







python 面向对象二
常见时间名词
GMT
格林威治标准时间(Greenwich Mean Time,GMT),指的是太阳经过格林威治处的本初子午线时的 时间。是最早的世界时(UT,Universal Time)标准。
时区
1884年制定了时区,以本初子午线为起点,经度每隔15度,划分一个时区,相邻时区相差一个小时。一 些国家会根据行政管理方便,调整时区。
UTC
协调世界时(Coodinated Universal Time),目前的世界时标准。 它由全球很多国家的铯原子钟时间协调得来,与所处地点无关。为了适应地球自转误差,UTC会做人为调整,比如闰秒。
可以简单的认为,GMT就是UTC + 0。
CST
中国标准时间(China Standard Time),UTC + 8:00,也称北京时间。当然CST也可以是美国中部时间 等的缩写。
时间模块
datetime模块
datetime 类是时间高级类
类方法,即使用类高用的方法,由类方法获得一个时间对象;
now(tz=None)返回当前时间的datetime对象,时间到微秒,如果tz为None,返回当前时区 的不带时区信息的时间;utcnow()不带时区的0时区时间;fromtimestamp(timestamp, tz=None)从一个时间戳返回一个datetime对象;tz=datetime.timezone.utc即0时区timezone对象;
时间对象方法
timestamp()返回一个到微秒的时间戳;Unix时间戳(Unix Epoch):格林威治时间1970年1月1日0点到现在的秒数;
- 构造方法
datetime.datetime(2016, 12, 6, 16, 29, 43, 79043) year、month、day、hour、minute、second、microsecond,取datetime对象的年月日时分秒及微秒weekday()返回星期的天,周一0,周日6;isoweekday()返回星期的天,周一1,周日7;date()返回日期date对象;time()返回时间time对象;
import datetime # 构造器
print(datetime.datetime(2021, 6, 17, 18, 20, 5))
# 类方法获得时间对象 print(datetime.datetime.now(datetime.timezone(datetime.timedelta(hours=8)))) # 时区时间
print(datetime.datetime.now()) # 无时区时间
print(datetime.datetime.utcnow()) # UTC时间,可以认为是GMT或0时区时间
# 时间戳操作
stamp = datetime.datetime.now().timestamp() # 获得时间戳 print(stamp)
dt = datetime.datetime.fromtimestamp(stamp) # 从时间戳获得时间对象 print(dt)
print(type(dt.date()), dt.date())
print(type(dt.time()), dt.time())
Python中时间分为两种:
- naive,没有时区信息的时间,没法明确定位。这个时间表示那个地区的时间,全看程序理解;
- aware,包含时区的时间;
- 这两种时间不能混合计算;
日期与格式化
- 类方法 strptime(date_string, format) ,返回datetime对象(时间字符串+格式化字符串 => 时间 对象)
- 对象方法 strftime(format) ,返回字符串(时间对象通过格式字符串 => 时间字符串)
- 字符串format函数格式化(时间对象通过格式字符串 => 时间字符串)
import datetime
datestr = '2018-01-10 17:16:08'
dt = datetime.datetime.strptime(datestr, '%Y-%m-%d %H:%M:%S') #由字符串到时间对 象
print(type(dt), dt)
print(dt.strftime('%Y/%m/%d-%H:%M:%S')) # 输出为字符串
print("{:%Y/%m/%d %H:%M:%S}".format(dt)) # 输出为字符串
timedelta类
datetime2 = datetime1 + timedeltadatetime2 = datetime1 - timedeltatimedelta = datetime1 - datetime2- 构造方法
datetime.timedelta(days=0, seconds=0, microseconds=0, milliseconds=0, minutes=0, hours=0, weeks=0)year = datetime.timedelta(days=365)
timedelta对象有方法total_seconds(), 返回时间差的总秒数
time模块
time.sleep(secs)将调用线程挂起指定的秒数
类的继承
基础概念
面向对象三要素之一,继承Inheritance
人类和猫类都继承自动物类。
个体继承自父母,继承了父母的一部分特征,但也可以有自己的个性。
在面向对象的世界中,从父类继承,就可以直接拥有父类的属性和方法,这样可以减少代码冗余、多复
用。子类也可以定义自己的属性和方法。
- 看一下不用继承的例子
class Animal:
def shout(self):
print('Animal shouts')
a = Animal()
a.shout()
class Cat:
def shout(self):
print('Cat shouts')
c = Cat()
c.shout()
上面的2个类虽然有关系,但是定义时并没有建立这种关系,而是各自完成定义。
动物类和猫类都会叫,但是它们的叫法有区别,所以分别定义。
class Animal:
def __init__(self, name):
self._name = name
def shout(self): # 一个通用的叫方法
print('{} shouts'.format(self._name))
@property
def name(self):
return self._name
a = Animal('monster')
a.shout()
class Cat(Animal):
pass
cat = Cat('garfield')
