







python 并发
并发与并行的区别
并发(Concurrency)和 并行(Paralle)是两个相关但不同的概念。
并行:指的是在同一时刻,多个任务可以同时进行,彼此之间互不干扰。在这种情况下,多个处理单元(如多核处理器)同时执行不同的任务。并行处理意味着任务之间真正同时执行。
并发:指的是在一段时间内,多个任务交替进行,每个任务都在一段时间内得到执行。尽管这些任务可能在同一时刻被处理,但它们之间可能交替执行或并行执行(如果有多个处理单元)。并发强调的是多个任务之间存在时间上的交替,而不一定是真正的同时执行。
举例来说:
假设有一条高速公路,有双向4车道。每辆车(数据)可以在自己的车道上行驶(传输),这是并行。在同一时刻,每条车道上可能同时有车辆行驶,这是并行。而在一段时间内,有多辆车要通过,这是并发。
总之,并行是指多个任务在同一时刻真正同时执行,而并发是指多个任务在一段时间内交替执行,可能同时发生,也可能不同时发生。并行通常是通过水平扩展方式来解决并发问题的一种手段。
进程和线程
进程(Process)
进程是计算机中程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的基本单位,也是操作系统结构的基础。以下是关于进程的一些重要概念:
- 定义:进程是程序被操作系统加载到内存中后的执行实例,包含指令和数据,是程序执行的环境。
- 进程和程序关系:程序是源代码编译后的文件,而进程是程序在内存中的执行实例,也是线程的容器。
- 特点:每个进程都有自己独立的内存空间,相互之间不会直接影响,可以独立运行和管理。
- 父子关系:Linux 中的进程有父进程和子进程之分,而在 Windows 中,进程之间是平等关系。
线程(Thread)
线程是操作系统能够进行运算调度的最小单位,是进程中的实际运作单位。以下是关于线程的一些重要概念:
- 定义:线程是程序执行流的最小单元,有时被称为轻量级进程(Lightweight Process,LWP)。
- 组成:一个标准的线程由线程ID、当前指令指针(PC)、寄存器集合和堆、栈组成。
- 特点:线程是进程的一部分,共享相同的地址空间和其他资源,但拥有独立的栈空间和指令执行流程。
- 创建效率:在许多系统中,创建一个线程比创建一个进程快 10-100 倍。
进程、线程的理解
- 现代操作系统提出进程的概念,每一个进程都认为自己独占所有的计算机硬件资源;
- 进程就是独立的王国,进程间不可以随便的共享数据;
- 线程就是省份,同一个进程内的线程可以共享进程的资源,每一个线程拥有自己独立的堆栈。
线程的状态
| 状态 | 含义 |
|---|---|
| 就绪(Ready) | 线程能够运行,但在等待被调度。可能线程刚刚创建启动,或刚刚从阻塞中恢复,或者被其他线程抢占。 |
| 运行(Running) | 线程正在运行。 |
| 阻塞(Blocked) | 线程等待外部事件发生而无法运行,如 I/O 操作。 |
| 终止(Terminated) | 线程完成,或退出,或被取消。 |
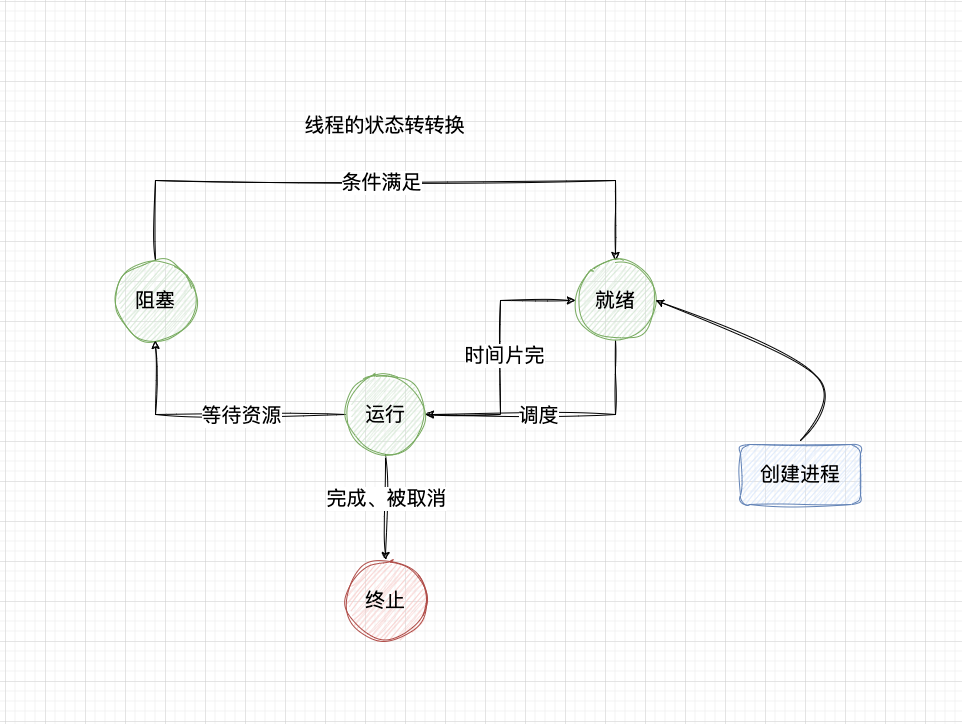
python中的进程和线程
运行程序会启动一个解释器进程,线程共享一个解释器进程;
python的线程开发
python的线程开发使用标准库threading;
进程靠线程执行代码、至少有一个主线程,其它线程是工作线程;
主线程是第一个启动的线程;
父线程: 如果线程A中启动了一个线程B,A就是B的父线程;
子线程: B就是A的子线程。
Thread类
# 签名
def __init__(self, group=None, target=None, name=None, args=(), kwargs=None, *, daemon=None):
| 参数名 | 含义 |
|---|---|
target |
线程调用的对象,就是目标函数。 |
name |
为线程起个名字。 |
args |
为目标函数传递实参,元组。 |
kwargs |
为目标函数关键字传参,字典。 |
线程启动
import threading
import time
# 定义一个函数
def worker():
print('I am working ~~~')
num = 50
for i in range(int(num)):
time.sleep(0.3)
print('working...' + '===' * i + '>' + '###' * (int(num) - i - 1), end='\r')
print('I am finished ~~~')
t = threading.Thread(target=worker, name='worker') # target 是一个函数,name 是线程的名字,只创建了一个线程管理对象
t.start() # 启动线程 ,调用系统调用,创建真正的操作系统的线程,启动运行target函数
线程退出
Python没有提供退出的方法, 线程在下面情况时退出;
- 线程函数内语句执行完毕;
- 线程函数中抛出未处理的异常;
import threading
import time
# 定义一个函数
def worker():
print('I am working ~~~')
num = 50
for i in range(int(num)):
time.sleep(0.3)
print('working...' + '===' * i + '>' + '###' * (int(num) - i - 1), end='\r')
print('I am finished ~~~')
t = threading.Thread(target=worker, name='worker') # target 是一个函数,name 是线程的名字,只创建了一个线程管理对象
t.start() # 启动线程 ,调用系统调用,创建真正的操作系统的线程,启动运行target函数
因此在线程中应该尽可能捕获异常
线程传参
# 线程的传参问题
def add(x,y):
print()
print (x + y)
return x + y # 目前情况下, 线程的返回值拿不到
# t = threading.Thread(target=add, args=(3,4), name='add')
t = threading.Thread(target=add, name='add', args=(), kwargs={'x':3, 'y':4})
t.start()
threading的属性和方法
| 名称 | 含义 |
|---|---|
current_thread() |
返回当前线程对象。 |
main_thread() |
返回主线程对象。 |
active_count() |
当前处于alive状态的线程个数。 |
enumerate() |
返回所有活着的线程的列表,不包括已经终止的线程和未开始的线程。 |
get_ident() |
返回当前线程的ID,非0整数。 |
# # 定义一个函数
def showthreadinfo():
