







再探Python:再次学习以补充知识。这次学习聚焦于巩固Python装饰器,填补之前的知识空白。
装饰器
def logger(fn):
def wrapper(*args,**kwargs):
print('调用前增强')
ret = fn(*args,**kwargs) # 参数解构
print('调用后增强')
return ret
return wrapper
@logger
def add(x,y):
return x + y
print(add(100,200))
'''
1. 上例中的装饰器语法,称为无参装饰器
2. @符号后面是一个函数名,表示将该函数作为装饰器使用
3. 虽然是无参装饰器,但是@后的函数本质上是单参数函数
4. 上例的logger函数是一个高阶函数
'''
无参装饰器
def add(x,y):
return x + y
def logger(fn,x,y):
print(fn.__name__,x,y)
ret = fn(x,y)
return ret
print(logger(add,10,20))
- 好的,开始转柯里化
def add(x,y):
return x + y
def logger(fn):
def inner(*args,**kwargs):
print(fn.__name__,args,kwargs)
print('执行前可以做的事情,增强')
ret = fn(*args,**kwargs)
print('执行后可以做的事情,增强')
return ret
return inner
logger_add = logger(add)(4,y=100)
print(logger_add)
#以下为打印结果
add (4,) {'y': 100}
执行前可以做的事情,增强
执行后可以做的事情,增强
104
@logger # 等价式 , add = logger(add)
def add(x,y):
return x + y
# @装饰器语法,@标识符,把这一行下面一行的def定义的标识符作为其实参传递给装饰器函数,返回值覆盖了下面这个标签符;
# print(add(4,5)) # 非侵入代码,完成了功能,并且好像从来没有被装饰过一样
带参装饰器
def add(x,y):
return x + y
def logger(fn):
def inner(*args,**kwargs):
'''
add description
这个warpper函数的描述
'''
print(fn.__name__,args,kwargs)
print('执行前可以做的事情,增强')
ret = fn(*args,**kwargs)
print('执行后可以做的事情,增强')
return ret
return inner
logger_add = logger(add)(4,y=100)
print(logger_add)
@logger # 等价式 , add = logger(add)
def add(x,y):
'''
add description
这add函数的描述
'''
return x + y
help(add)
# Help on function inner in module __main__:
#
# inner(*args, **kwargs)
# add description
# 这个warpper函数的描述
from functools import wraps
def logger(fn):
@wraps(fn)
def inner(*args,**kwargs):
'''
add description
这个warpper函数的描述
'''
print(fn.__name__,args,kwargs)
print('执行前可以做的事情,增强')
ret = fn(*args,**kwargs)
print('执行后可以做的事情,增强')
return ret
return inner
logger_add = logger(add)(4,y=100)
print(logger_add)
@logger # 等价式 , add = logger(add)
def add(x,y:int):
'''
add description
# 这add函数的描述
'''
return x + y
print(add.__name__, add.__doc__, add.__annotations__)
# print(add(4,5)) # 非侵入代码,完成了功能,并且好像从来没有被装饰过一样
# @装饰器语法,@标识符,把这一行下面一行的def定义的标识符作为其实参传递给装饰器函数,返回值覆盖了下面这个标签符;
- 有参装饰器无参装饰器对比
# 对比有参装饰器
@logger # add = logger(add)
def add(x,y:int):
return x + y
@logger() # add = logger()(add)
def add(x,y:int):
return x + y
@logger(1,2) # add = logger(1,2)(add)
def add(x,y:int):
return x + y
import datetime
from functools import wraps,update_wrapper
def logger(warpped):
print('---------',warpped.__name__)
@wraps(warpped)
def wrapper(*args,**kwargs):