cat.shout()
print(cat.name)
class Dog(Animal):
pass
dog = Dog('ahuang')
dog.shout()
print(dog.name)
上例可以看出,通过继承,猫类、狗类不用写代码,直接继承了父类的属性和方法。
继承
class Cat(Animal) 这种形式就是从父类继承,括号中写上继承的类的列表。 继承可以让子类从父类获取特征(属性和方法)父类
Animal就是Cat的父类,也称为基类、超类。子类
Cat就是Animal的子类,也称为派生类。
定义
格式如下
class 子类名(基类1[,基类2,...]):
语句块
如果类定义时,没有基类列表,等同于继承自object。在Python3中,object类是所有对象的根基类。
class A:
pass
# 等价于
class A(object):
pass
注意,上例在Python2中,两种写法是不同的。
Python支持多继承,继承也可以多级。
查看继承的特殊属性和方法有
| 特殊属性或方法 | 含义 |
|---|---|
__bases__ |
类的基类元组 |
__base__ |
类的基类元组的第一项 |
__mro__ |
显示方法查找顺序,基类的元组 |
mro()方法 |
同上,返回列表 |
__subclasses__() |
类的子类列表 |
class A:
pass
print(A.__base__) # 输出 <class 'object'>,因为 A 隐式地继承自 object 类
print(A.__bases__) # 输出 (<class 'object'>,),类似地,object 是 A 的唯一基类
print()
print(A.mro()) # 输出 [<class '__main__.A'>, <class 'object'>],A 的方法解析顺序
print(A.__mro__) # 输出 (<class '__main__.A'>, <class 'object'>),类似地,A 的方法解析顺序
Python不同版本的类
Python2.2之前类是没有共同的祖先的,之后,引入object类,它是所有类的共同祖先类object。 Python2中为了兼容,分为古典类(旧式类)和新式类。
Python3中全部都是新式类。
新式类都是继承自object的,新式类可以使用super。
# 古典类(旧式类)
class A: pass
# 新式类
class B(object): pass
print(dir(A))
print(dir(B))
print(A.__bases__)
print(B.__bases__)
# 古典类
a = A()
print(a.__class__)
print(type(a)) # <type 'instance'>
# 新式类
b = B()
print(b.__class__)
print(type(b))
继承中的访问控制
class Animal:
__a = 10
_b = 20
c = 30
def __init__(self):
self.__d = 40
self._e = 50
self.f = 60
self.__a += 1
def showa(self):
print(self.__a)
print(self.__class__.__a)
def __showb(self):
print(self._b)
print(self.__a)
print(self.__class__.__a)
class Cat(Animal):
__a = 100
_b = 200
c = Cat()
c.showa()
c._Animal__showb()
print(c.c)
print(c._Animal__d)
print(c._e, c.f, c._Animal__a)
print(c.__dict__)
print(c.__class__.__dict__.keys())
从父类继承,自己没有的,就可以到父类中找。 私有的都是不可以访问的,但是本质上依然是改了名称放在这个属性所在类或实例的__dict__中。知道这 个新名称就可以直接找到这个隐藏的变量,这是个黑魔法技巧,慎用。
总结 继承时,公有成员,子类和实例都可以随意访问;私有成员被隐藏,子类和实例不可直接访问,但私有 变量所在的类内的方法中可以访问这个私有变量。 Python通过自己一套实现,实现和其它语言一样的面向对象的继承机制。
- 调试与解析
class Animal:
__a = 10 # _Animal__a = 10
_b = 20
c = 30
def __init__(self):
self.__d = 40
self._e = 50
self.f = 60
self.__a += 1 # self._Animal__a = self._Animal__a + 1
def showa(self):
print(self.__a) # self._Animal__a ==> 11
print(self.__class__.__a) # Class.__a ==> Cat.__a ==> 10
def __showb(self):
print(self._b) # self._b ==> 20
print(self.__a) # self._Animal__a ==> 11
print(self.__class__.__a) # Class.__a ==> Cat.__a ==> 10
class Cat(Animal):
__a = 100
_b = 200
c = Cat()
c.showa() # 打印 11, 10
c._Animal__showb() # 打印 200, 11, 10
- 实例属性查找顺序
实例的__dict__ → 类__dict__ →如果有继承→ 父类 __dict__ 如果搜索这些地方后没有找到就会抛异常,先找到就立即返回了。
方法的重写、覆盖override
class Animal:
def shout(self):
print('Animal shouts')
class Cat(Animal): # 覆盖了父类方法
def shout(self):
print('miao')
a = Animal()
a.shout()
c = Cat()
c.shout()
print(a.__dict__)
print(c.__dict__)
print(Animal.__dict__)
print(Cat.__dict__)
Cat中能否覆盖自己的方法吗?