print(threading.main_thread(), threading.current_thread(), threading.active_count()) # 返回主线程的线程对象,返回当前线程的线程对象,返回当前活跃的线程数
def worker():
showthreadinfo()
print('I am working ~~~')
num = 50
for i in range(int(num)):
time.sleep(0.2)
if i != 20:
print('working...' + '===' * i + '>' + '###' * (int(num) - i - 1), end='\r')
else:
print('\rNow 初始化工具 完成了 !!!', end='\r')
time.sleep(1)
print('I am finished ~~~')
t = threading.Thread(target=worker, name='worker') # target 是一个函数,name 是线程的名字,只创建了一个线程管理对象
time.sleep(2)
showthreadinfo()
t.start() # 启动线程 ,调用系统调用,创建真正的操作系统的线程,启动运行target函数
# <_MainThread(MainThread, started 7982456512)> <_MainThread(MainThread, started 7982456512)> 1
# <_MainThread(MainThread, started 7982456512)> <Thread(worker, started 6106722304)> 2
# I am working ~~~
# I am finished ~~~============================================================================================================================================>
import threading
import time
class MyThread(threading.Thread):
def start(self) -> None:
print('start ----')
super().start()
def run(self) -> None:
print('run ----')
super().run()
def worker():
print('I am working ~~~')
num = 50
for i in range(int(num)):
time.sleep(0.2)
if i != 20:
print('working...' + '===' * i + '>' + '###' * (int(num) - i - 1), end='\r')
else:
print('\r]\t\t\t\t\tNow 初始化工具 完成了 !!!', end='\r')
time.sleep(1)
print('I am finished ~~~')
t = MyThread(target=worker,name='worker')
time.sleep(2)
# t.start() 调用 系统调用,创建真正的操作系统的线程,启动运行target函数,且只能start一次,否则报错: RuntimeError: threads can only be started once
#t.run() # run是直接调函数,不会创建新的线程,只是调用了target函数
t.start() # start 是创建线程后,并启动线程
x = threading.main_thread()
print(type(x).mro())
print(x.name, x.ident, x.is_alive())
# 正常情况下,主线程就要是管理线程的,如果有任务,就创建一个线程管理对象,然后启动子线程
while True:
time.sleep(1)
if t.is_alive():
print(threading.active_count(),threading.enumerate())
if threading.active_count() == 1:
break
#print('I will restart t ~~~')
# t.start() 因此要注意,只要线程启过一次,就不能再启动了,否则报错: RuntimeError: threads can only be started once
# start ----
# run ----
# I am working ~~~
# [<class 'threading._MainThread'>, <class 'threading.Thread'>, <class 'object'>]
# MainThread 7982456512 True
# 2 [<_MainThread(MainThread, started 7982456512)>, <MyThread(worker, started 6146437120)>]#####################################################################
# 2 [<_MainThread(MainThread, started 7982456512)>, <MyThread(worker, started 6146437120)>]#####################################################################
# 2 [<_MainThread(MainThread, started 7982456512)>, <MyThread(worker, started 6146437120)>]#####################################################################
# 2 [<_MainThread(MainThread, started 7982456512)>, <MyThread(worker, started 6146437120)>]#####################################################################
# 2 [<_MainThread(MainThread, started 7982456512)>, <MyThread(worker, started 6146437120)>]#####################################################################
# 2 [<_MainThread(MainThread, started 7982456512)>, <MyThread(worker, started 