start = datetime.datetime.now()
ret = warpped(*args,**kwargs)
dalta = (datetime.datetime.now() - start).total_seconds()
print("{} tooks {}s".format(warpped.__name__,dalta))
return ret
return wrapper
@logger
def add(x,y):
return x + y
@logger
def sub(x,y):
return x - y
# 1. logger执行过么? #如果执行过,那么执行了几次? 2次
# 2 wraps执行过么? #如果执行过,那么执行了几次?2次
# 3. wraps 被覆盖过么? #如果被覆盖过,那么被覆盖了几次?1次
# 4. print(add.__name__,sub.__name__) #这2个名字打印的一样么?不一样
# 装饰器涉及到函数的细节: 函数、函数执行的过程,函数作用域、形参、实参、结构、嵌套函数、LEGB、高阶、柯里化、闭包;
annotation注解
- 友好性的提醒
def add(x:int,y:int) -> int: # -> int 表示返回值是int类型
"""
:param x: int
:param y: int
:return: int
"""
return x + y
print(add.__annotations__)
# 以上就可以根据在 -> int 在编辑器中可以根据函数的返回注解来做友好的返回补全、以加快编程的效率;
# 函数注解
# 3.5版本开始引入
# 对函数的的形参和返回值类型做的辅助的说明,非强制的约束类型;
a:list = [1,2,3]
a. 就可以开始补全
# 第三方式工具、例如Pycharm就可以根据类型注解进行代码分析、发现隐藏的bug
# 函数注解存放在函数的属性__annotations__中,字典类型
- 后续可以借助于
inspect来做基础判断
import inspect
inspect.isfunction(add) # True
def add(x:int,/,y:int, *args, m=100, **kwargs) -> int: # -> int 表示返回值是int类型
"""
:param x: int
:param y: int
:return: int
"""
return x + y
# print(add.__annotations__)
# import inspect
# inspect.isfunction(add) # True
import inspect
params = inspect.signature(add).parameters
for k,v in params.items():
print(k, v.name , v.default , v.annotation , v.kind)
# 打印结果
# x x <class 'inspect._empty'> <class 'int'> POSITIONAL_ONLY
# y y <class 'inspect._empty'> <class 'int'> POSITIONAL_OR_KEYWORD
# args args <class 'inspect._empty'> <class 'inspect._empty'> VAR_POSITIONAL
# m m 100 <class 'inspect._empty'> KEYWORD_ONLY
# kwargs kwargs <class 'inspect._empty'> <class 'inspect._empty'> VAR_KEYWORD
- 实例,装饰器实现函数传参类型判断
import inspect
from functools import wraps
def check(fn):
@wraps(fn)
def wrapper(*args, **kwargs): # {'x':'5', 'y':'4'}
params = inspect.signature(fn).parameters # OrderedDict {'x': Px, 'y': Py}
for v,p in zip(args, params.values()):
if p.annotation != p.empty and not isinstance(v, p.annotation):
print("{} = {} is not OK. args~~~".format(p.name, v))
for k, v in kwargs.items():
if params[k].annotation !=inspect._empty and not isinstance(v, params[k].annotation):
print("{} = {} is not OK. kwargs~~~".format(k, v))
ret = fn(*args, **kwargs)
return ret
return wrapper
@check
def add(x:int,y:int) -> int:
return x + y
print(add("4", "8"))