Cat中能否对父类方法做个增强,不需要完全重写?
class Animal:
def shout(self):
print('Animal shout')
class Cat(Animal): # 覆盖了父类方法
def shout(self):
print('miao')
# 覆盖了自身的方法,显式调用了父类的方法
super().shout()
print(super(Cat, self))
super(Cat, self).shout() # 等价于 super()
# self.__class__.__base__.shout(self) # 不推荐
a = Animal()
a.shout()
c = Cat()
c.shout()
print(a.__dict__)
print(c.__dict__)
print(Animal.__dict__)
print(Cat.__dict__)
super()可以访问到父类的类属性。
静态方法和类方法,是特殊的方法,也是类属性,所以访问方式一样。
class Animal:
def shot(self):
print("Animal shots")
class Cat(Animal):
def shot(self): # 覆盖父类的方法,继重写
print("Cat shots")
a = Animal()
a.shot() # Animal shots
c = Cat()
c.shot() # Cat shots
- 锦上添花
class Animal:
def shot(self):
print("Animal shots")
class Cat(Animal):
def shot(self): # 覆盖父类的方法,锦上添花
# self.__class__.__base__.shot(self) # 调用父类的方法
# Animal.shot(self) # 调用父类的方法
super().shot() # 调用父类的方法, 找到离当前类最近的父类(祖先类)的方法
print("Cat shots")
c = Cat()
c.shot() # Animal shots, Cat shots
继承时使用初始化
- 调试
class A:
def __init__(self,a):
self.a1 = a
self.__d = 100
class B(A):
def __init__(self,b,c):
self.b1 = b
self.b2 = c
def showme(self):
print(self.b1, self.b2)
print(self.a1)
c = B(5,6)
c.showme() # 报错,因为B类没有继承A类的__init__方法,所以没有a1这个属性
# 修复后的代码
class A:
def __init__(self,a):
self.a1 = a
self.__d = 100
class B(A):
def __init__(self,b,c):
# A.__init__(self, b + c ) # 调用父类的__init__方法
super().__init__(b + c) # 调用父类的__init__方法
self.b1 = b
self.b2 = c
def showme(self):
print(self.b1, self.b2)
print(self.a1)
c = B(5,6)
c.showme() # 5 6 11
class A:
def __init__(self, a):
self.a = a
class B(A):
def __init__(self, b, c):
super().__init__(b) # 调用父类 A 的构造函数
self.b = b
self.c = c
def printv(self):
print(self.b)
# print(self.a) # 这一行会出错,因为在这个上下文中,self 指代的是当前代码所在的作用域,而不是类或实例
f = B(200, 300)
print(f.__class__.__bases__)
f.printv()
print(f.__dict__)
- 在
class B的__init__方法中使用super().__init__(b)调用了父类 A 的构造函数,确保A类的初始化逻辑得到执行。 - 注释掉了
print(self.a)这行代码,因为在这个上下文中,self指代的是当前代码所在的作用域,而不是类或实例,因此该行代码会导致错误。
上例代码可知:
如果类B定义时声明继承自类A,则在类B中__bases__中是可以看到类A。
但是这和是否调用类A的构造方法是两回事。
如果B中调用了父类A的构造方法,就可以拥有父类的属性了。如何理解这一句话呢?