6146437120)>]#####################################################################
# 2 [<_MainThread(MainThread, started 7982456512)>, <MyThread(worker, started 6146437120)>]=====>###############################################################
# 2 [<_MainThread(MainThread, started 7982456512)>, <MyThread(worker, started 6146437120)>]====================>################################################
# 2 [<_MainThread(MainThread, started 7982456512)>, <MyThread(worker, started 6146437120)>]===================================>#################################
# 2 [<_MainThread(MainThread, started 7982456512)>, <MyThread(worker, started 6146437120)>]==================================================>##################
# 2 [<_MainThread(MainThread, started 7982456512)>, <MyThread(worker, started 6146437120)>]=================================================================>###
# I am finished ~~~============================================================================================================================================>
# start() 创建一个系统线程,并把一个未来要执行的函数扔进去,然后启动线程,为线程关联目标函数、因此就是并行的效果;
# run() 只是调用了target函数,不会创建新的线程,只是调用了target函数,因此是串行的效果;
- 同时启动多个线程、查看对应交替运行
当使用start()方法启动后,进程内有多个活动的线程并行工作,就是多线程;
一个进程中至少且一个线程,并作为程序的入口,这个线程就是主线程;
一个进程至少有一个主线程;
其他线程称为工作线程;
import threading
import time
import sys
from termcolor import colored
class MyThread(threading.Thread):
def start(self) -> None:
print('start ----')
super().start()
def run(self) -> None:
print('run ----')
super().run()
def worker(f='green'):
print('I am working ~~~')
num = 50
for i in range(int(num)):
time.sleep(0.2)
if i != 20 and f == 'green':
print(colored('working...' + '===' * i + '>' + '###' * (int(num) - i - 1),'green'), end='\r')
elif i != 20 and f == 'red':
print(colored('working...' + '===' * i + '>' + '###' * (int(num) - i - 1),'red'), end='\r')
print('I am finished ~~~')
t = MyThread(target=worker,name='worker')
time.sleep(2)
# t.start() 调用 系统调用,创建真正的操作系统的线程,启动运行target函数,且只能start一次,否则报错: RuntimeError: threads can only be started once
#t.run() # run是直接调函数,不会创建新的线程,只是调用了target函数
t.start() # start 是创建线程后,并启动线程
t = MyThread(target=worker,name='new_worker',kwargs={'f':'red'})
t.start()
x = threading.main_thread()
print(type(x).mro())
print(x.name, x.ident, x.is_alive())

daemon
t = threading.Thread(target=worker, name='worker', daemon=True)
t.start()
#t.setDaemon(threading.main_thread().daemon)
time.sleep(3)
# daemon=True 守护线程,主线程没有任务退出,守护线程也会退出,就不管子线程的任务是否完成
# daemon=False 主线程退出,子线程还会继续执行
# 除主线程外,回眼看一下子线程的状态,只要有一个non-daemon线程还在运行,主线程就不会退出,但不会管daemon线程是否还在运行
# 主线程会等到最后一个non-daemon线程退出后,再退出,但不会管daemon线程是否还在运行;
print(threading.main_thread().daemon,'state') # 主线程的状态 False 主线程是non-daemon线程
| 名称 | 含义 |
|---|---|
daemon |
表示线程是否是daemon线程,这个值必须在 start() 之前设置,否则引发 RuntimeError。 |
isDaemon() |
是否是daemon线程。 |
setDaemon() |
设置为daemon线程,必须在 start() 方法之前设置。 |
线程的 daemon 属性总结
以下是关于线程的 daemon 属性的总结:
- 线程具有一个
daemon属性,可以手动设置为 True 或 False,也可以不设置,此时取默认值 None。 - 如果不设置
daemon属性,那么会取当前线程的daemon属性来设置它。 - 主线程是 non-daemon 线程,即
