








[toc]
Linux 性能调优

架构级设计
硬件调优
代码级调优
配置类调优
Linux 性能调优之监控
ps 命令说明
# ps aux
USER(用户) PID(进程ID) %CPU(CPU使用率) %MEM(内存使用率) VSZ(虚拟内存) RSS(实际内存) TTY(终端) STAT(进程状态) START(启动时间) TIME(占用资源的时间,即最近持续的运行时间) COMMAND(命令行)
- STAT
S 休眠状态
I< 空闲的高优先级内核线程(Idle kernel thread) - 查看单独的资源信息
# ps axo pid,comm,%cpu,%mem --sort=-%mem # 按照内存的使用率来排序 # ps axo pid,comm,%cpu,%mem --sort=-%cpu # 按照cpu使用率来排序 # ps -U apache # 查看 apache 的对应的id # pidof nginx # 查看进程的所有pidtop 说明
# top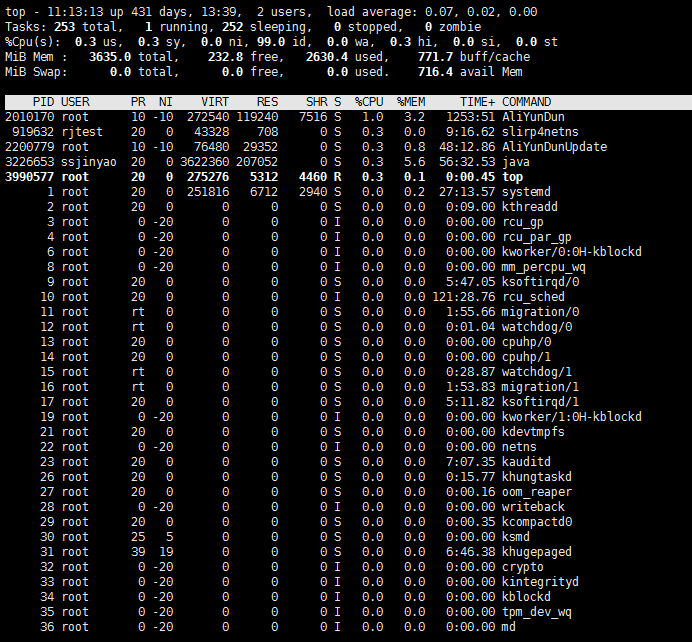 nice: 调整进程的优先级
nice: 调整进程的优先级- 11:13:13 显示当前时间
- up 431 days 系统不间断运行了431 天 13小时39分
- 2 users 当前登录用户有两个
- load average: 有三个值分别代表 1 分种平均负载, 5分钟平均负载, 15分钟平均负载
- Tasks: 253 total: 总共有253个任务, 1 running 252 sleeping, 0 stopped, 0 zombie
(僵尸): 僵尸进程一般是父进程已死,子进程依旧是在运行的 %Cpu(S) 所有CPU的使用情况: %Cpus(S)加在一起是100% 具体参数的涵义在man top可以看到说明- us, 用户程序消耗的时间
- sy, 内核进程消耗的时间
- ni, niced user processed 用户程序空闲的时间
- id, time spent in the kernel idle handler 在内核空闲处理程序中花费的时间
- wa, I/O 完成等待的时间,一旦看到这个值很高,说明系统的瓶颈是IO
- hi, hardware interrupts 硬中断消耗的时间
- si, hardware interrupts 软中断消耗的时间
- st, 虚拟化所消耗的时间,
- 其中有众多的命令可以查到这些参数,如
iostat - 测试使用率
md5sum /dev/zero运算一个零发射器,而这里使用率高的就是us - 测试使用率
dd if=/dev/zero of=/dev/nulldd 是由内核提供的,因此可以看到使用率高的是 sy
- PID 进程ID, USER用户, PR 优先级, NI调整优先级, VIRT 虚拟内存 , RES 真实内存, SHR共享内存 ,S进程状态,%CPU CPU使用率, %MEM 内存使用率, TIME+ 运行时间, COMMAND 命令行
PR: 数字越小优先级越高
NI: 数字越小优先级越高
nice -n -15 command进程启动指定进程优先极nice -20 PID启动进程后调整进程的优先级
优先级是从-20至20 数字越小,优先级越高
top 命令下按下c可以看到命令的详细内容
top 命令下按下1可以看到每个cpu的使用情况,再按下1就可以还原掉
top load average 的值,不超过当前cpu的核心数,表示它为当前负载为可接受的情况
si: softeware interrupt 软中断 软件中断 一个程序在运行,被一个更高优先级的程序中断
一个逻辑CPU同一时刻只能运行一个程序
hi: hardwareinterrupt 硬中断,即硬件中断,比如一个程序正在运行的时候,其调用到的相关网络设备坏了 - 调整大的程序为先进先出
chrtchange realtime 即,实时优先级# chrt -f 10 dd if=/dev/zero of=/dev/null & # chrt -f 11 dd if=/dev/zero of=/dev/null & # chrt -f 12 dd if=/dev/zero of=/dev/null & # 注这里CentOS7及以下的版本,两核CPU的情况会导致系统直接卡死,而CentOS8 不会,因为红帽8有自己的优化机制 # 红帽8的版本,虽然系统层面的应用程序会在优先级小时没有资源,但它会把系统层面必备的应用程序较少的分配CPU时间片,不使其卡系统死 瓶颈为IO的测试
# dd if=/dev/zero of=/tmp/test2 bs=4k count=204800 oflag=direct # oflag=direct 这个参数是指定读写数据不经过内存,而直接往磁盘中写,会导致IO等待占用CPU非常的高st 虚拟化占用CPU过高,很多情况下是因为当前主机所在的物理机上的其它虚拟机占用CPU过高导致的,也就是说可能物理机只有32C ,但却分配出去64C,这时别的虚拟机使用CPU直高时,会导致当前虚拟st 虚拟化占用CPU过高
free 说明
系统在启动的时候,会给内核分配不被别的进程占用的内存,也不会被污染。当内核出现的问题的时候,用于帮助还原内核
kdump 默认分配内存为128M == kernel dumpfree -m
buff/cache #是使用于缓存