观察B的实例 f 的__dict__中的属性。
- 调试
class A:
def __init__(self):
self.a1 = 100
class B(A):
pass
c = B()
print(c.__dict__) # 打印结果 {'a1': 100}
class A:
def __init__(self):
self.a1 = 100
class B(A):
def __init__(self, b):
self.b1 = 200
super().__init__()
self.b2 = b
c = B(300) # c.__init__
print(c.__dict__) # 打印结果 {'a1': 100, 'b1': 200, 'b2': 300}
class A:
def __init__(self, a):
self.a = a
class B(A):
def __init__(self, b, c):
super().__init__(b + c) # 使用 super() 调用父类 A 的构造函数
self.b = b
self.c = c
def printv(self):
print(self.b)
print(self.a)
f = B(200, 300)
print(f.__class__.__bases__)
f.printv()
print(f.__dict__)
作为好的习惯,如果父类定义了__init__方法,你就该在子类的__init__中调用它。
那么,子类什么时候自动调用父类的__init__方法呢?
- 示例1
class A:
def __init__(self):
self.a1 = 'a1'
self.__a2 = 'a2'
print('init in A')
class B(A):
pass
b = B()
print(b.__dict__)
B实例的初始化会自动调用基类A的__init__方法。注意生成的是什么类型的实例?注意self是谁。
- 示例2
class A:
def __init__(self):
self.a1 = 'a1'
self.__a2 = 'a2'
print('init in A')
class B(A):
def __init__(self):
super().__init__() # 调用父类 A 的构造函数
self.b1 = 'b1'
print('init in B')
b = B()
print(b.__dict__)
B实例一旦定义了初始化__init__方法,就不会自动调用父类的初始化__init__方法,需要手动调用。
class A:
def __init__(self):
self.a1 = 'a1'
self.__a2 = 'a2'
print('init in A')
class B(A):
def __init__(self):
self.b1 = 'b1'
print('init in B')
A.__init__(self) # 调用父类 A 的构造函数
b = B()
print(b.__dict__) # 注意 __a2
总结
- 如果在子类中覆盖了父类的
__init__方法,那么在子类的__init__方法中,应该显式调用父类的__init__方法 - Python中并不限制在子类的
__init__方法中调用父类的__init__方法的位置,但一般都应该尽早的调用 - 推荐使用
super().__init__()或super(B, self).__init__()
单继承
- 上面的例子中,类的继承列表中只有一个类,这种继承称为单一继承。
- OCP原则:多用“继承”、少修改。对扩展开放,对修改封闭。
- 继承的用途:在子类上实现对基类的增强,实现多态
多态
在面向对象中,父类、子类通过继承联系在一起,如果可以通过一套方法,就可以实现不同表现,就是
多态。多态的前提:继承、覆盖
- 体验一下多态
class Animal:
def __init__(self, name):
self.name = name
def shout(self):
print(f'{self.name} shouts')
class Cat(Animal):
def shout(self):
print(f'{self.name} Miao ~')
class Dog(Animal):
def shout(self):
print(f'{self.name} Wang ~')
c = Cat('Tom')
c.shout() # 输出 Tom Miao ~
d = Dog('Jack')
d.shout() # 输出 Jack Wang ~
多继承
一个类继承自多个类就是多继承,它将具有多个类的特征。
多继承弊端
- 多继承很好的模拟了世界,因为事物很少是单一继承,但是舍弃简单,必然引入复杂性,带来了冲突。
如同一个孩子继承了来自父母双方的特征。那么到底眼睛像爸爸还是妈妈呢?孩子究竟该像谁多一点
呢? - 多继承的实现会导致编译器设计的复杂度增加,所以有些高级编程语言舍弃了类的多继承。
- C++支持多继承;Java舍弃了多继承。 Java中,一个类可以实现多个接口,一个接口也可以继承多个接口。Java的接口很纯粹,只是方法的声 明,继承者必须实现这些方法,就具有了这些能力,就能干什么。
- 多继承可能会带来二义性,例如,猫和狗都继承自动物类,现在如果一个类多继承了猫和狗类,猫和狗 都有shout方法,子类究竟继承谁的shout呢?
