, 可以来建立逻辑卷了
# pvcreate /dev/mapper/mpatha
# vgcreate vg0 /dev/mapper/mpatha
# lvcreate -L 3G -n data vg0
# lvdisplay
- 在所有的节点上查看LV的信息,在所有节点上都是Active状态
# lvdisplay
作为RHCA的常考内容
- 格式化于gfs2的文件系统
# mkfs.gfs2 -p lock_dlm -t cluster0:gfs2 -j 4 -J 64 /dev/vg0/data
# mount /dev/vg0/data /data # -t cluster0 这个名字要跟集群名称对应
而在这时候,所有集群节点挂载该集群文件系统,可以看到都有了数据的一致性与文件的锁的机制
对比单机式文件系统,集群式文件系统的优势可以体现得出
- 而在这时候
当集群故障时,将集群锁使用单机锁来挂载,可以进行数据备份操作
# mount -t gfs2 -o lockproto=lock_nolock /dev/vg0/data /data
# yum -y install httpd
# pcs resource create myip IPaddr2 ip=172.25.0.99 cidr_netmask=24 --group=myweb
# pcs resource show
# pcs resource create mygfs2 Filesystem device=/dev/vg0/data direcotry=/var/www/html fstype=gfs2 op monitor interval=30s on-fail=fence clone interleave=true --group myweb
# pcs resource create myservice systemd:httpd --group=mweb
# pcs constraint order clvmd-clone then mygfs2-clone
# pcs constraint colocation add clvmd-clone with mygfs2-clone
interleave=true ?? 这个参数有待查证具体含义
# chcon -R -t httpd_sys_content_t /var/www/html
# restorecon -Rv /var/www/thml
# echo 'Test Page' > /var/www/html/index.html
# firewall-cmd --permanet --add-port=80/tcp
# firewall-cmd --reload
- 这时候可以访问vip来进行测试
基于集群文件系统与逻辑卷调整等操作
# lvextend +512M /dev/vg0/data
# lvdisplay # 可以看到lvm 已经扩容,那么接下来扩文件系统
# gf2_grow /dev/vg0/data # 拉伸文件系统
- 这时候可以看到,当一个节点扩容后,其余node节点因为锁的一致性进行了扩容
# gsf2_edit -p jindex /dev/vg0/data # 可以看到journal日志文件有四个
那么日志区如何扩呢 ?
- 扩容 journal 的数量
# lvextend -L +256M /dev/vg0/data
# gfs2_jadd -j 2 -J 64 /var/www/thml # 这个是也是建立在集群即逻辑卷的基础上才可以这样做,这个命令执行后会通知到 Old Journals: 4 New Journals:6 且基于Filesystem: /var/www/html
# gfs2_edit -p jindex /dev/vg0/data # 可以看到6个Journal
# df -h # 可以看到存储下内容很少却占用了390多M的空间Journal_size=(64M*6)
当然,当文件系统故障或者损坏了,它也可以用fsck.gfs2来进行修复操作
但是这种情况不要在线扫描,要把集群文件系统停掉再来修复操作
# tunegfs2 /dev/vg0/data # 可以看卷组的超级块信息
tunegfs2修改 Lock table 信息
# tunegfs2 -o locktable=cluster1:gfs /dev/vg0/data
假如集群是从别的地方迁移过来的,那么可以通过这个命令来改相关的集群信息
一旦做了Cluster LVM 或者HA-lvm 不能创建快照