# check 是一个装饰器,它接收一个函数 fn 作为参数,然后返回一个新的函数 wrapper。
# wrapper 函数用于包装原始函数 fn。它接收任意数量的位置参数 *args 和关键字参数 **kwargs。
# 使用 inspect.signature(fn).parameters 获取原始函数的参数信息,得到一个有序字典 params,其中包含参数名及其注解信息。
# 通过 zip(args, params.values()) 遍历位置参数,检查每个参数的类型是否符合其注解要求。如果不符合,则输出相应的错误信息。
# 通过遍历关键字参数 kwargs,检查每个关键字参数的类型是否符合其注解要求。如果不符合,则输出相应的错误信息。
# 如果类型检查通过,调用原始函数 fn(*args, **kwargs)。
# 返回原始函数的结果。
# 在示例中,add 函数期望接收两个整数参数并返回它们的和。当你调用 add("4", "8") 时,装饰器检测到传递的参数类型不符合预期,然后输出相应的错误信息。
# 举例理解zip
names = ['Alice', 'Bob', 'Charlie']
ages = [25, 30, 35]
# 使用 zip() 合并两个列表
zipped_data = zip(names, ages)
# 查看合并后的结果
for item in zipped_data:
print(item)
# 输出结果
('Alice', 25)
('Bob', 30)
('Charlie', 35)
直接插入排序
- 插入排序
- 每一趟都要把待排序数放以有序区中合适的位置;
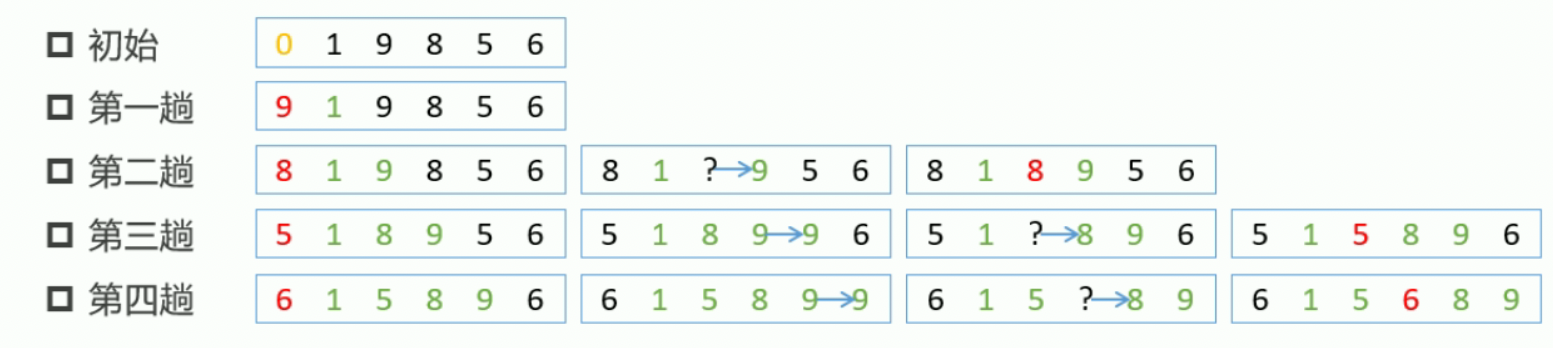
核心算法
- 结果可以为升序或降序排列,默认升序排列。以升序为例
- 扩大有序区,减少无序区。图中绿色部分就是增大的有序区,黑色部分就是减小的无序区;
- 增加一个哨兵位,图中最左端红色数字,其中放置每一趟比较数值;
- 将哨兵位数值与有序区数值从右到左依次比较,找到哨兵位数值合适的入点;
核心思想
- 将待排序数插入到已经排序好的有序区的合适的位置;
# 插入排序
# 核心思想: 将待排序数插入到已经排好的有序区的合适的位置
nums = [1,9,8,5,6]
nums = [None] + nums
length = len(nums)
print(nums[1:],length)
count_move = 0
for i in range(2,length): # 测试的值从nums的索引2开始向后直到最后一个元素
nums[0] = nums[i] # 8 [1,9] 8 # 索引0位哨兵,索引1位假设没有序区,都跳过
j = i - 1 # j = 2 # i 左边的数就是有序区末尾
if nums[j] > nums[0]: # 哪果最右侧数大于哨兵才需要挪动和插入
while nums[j] > nums[0]:
nums[j+1] = nums[j] # 8 1 9 9 # 右移,而不是交换
j -= 1 # 继续向左
nums[j+1] = nums[0] # 循环中多减了一次j
count_move += 1
print(nums[1:],count_move)
# 那么它的时间复杂度是多少呢? O(n**2)
# 稳定性是指对于相同的数,排序前后的相对位置不变
# 1 1 2 排序对于冒泡法来说是稳定的,等于不换; 对于直接插入排序来说也是稳定的;
functools
reduce
from functools import reduce,partial,lru_cache
# map reduce 是分布式计算的核心思想
def fn(x, y):
print(x, y )
return x + y
reduce(fn,range(5))
# 0 1
# 1 2
# 3 3
# 6 4
sum(range(5)) # 10
reduce(lambda x,y: x+y,range(5)) # 10
# 以上是累加
# 以下是累乘
reduce(lambda x,y: x*y,range(1,6)) # 120
def add(x, y =5):
return x + y
partial
newadd = partial(add,4) # 对一个函数的部分参数进行固定,从而返回一个新包装函数,这个函数应该是关于剩余参数的函数
newadd() # 9
add(4) # 9 跟以上一样的效果
- lru_cache
- 内部使用了一个字典
- key是由_make_key函数构造出来
from functools import _make_key
print(_make_key((4, 5), {}, False))
print(_make_key((4, 5), {}, True))
print(_make_key((4,), {'y':5}, False))
print(_make_key((), {'x':4, 'y':5}, False))
print(_make_key((), {'y':5, 'x':4}, False))
应用
@lru_cache
def fib(n):
return 1 if n < 3 else fib(n-1) + fib(n-2)
print(fib(500))
总结
lru_cache 装饰器应用
- 使用前提
- 同样的函数参数一定得到同样的结果,至少是一段时间内,同样输入得到同样的结果;
- 计算代价高,函数执行时间长
- 需要多次执行,每一次计算代价高
- 本质是建立函数调用的参数到返回值的映射
- 缺点
- 不支持缓存过期,key无法过期、失效
- 不支持清除操作
- 不支持分布式,是一个单机的缓存
lru_cache适用场景,单机上需要空间换时间的地方,可以用缓存来将计算成快速的查询;