- 解决方案: 实现多继承的语言,要解决二义性,深度优先或者广度优先。
Python多继承实现
class ClassName(基类1, 基类2[, ...]):
类体
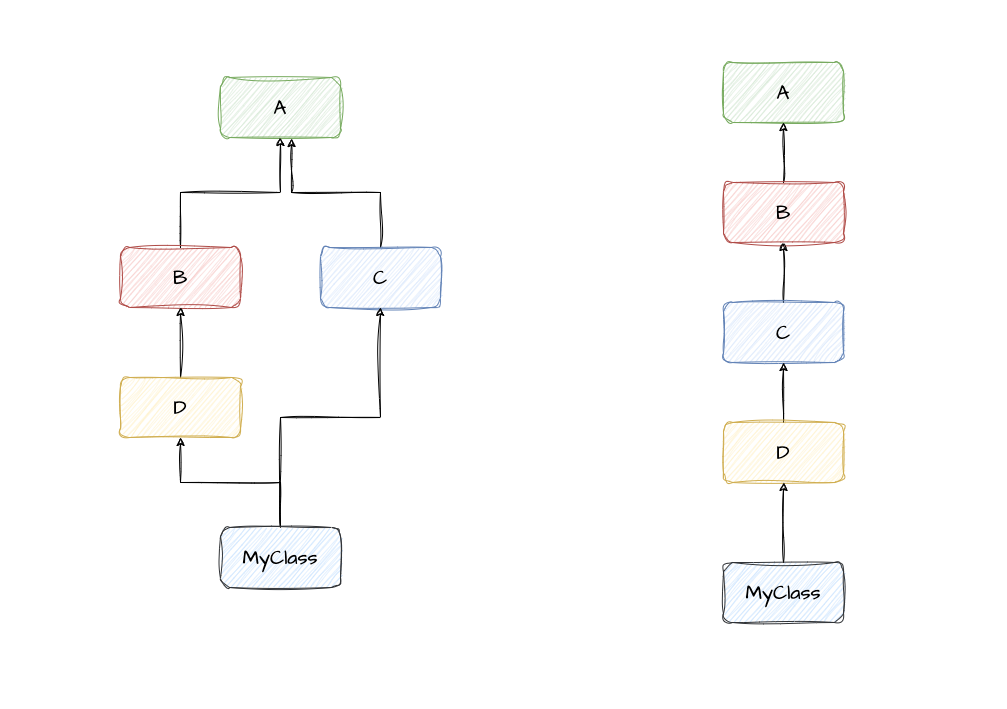
左图是多继承(菱形继承),右图是单一继承
多继承带来路径选择问题,究竟继承哪个父类的特征呢Python使用MRO(method resolution order方法解析顺序)解决基类搜索顺序问题。
- 历史原因,MRO有三个搜索算法:
- 经典算法,按照定义从左到右,深度优先策略。2.2版本之前 左图的MRO是
MyClass,D,B,A,C,A - 新式类算法,是经典算法的升级,深度优先,重复的只保留最后一个。2.2版本 左图的MRO是
MyClass,D,B,C,A,object - C3算法,在类被创建出来的时候,就计算出一个MRO有序列表。2.3之后支持,Python3唯一 支持的算法
- 左图中的MRO是
MyClass,D,B,C,A,object的列表 C3算法解决多继承的二义性
- 左图中的MRO是
- 经典算法,按照定义从左到右,深度优先策略。2.2版本之前 左图的MRO是
经典算法有很大的问题,如果C中有方法覆盖了A的方法,也不会访问到C的方法,因为先访问A的(深度 优先)。
新式类算法,依然采用了深度优先,解决了重复问题,但是同经典算法一样,没有解决继承的单调性。
C3算法,解决了继承的单调性,它阻止创建之前版本产生二义性的代码。求得的MRO本质是为了线性 化,且确定了顺序。
单调性:假设有A、B、C三个类,C的mro是[C, A, B],那么C的子类的mro中,A、B的顺序一致就是单调的。
多继承的缺点
- 当类很多且继承复杂的情况下,继承路径太多,很难说清什么样的继承路径。
- Python语法是允许多继承,但Python代码是解释执行,只有执行到的时候,才发现错误。
- 团队协作开发,如果引入多继承,那代码很有可能不可控。
- 不管编程语言是否支持多继承,都应当避免多继承。
- Python的面向对象,我们看到的太灵活了,太开放了,所以要团队守规矩。
Mixin
在Python的很多类的实现中,都可以看到一个Mixin的名字,这种类是什么呢?