daemon=False。 - 从主线程创建的所有线程如果不设置
daemon属性,则默认都是daemon=False,即非守护线程。 - 当 Python 程序中没有活跃的非守护线程运行时,程序会退出。换句话说,除了主线程之外,剩下的所有线程都是守护线程,主线程只有等待它们结束后才能退出。
这个特性可以用于控制程序的退出行为,通过合理设置守护线程和非守护线程,可以确保程序在需要时可以正常退出,而不会因为线程未结束而被阻塞。
join()方法
import threading
import time
import sys
from termcolor import colored
class MyThread(threading.Thread):
def start(self) -> None:
print('start ----')
super().start()
def run(self) -> None:
print('run ----')
super().run()
def worker(f='green'):
print('I am working ~~~')
num = 50
for i in range(int(num)):
time.sleep(0.2)
if i != 20 and f == 'green':
print(colored('[ working... ]' + '===' * i + '>' + '###' * (int(num) - i - 1),'green'), end='\r')
elif i != 20 and f == 'red':
print(colored('[ working... ]' + '===' * i + '>' + '###' * (int(num) - i - 1),'red'), end='\r')
print('\nI am finished ~~~')
x = threading.main_thread()
t = threading.Thread(target=worker, name='worker', daemon=True)
t.start()
print(type(x).mro())
print(x.name, x.ident, x.is_alive())
time.sleep(3)
#t.join() # 主线程阻塞态,一直到条件满足,主线程才会继续执行, join 谁 ,join t 就是等待t线程执行完毕,主线程才会继续执行,即阻塞等t线程执行完毕
print('main thread is finished ~~~')
# t.join()执行结果
# I am working ~~~
# [<class 'threading._MainThread'>, <class 'threading.Thread'>, <class 'object'>]
# MainThread 7982456512 True
# [ working... ]===================================================================================================================================================>
# I am finished ~~~
# main thread is finished ~~~
# 注释掉t.join()执行结果
# I am working ~~~
# [<class 'threading._MainThread'>, <class 'threading.Thread'>, <class 'object'>]
# MainThread 7982456512 True
# main thread is finished ~~~==========================>############################################################################################################
线程的 join() 方法总结
join() 方法是线程的标准方法之一,以下是关于 join() 方法的总结:
- 当一个线程调用另一个线程的
join()方法时,调用者线程将被阻塞,直到被调用线程终止,或者等待超时。 - 一个线程可以被多个线程调用其
join()方法,这意味着一个线程可以等待多个其他线程的结束。 timeout参数可以指定调用者等待的时间,如果没有设置超时,调用者将一直等待被调用线程结束。- 调用谁的
join()方法,就是等待谁的结束,即调用者线程将等待被调用线程的结束。
join() 方法常用于控制线程的执行顺序,确保某些线程在其他线程结束后再执行。它可以协调线程之间的执行顺序,避免出现数据竞争等问题。
daemon 线程的应用场景
daemon 线程是一种特殊类型的线程,在某些场景下非常适用。以下是 daemon 线程的主要应用场景:
后台任务:如发送心跳包、监控等后台任务。这种场景下,daemon 线程可以在后台默默地执行任务,不会影响主线程的执行。
主线程工作才有用的线程:有些线程的工作依赖于主线程,如果主线程退出,那么这些线程也就没有存在的必要了。此时可以将这些线程设置为 daemon=True,这样当主线程退出时,这些工作线程也会随之退出。
随时可以被终止的线程:有些线程的工作是随时可以被终止的,不需要等待所有任务完成。这种情况下,可以将这些线程设置为 daemon,以便在主线程退出时一起退出。
daemon 线程的特点是一旦创建就可以忘记它,不需要手动关闭线程,只需要关心主线程的退出即可。这样简化了程序员手动关闭线程的工作,提高了程序的健壮性和可维护性。
Thread-Local
import threading
import time
import sys
from termcolor import colored
import logging
FORMAT = '%(asctime)s %(threadName)s %(thread)d %(message)s'
logging.basicConfig(level=logging.INFO, format=FORMAT)
class MyThread(threading.Thread):
def start(self) -> None:
print('start ----')
super().start()
def run(self) -> None:
print('run ----')
super().run()
class A():
def __init__(self):
self.x = 0
global_data = A()
# 那么使用threading.local()创建的对象,每个线程都有自己的数据,互不影响
global_data = threading.local()
def worker(f='green'):
logging.info('I am working ~~~')