当读取一个大文件时,会明显看到buff/cache占用会比原文件要大 缓存的作用在于,当第一次读取一个文件时,会把第一次读取的数据记录在缓存中,方便下次再读取到时能够快速的读取# time cp -r /var /tmp # real 执行时间为0m3.921s # free -m # 这时可以看到buff/cache 占用会比较大 # mkdir /data # time cp -r /var /data # 这时可以看到 real 执行时间为0m1.845s默认情况下,只要系统的内存有剩余,缓存都不会被清空
# sysctl -a | grep swapp vm.swappiness=0 # 取值范围为0-100 设置的值越大,越倾向于保留缓存,而一旦保留缓存,那么当内存紧张的时候就会使用到swap # sysctl -w vm.drop_caches=3 # 手动清除内存中的缓存vm.drop_caches=1 是用于清除inode即buff
vm.drop_caches=2 是用于清除block即cache
vm.drop_caches=3 是用于清除inode+block
内存紧张时会将一些暂时不用的内容临时存放在SWAP中
一旦应用程序需要使用这段内容,就会从swap调到内存中使用,否则这段内容一直放在SWAP中iostat 说明
# iostat -d /dev/vda 1 5 # 监控 /dev/vda磁盘,每秒监控一次,监控五次 # iostat -d /dev/vda # 不加时间的情况,默认统计的是自开启以来的所有读写的平均值与总值iostat 执行结果的 tps
tps: 每秒钟传输的IO请求数
测试tps数# dd if=/dev/zero of=/tmp/test3 bs=8k count=1024 oflag=direct Device tps kB_read/s kB_wrtn/s kB_read kB_wrtn vda 704.00 0.00 5632.00 0 5632获取执行的结果,bc运算,可以看到结果正好是8K
# echo "5632.00/704" |bc 8**可以
iostat -d /dev/vda 1 5 &> /tmp/testfile将数据存储在文件中用文本分析器进行分析# iostat -x 1 2sar 说明
常用参数说明
# sar -d 1 5 # 用于监控磁盘状态
# sar -r 1 5 # 用于监控内存信息
# sar -u 1 5 # 用于监控CPU信息
# sar -d -p 1 2 # 用真实的硬盘标识来显示磁盘状态
- 日期格式显示为24小时格式,这里需要添加环境变量
# vim ~/.bashrc # 添加以下内容,并生效
alias sar='LANG=C sar'
# source ~/.bashrc
# sar -d -p 1 2
sar与iostat的差别在于,sar能更好的作用于数据统计,它最后会给计算出平均值;
并且大的优势在于,可以利用其日志功能,获取指定时间内的数据进行分析与统计;
# cd /var/log/sa && sar -d -p -f sa11
CentOS8 系列要开启sar 日志记录服务
# vim /usr/lib/systemd/system/sysstat-collect.timer
# /usr/lib/systemd/system/sysstat-collect.timer
# (C) 2014 Tomasz Torcz <tomek@pipebreaker.pl>
#
# sysstat-11.7.3 systemd unit file:
# Activates activity collector every 10 minutes
[Unit]
Description=Run system activity accounting tool every 10 minutes
[Timer]
OnCalendar=*:00/10
[Install]
WantedBy=sysstat.service
可以看到正常情况下每10分钟记录一次,可以把服务开启,添设置为开机自启动
# systemctl restart sysstat-collect.timer
# systemctl enable sysstat-collect.timer
- 使用sar工具与其记录的日志统计指定时间段内的指定类型数据
# sar -s 12:40:00 -e 16:40:00 -d -p -f /var/log/sa/sa12 - 配合文本工具进行统计
比如统计 12:40:00 到 17:00:00 vda读写最高的统计# sar -s 12:40:00 -e 17:00:00 -d -p -f sa16 | grep vda | grep -v 'Aver' | awk '{print $1,$4+$5}' | sort -k2 -nr 15:40:01 338.93 13:00:01 277.22 16:00:01 230.2 14:00:01 164.41 15:30:01 99.05 14:10:01 82.74 13:30:01 58.59 13:50:01 47.03 16:40:01 33.43 15:10:01 32.56 14:30:01 30.36 15:50:01 25.11 16:20:01 19.91 13:40:01 17.88 16:50:01 9.83 15:20:01 8.01 16:30:01 7.93 14:20:01 6.38 14:40:01 6.31 13:20:01 6.31 12:50:01 6.05 13:10:01 5.09 15:00:01 4.97 16:10:01 4.92 14:50:01 4.52 - 同时sar 也可以做网络的监控