类有下面的继承关系
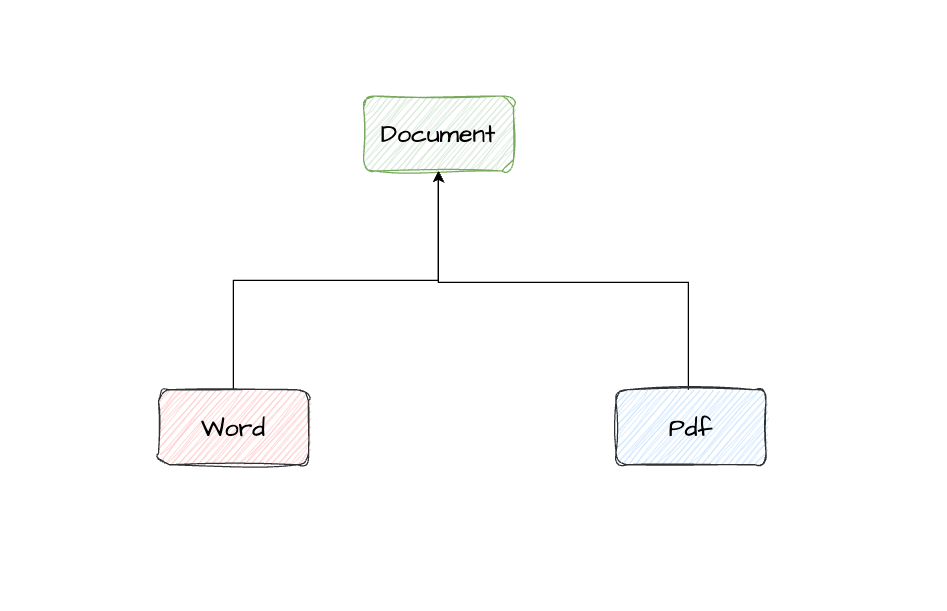
文档Document类是其他所有文档类的抽象基类;
Word、Pdf类是Document的子类。
需求:为Document子类提供打印能力
思路:
1、在Document中提供print方法
假设已经有了下面3个类
class Document:
def __init__(self, content):
self.content = content
def print(self): # 抽象方法
raise NotImplementedError("Subclasses must implement the print method")
class Word(Document): pass
# Word 类继承自 Document,没有额外的功能
class Pdf(Document): pass
# Pdf 类继承自 Document,没有额外的功能
基类提供的方法可以不具体实现,因为它未必适合子类的打印,子类中需要覆盖重写。
基类中只定义,不实现的方法,称为 “抽象方法” 。在Python中,如果采用这种方式定义的抽象方法,子 类可以不实现,直到子类使用该方法的时候才报错。print算是一种能力 —— 打印功能,不是所有的Document的子类都需要的,所有,从这个角度出发, 上面的基类Document设计有点问题。
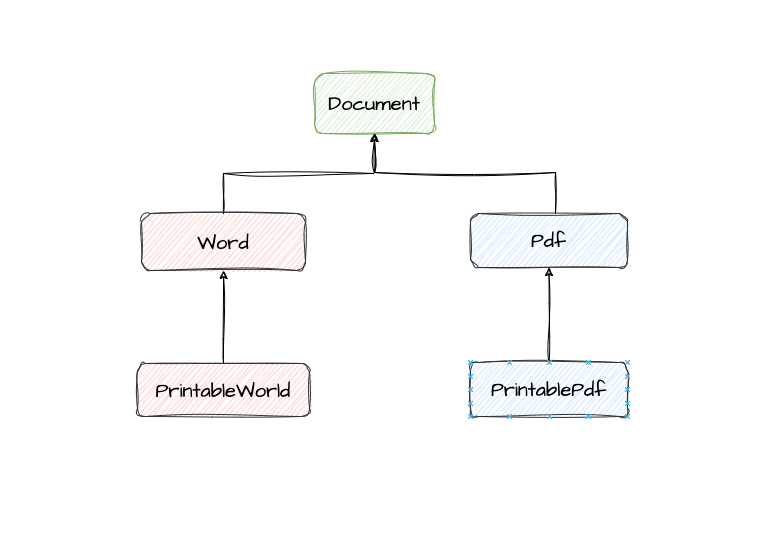
2、需要打印的子类上增加
如果在现有子类Word或Pdf上直接增加,虽然可以,却违反了OCP的原则,所以可以继承后增加打印功 能。因此有下图
class Document:
def __init__(self, content):
self.content = content
class Word(Document):
pass
class Pdf(Document):
pass
class PrintableWord(Word):
def print(self):
print(self.content)
print(PrintableWord.__dict__)
print(PrintableWord.mro())
pw = PrintableWord('test string')
pw.print()
看似不错,如果需要还要提供其他能力,如何继承?