num = 50
global_data.x = 0
# x = 0
# x 是局部变量,局部变量和每一次函数调用的栈帧有关,每次调用函数都会创建一个新的栈帧,所以x的值不会受到其他线程的影响
# 如果多个线程运行,使用的都是局部变量,是很安全的
for i in range(int(num)):
time.sleep(0.1)
global_data.x += 1
if f == 'green':
print(colored('[ working... ]' + '===' * i + '>' + '###' * (int(num) - i - 1),'green'), end='\r')
elif f == 'red':
print(colored('[ working... ]' + '===' * i + '>' + '###' * (int(num) - i - 1),'red'), end='\r')
logging.info('\nI am finished ~~~ {} ==> {} '.format(global_data.x, threading.current_thread().name))
for i in range(10):
# 判断i 为偶数时,创建线程对象
if i % 2 == 0:
t = threading.Thread(target=worker,name='work-{}'.format(i),kwargs={'f':'red'},daemon=False)
t.start()
else:
t = threading.Thread(target=worker,name='work-{}'.format(i),kwargs={'f':'green'},daemon=False)
t.start()
print('main thread is finished ~~~')
作业
- 用面向对象实现 LinkedList 链表
单向链表
实现方法
append(value): 在链表尾部添加节点iternodes(): 遍历链表,返回所有节点的值
双向链表
实现方法
append(value): 在链表尾部添加节点pop(): 弹出尾部节点insert(value, index): 在指定位置插入节点remove(index): 移除指定位置的节点iternodes(): 遍历链表,返回所有节点的值
提供的特殊方法
__getitem__(index): 获取指定位置节点的值__iter__(): 迭代链表,返回节点的值__setitem__(index, value): 设置指定位置节点的值
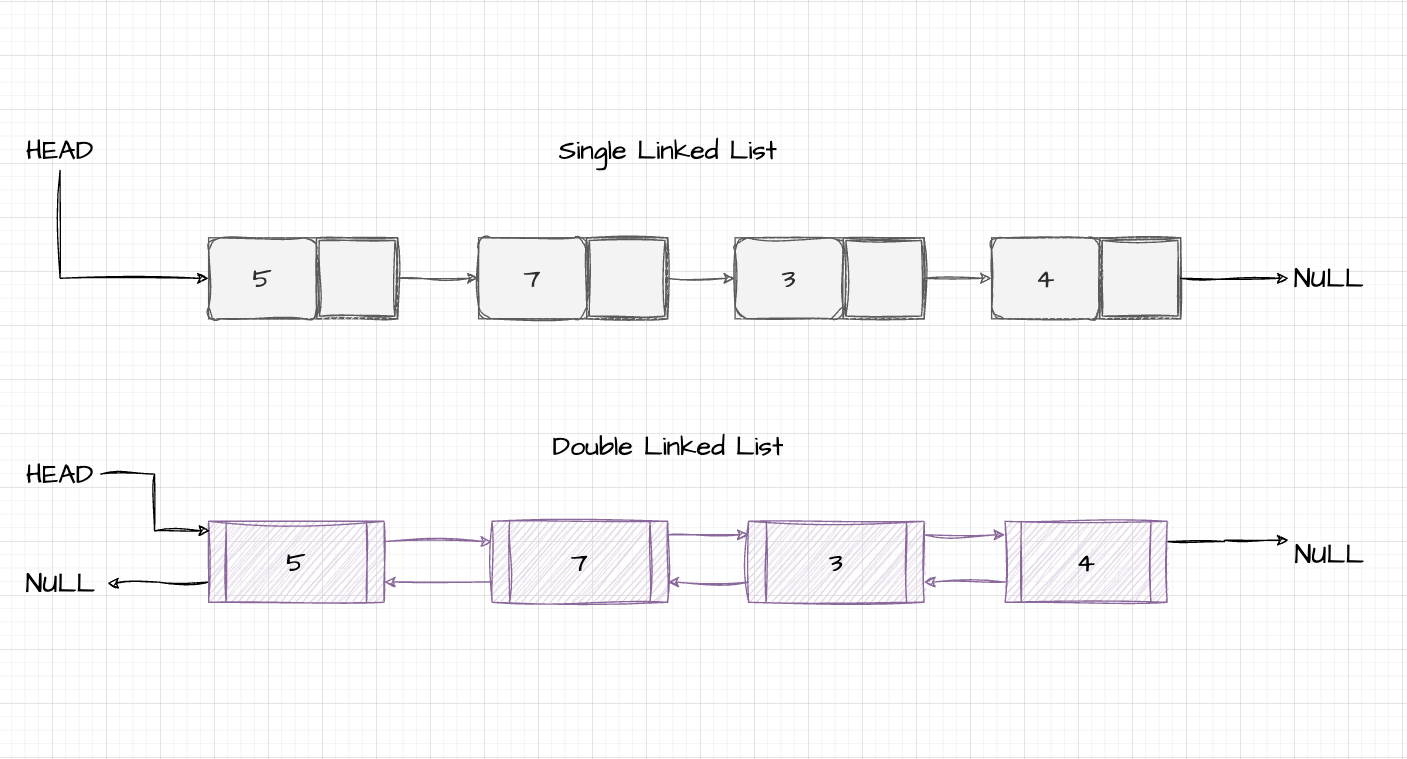
- 链表
实现LinkedList链表
链表有单向链表、双向链表
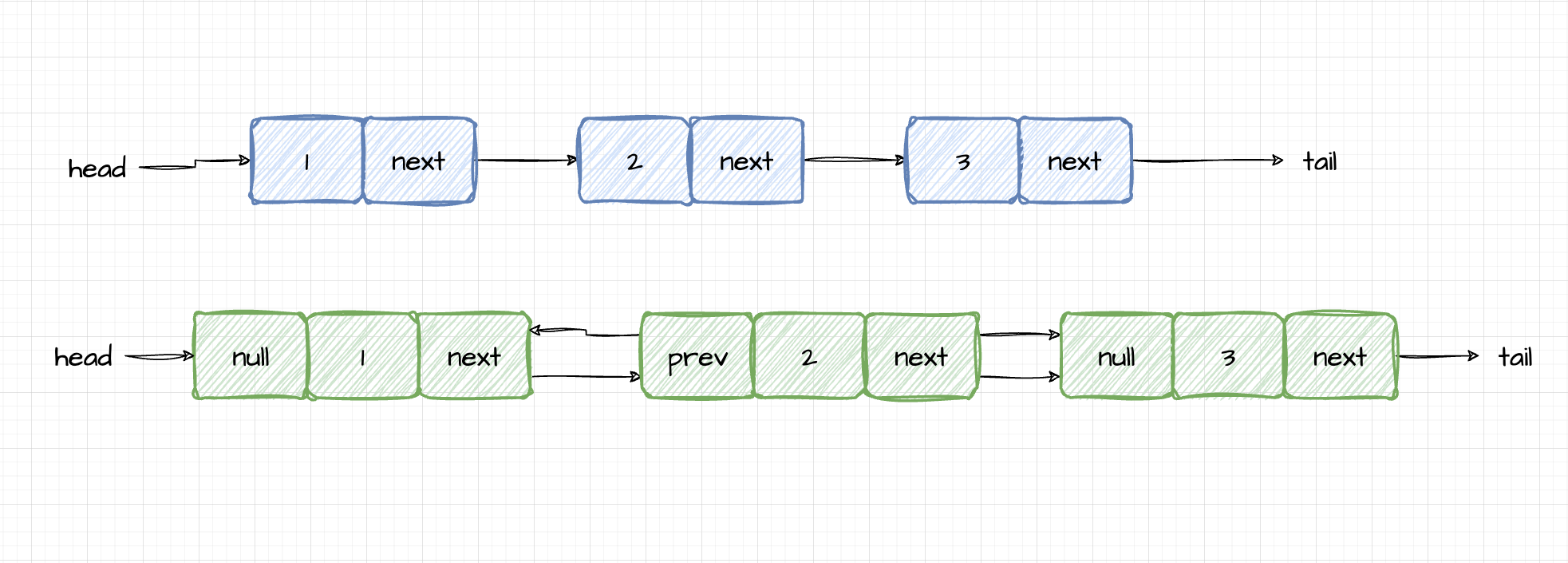
对于链表来说
- 每一个结点是一个独立的对象,结点对象有内容,还知道下一跳是什么。
- 链表则是一个容器,它内部装着一个个结点对象。
所以,建议设计2个类,一个是结点Node类,一个是链表LinkedList类。
如同一个箱子是容器,里面放的小球就是一个个节点。
如同一串珠子,节点对象是一个个珠子,每一颗珠子关联其前后的珠子,所有珠子形成串珠的概念,相当于容器。一串珠子可以从固定一头提起,这是单向链表;如果这串珠子可以从两头中的任意一头提起,这就是双向链表。
- 单向链表
from __future__ import annotations # 使用打补丁的方式,使得Node类可以在定义的时候使用Node类型提示
class Node:
def __init__(self,value,next:Node=None): #3.10之后的版本,可以使用Node作为类型提示
self.item = value
self.next = next
def __repr__(self) -> str:
return str(self.item)
class LinkedList: # 容器类
def __init__(self):
self.head = None
self.tail = None
def append(self,item):
node = Node(item)
# empty
if self.head is None:
self.head = node
self.tail = node
else:
# else not empty
self.tail.next = node
self.tail = node
return self
def internodes(self):
current:Node = self.head
while current:
yield current
current = current.next
ll = LinkedList()
ll.append(1).append(2).append(3)
for node in ll.internodes():
print(node) # 1 2 3
双向链表
pop方法实现
from __future__ import annotations # 使用打补丁的方式,使得Node类可以在定义的时候使用Node类型提示
# 双向链表
class Node:
def __init__(self,value,next:Node=None,prev:Node=None): #3.10之后的版本,可以使用Node作为类型提示
self.item = value
self.next = next
self.prev = prev
def __repr__(self) -> str:
return "{} <== {} ==> {}".format(
#self.prev,# 注意这个是实例,会导致递归调用
self.prev.item if self.prev else None,
self.item,
self.next.item if self.next else None
)
# def __str__(self) -> str:
# return str(self.item)
class LinkedList: # 容器类
def __init__(self):
self.head = None
self.tail = None
def append(self,item): # 实现尾部添加
node = Node(item)
# empty
if self.head is None: #empty
self.head = node
else:
self.tail.next = node
node.prev = self.tail # 原来的尾节点
self.tail = node # 更新尾节点
return self # 链式调用
def pop(self): # 实现尾部弹出
if self.head is None:
raise Exception('empty')
# 不为空
# 假设只有一个元素
node = self.tail