例如,如果该类用于网络,还应具备序列化的能力,在类上就应该实现序列化。
可序列化还可能分为使用pickle、json、messagepack等。
这个时候发现,为了增加一种能力,就要增加一次继承,类可能太多了,继承的方式不是很好了。
功能太多,A类需要某几样功能,B类需要另几样功能,它们需要的是多个功能的自由组合,继承实现很 繁琐。
- Mixin
- 先看代码
class Document: # 第三方库,不允许修改
def __init__(self, content):
self.content = content
class Word(Document): # 第三方库,不允许修改
pass
class PrintableMixin:
def print(self):
print(self.content, 'Mixin')
class PrintableWord(PrintableMixin, Word):
pass
print(PrintableWord.__dict__)
print(PrintableWord.mro())
Mixin就是其它类混合进来,同时带来了类的属性和方法。
class Document: #抽象基类。在其他面向对象语言中,抽象基类不可以实例化,但是在Python中可以实例化。但不建议这样做
def __init__(self, content):
self.content = content
def print(self): # 抽象方法
raise NotImplementedError('我是父类,我就是不实现,实现是你们子类的事情') # 父类表示子类应该实现
class Word(Document): pass # n多个方法
class Pdf(Document): pass
class PrintableWord(Word):
def print(self):
print("[ {} ]".format(self.content))
class PrintablePdf(Pdf):
def print(self):
print("** {} **".format(self.content))
# c = Word('test')
# c.print() # 报错 NotImplementedError: 我是父类,我就是不实现,实现是你们子类的事情
w = PrintableWord('test word string ...')
w.print() # [ test word string ... ]
p = PrintablePdf('test pdf string ...')
p.print() # ** test pdf string ... **
- Doc类只管内容,至于打印功能不是doc类的,子类也不是必须,有些类如需要打印,就自己实现;
- word 需要打印,pdf 不需要;
- word A B C, pdf B D, xx A D
- 缺什么补什么 1装饰器 2 Mixin 多继承
Mixin类
class Document:
def __init__(self,content):
self.content = content
class Word(Document):
# pass # n多个方法
def print(self):
pass
class Pdf(Document): pass
class PrintableMixin:
def print(self):
print('*** {} ***'.format(self.content))
class PrintableWord(PrintableMixin, Word): pass # 先继承PrintableMixin,再继承Word
print(PrintableWord.__bases__) # 打印结果 (<class '__main__.PrintableMixin'>, <class '__main__.Word'>)
print(PrintableWord.mro()) # 打印结果 [<class '__main__.PrintableWord'>, <class '__main__.PrintableMixin'>, <class '__main__.Word'>, <class '__main__.Document'>, <class 'object'>]
pw = PrintableWord('test word string ...')
pw.print() # *** test word string ... ***
Mixin本质上就是多继承实现的。Mixin体现的是一种组合的设计模式。
在面向对象的设计中,一个复杂的类往往需要很多功能,而这些功能由来自不同的类提供,这就需要很多的类组合在一起。从设计模式的角度来说,多组合,少继承。
Mixin类的使用原则
- Mixin类中不应该显式的出现
__init__初始化方法。 - Mixin类仅实现单一功能,通常不能独立工作,因为它是准备混入别的类中的部分功能实现。
- Mixin类是类,也可以继承,其祖先类也应是Mixin类。
- 使用时,Mixin类通常在继承列表的第一个位置,例如
classPrintableWord(PrintableMixin, Word): pass。 - Mixin类和装饰器,都可以实现对类的增强,这两种方式都可以使用,看个人喜好。如果还需要继承就得使用Mixin类的方式。