if self.head is self.tail:
self.head = None
self.tail = None
else:
# 假设有两个元素
prev = node.prev
prev.next = None
self.tail = prev
return node
def internodes(self,reverse=False):
current:Node = self.head if not reverse else self.tail
while current:
yield current
current = current.next if not reverse else current.prev
ll = LinkedList()
ll.append(1).append(2).append(3).append('end')
ll.pop()
for node in ll.internodes():
print(node) # 1 2 3
# None <== 1 ==> 2
# 1 <== 2 ==> 3
# 2 <== 3 ==> None
insert方法
from __future__ import annotations # 使用打补丁的方式,使得Node类可以在定义的时候使用Node类型提示
# 双向链表
class Node:
def __init__(self,value,next:Node=None,prev:Node=None): #3.10之后的版本,可以使用Node作为类型提示
self.item = value
self.next = next
self.prev = prev
def __repr__(self) -> str:
return "{} <== {} ==> {}".format(
#self.prev,# 注意这个是实例,会导致递归调用
self.prev.item if self.prev else None,
self.item,
self.next.item if self.next else None
)
# def __str__(self) -> str:
# return str(self.item)
class LinkedList: # 容器类
def __init__(self):
self.head = None
self.tail = None
def append(self,item): # 实现尾部添加
node = Node(item)
# empty
if self.head is None: #empty
self.head = node
else:
self.tail.next = node
node.prev = self.tail # 原来的尾节点
self.tail = node # 更新尾节点
return self # 链式调用
def insert(self,index,value): # 指定索引位置插入
if index< 0:
raise IndexError('Not negative index {}'.format(index))
current = None
for i,node in enumerate(self.internodes()):
if index == i:
current = node
break
else:
self.append(value) # 尾部插入写完了
return
# 说明了什么 ?: index >= 0 and index < length 找到插入点,至少一个元素
# 只有一个元素
node = Node(value)
prev = current.prev
if index == 0: # 2 头部插入
self.head = node
else: # 3 中间插入
node.prev = prev
prev.next = node
node.next = current
current.prev = node
def pop(self): # 实现尾部弹出
if self.head is None:
raise Exception('empty')
# 不为空
# 假设只有一个元素
node = self.tail
if self.head is self.tail:
self.head = None
self.tail = None
else:
# 假设有两个元素
prev = node.prev
prev.next = None
self.tail = prev
return node
def internodes(self,reverse=False):
current:Node = self.head if not reverse else self.tail
while current:
yield current
current = current.next if not reverse else current.prev
ll = LinkedList()
ll.append(1).append(2)
ll.append(3).append('end')
for node in ll.internodes(True):
print(node) # 1 2 3
print('-----------')
ll.pop()
ll.pop()
for node in ll.internodes(True):
print(node)
ll.insert(0,'start')
ll.insert(3,'end')
ll.insert(3,3)
print('-----------')
for node in ll.internodes():
print(node) # 1 2 3
# 3 <== end ==> None
# 2 <== 3 ==> end
# 1 <== 2 ==> 3
# None <== 1 ==> 2
# -----------
# 1 <== 2 ==> None
# None <== 1 ==> 2
# -----------
# None <== start ==> 1
# start <== 1 ==> 2
# 1 <== 2 ==> 3
# 2 <== 3 ==> end
# 3 <== end ==> None
remove方法
from __future__ import annotations # 使用打补丁的方式,使得Node类可以在定义的时候使用Node类型提示
# 双向链表
class Node:
def __init__(self,value,next:Node=None,prev:Node=None): #3.10之后的版本,可以使用Node作为类型提示
self.item = value
self.next = next
self.prev = prev
def __repr__(self) -> str:
return "{} <== {} ==> {}".format(
#self.prev,# 注意这个是实例,会导致递归调用
self.prev.item if self.prev else None,
self.item,
self.next.item if self.next else None
)
# def __str__(self) -> str:
# return str(self.item)
class LinkedList: # 容器类
def __init__(self):
self.head = None
self.tail = None
def append(self,item): # 实现尾部添加
node = Node(item)
# empty
if self.head is None: #empty
self.head = node
else:
self.tail.next = node
node.prev = self.tail # 原来的尾节点
self.tail = node # 更新尾节点
return self # 链式调用
def insert(self,index,value): # 指定索引位置插入
if index< 0:
raise IndexError('Not negative index {}'.format(index))
current = None
for i,node in enumerate(self.internodes()):
if index == i:
current = node
break
else:
self.append(value) # 尾部插入写完了
return
# 说明了什么 ?: index >= 0 and index < length 找到插入点,至少一个元素
# 只有一个元素
node = Node(value)
prev = current.prev
if index == 0: # 2 头部插入
self.head = node
else: # 3 中间插入
node.prev = prev
prev.next = node
node.next = current
current.prev = node
def pop(self): # 实现尾部弹出
if self.head is None:
raise Exception('empty')
# 不为空
# 假设只有一个元素
node = self.tail
if self.head is self.tail:
self.head = None
self.tail = None
else:
# 假设有两个元素
prev = node.prev
prev.next = None
self.tail = prev
return node
def remove(self,index): # 删除指定索引位置的元素
if self.head is None:
raise Exception('empty')
if index < 0:
raise IndexError('Not negative index {}'.format(index))
current = None
for i , node in enumerate(self.internodes()):
if index == i:
current = node
break
else: # 没有找到,该追加了
raise IndexError('Index out of range:{}'.format(index))
# 找到了
prev = current.prev
next = current.next
if self.head is self.tail: # only one element
self.head = None
self.tail = None
elif prev is None: # 不止一个元素, 或者current is self.head
self.head = next
next.prev = None
elif next is None: #不止一个元素, 移除末尾
self.tail = prev
prev.next = None
else:# 不止一个元素,中能是中间
prev.next = next
next.prev = prev
del current # 释放内存,回收垃圾
def internodes(self,reverse=False):
current:Node = self.head if not reverse else self.tail
while current:
yield current
current = current.next if not reverse else current.prev
ll = LinkedList()
ll.append(1).append(2)
ll.append(3).append('end')
for node in ll.internodes(True):
print(node) #
print('-----------')
ll.pop()
ll.pop()
for node in ll.internodes(True):
print(node)
ll.insert(0,'start')
ll.insert(3,'end')
ll.insert(3,3)
print('-----------')
for node in ll.internodes():
print(node) #
print('============')
ll.remove(4)
ll.remove(0)
for node in ll.internodes():
print(node)
- 开始完善容器功能
from __future__ import annotations # 使用打补丁的方式,使得Node类可以在定义的时候使用Node类型提示
# 双向链表
class Node:
def __init__(self,value,next:Node=None,prev:Node=None): #3.10之后的版本,可以使用Node作为类型提示
self.item = value
self.next = next
self.prev = prev
def __repr__(self) -> str:
return "{} <== {} ==> {}".format(
#self.prev,# 注意这个是实例,会导致递归调用
self.prev.item if self.prev else None,
self.item,
self.next.item if self.next else None
)
# def __str__(self) -> str:
# return str(self.item)
class LinkedList: # 容器类
def __init__(self):
self.head = None
self.tail = None
self._size = 0 # 用于记录链表的长度
size = property(lambda self: self._size) # 只读属性, 重写size方法
def __len__(self):
return self.size # 重写len方法
def append(self,item): # 实现尾部添加
node = Node(item)
# empty
if self.head is None: #empty
self.head = node
else:
self.tail.next = node
node.prev = self.tail # 原来的尾节点
self.tail = node # 更新尾节点
self._size += 1
return self # 链式调用
def insert(self,index,value): # 指定索引位置插入
# if index< 0:
# raise IndexError('Not negative index {}'.format(index))
# current = None
# for i,node in enumerate(self.internodes()):
# if index == i:
# current = node
# break
# else:
# self.append(value) # 尾部插入写完了
# return
if index >= len(self):
self.append(value)
return
if index < -len(self):
index = 0
current = self[index] # 1. 重写__getitem__方法
# 说明了什么 ?: index >= 0 and index < length 找到插入点,至少一个元素
# 只有一个元素
node = Node(value)
prev = current.prev
if index == 0: # 2 头部插入
self.head = node
else: # 3 中间插入
node.prev = prev
prev.next = node
node.next = current
current.prev = node
self._size += 1
def pop(self): # 实现尾部弹出
if self.head is None:
raise Exception('empty')
# 不为空
# 假设只有一个元素
node = self.tail
if self.head is self.tail:
self.head = None
self.tail = None
else:
# 假设有两个元素
prev = node.prev
prev.next = None
self.tail = prev
self._size -= 1
return node
def remove(self,index): # 删除指定索引位置的元素
if self.head is None:
raise Exception('empty')
# if index < 0:
# raise IndexError('Not negative index {}'.format(index))
# current = None
# for i , node in enumerate(self.internodes()):
# if index == i:
# current = node
# break
# else: # 没有找到,该追加了
# raise IndexError('Index out of range:{}'.format(index))
current = self[index]
# 找到了
prev = current.prev
next = current.next
if self.head is self.tail: # only one element
self.head = None
self.tail = None
elif prev is None: # 不止一个元素, 或者current is self.head
self.head = next
next.prev = None
elif next is None: #不止一个元素, 移除末尾
self.tail = prev
prev.next = None
else:# 不止一个元素,中能是中间
prev.next = next
next.prev = prev
self._size -= 1
del current # 释放内存,回收垃圾
def internodes(self,reverse=False):
current:Node = self.head if not reverse else self.tail
while current:
yield current
current = current.next if not reverse else current.prev
# def __iter__(self):
# yield from self.internodes()
# # return self.internodes()
__iter__ = internodes # 重写__iter__方法, 等价于上面的代码
def __reversed__(self):
# 1. 实现该方术方法,reversed 优先使用
# 2. 如果没有实现该方法,那么使用__len__ __getitem__方法
return self.internodes(reverse=True)
def __getitem__(self,index):
if index >= len(self) or index < -len(self):
raise IndexError('Index out of range: {}'.format(index))
# if index >= 0:
# for i ,node in enumerate(self.internodes(False),0):
# if index == i:
# return node
# if index < 0:
# for i ,node in enumerate(self.internodes(True),1):
# if -index == i:
# return node
# 开始简化以上判断
reverse = False if index >= 0 else True
start = 0 if index >= 0 else 1
for i,node in enumerate(self.internodes(reverse),start):
if abs(index) == i:
return node
def __setitem__(self,index,value):
self[index].item =value
ll = LinkedList()
ll.append(0).append(1).append(2)
ll.append(3).append('end')
ll[-1] = 'end2'
for i in range(5):
print(ll[i])
print('-'* 30 )
for i in range(-1,-6,-1):
print(ll[i])