# sar -n DEV 1 2 sar -o数据收集与保留# sar -d -p 1 100 -o sar.data- 基于收集的日志进行数据分析
sar -d -p -f sar.data
pidstat 说明
# pidstat -p 3036 # 查看指定进程的资源占用情况
cifsiostat 说明
# cifsiostat #查看cifs 文件系统的占用情况
iotop 说明
# iotop 查看所有进程的io情况并进行排序
mpstat 说明
# mpstat -P 0-1 1 2 # 查看具体cpu的使用情况
vmstat 说明
# vmstat 1 5 # 节点整资源的监控
pcp 红帽独有工具说明
# yum -y install pcp pcp-gui # 安装 pcp 工具与其相关的图形化工具
# systemctl start pmcd.service --now #启动对应的服务
获取帮助信息
# pminfo | grep "disk.all.wirte"
# pminfo -dt disk.all.write
# pmval disk.all.write #显示所有磁盘的写操作,默认每秒钟监控一次
# pmval -s 3 disk.dev.write
# pmval -a 20141231.06.00.01.0 disk.dev.write_bytes | tail -n +13 | awk '{print $2}' | awk {printf("%f\n",$0)}' | sort -rn | more
图形化工具捕获数据
# pmchart &
日志抓取操作
file—> new charts —> disk —> all —> read_bytes —> write_bytes —> Apply
开始抓取操作
Record —> start
停卡抓取操作
Record —> stop
- 真题,分析已经抓取好的监控日志
# pmval -a /root/.pcp/pmlogger/I/21830117.10.59.13.0 disk.all.write_bytes | awk '{printf("%s %f\n"),$1,$2} | sort -k 2 -nr'Linux性能调优之模块
模块管理
- 列出系统中所有加载的模块
# lsmod | grep 'xfs ' xfs 1519616 1 # 这几个参数分别对应 名称、大小、使用次数 # 这个命令列出的是所有系统加载的模块 - 加载模块
# modprobe module_name # modprobe st - 卸载模块
在系统中模块是动态加载的,当系统检测到此模块时,会自动进行加载,当系统不在使用此模块的时候,会进行自动的卸载# modprobe -r st
比如卸载一个正在使用的模块,发现是卸载不了的modprobe -r xfs - 查询模块的具体的帮助信息
在Linux系统中所有的驱动程序都是以模块进行加载的,当然也有一些功能也是用的模块的,比如iptables的防火墙# modinfo st
模块是用于给设备进行命名的,而udev是作用于设备的命名
系统会带带众多的驱动程序,当然,当对应的新增设备没有驱动时,需要在第三方官网下载编译后进行加载
我们很多情况下对驱动程序模块参数的修改以达到调优的目的 - scsi 磁带机
例如调优# modprobe st # cd /sys/bus/scsi/scsi/st/st模块的buffer_kbs由32K 调整为128K
而这时要注意,模块参数的修改直接改对应/sys/bus/scsi/drivers/st目录下要的相关的参数是没有用的
当因为升级内核版本导致缺了驱动,使用系统无法正常启动时# cd /etc/modprobe.d/ # modinfo st | grep -w buffer_kbs parm: buffer_kbs:Default driver buffer size for fixed block mode (KB; 32) (int) # vim st.conf options st buffer_kbs=128 # 重新装载模块让其参数生效 # modprobe -r st # modprobe # 验证 # cat /sys/bus/scsi/drivers/st/fixed_buffer_size 131072 # echo "131072/1024" | bc 128 # 验证结果正好为128K - 备份首个init启动程序
类似解决方案与步骤# cp /boot/initramfs-3.10.0-229.el7.x86_64.img /root # mkinitrd --with=raid456 /boot/initramfs-3.10.0-229.el7.x86_64.img # cp /boot/initramfs-3.10.0-229.el7.x86_64.img /tmp # cd /tmp # zcat initramfs-3.10.0-229.el7.x86_64.img | cpio -id # ls -lR | grep raid456
- 官网下载LSI2008驱动程序;
- 在笔记本电脑虚拟机里面2.6.27内核中,编译源码包,生成驱动程序内核文件;
- 将笔记本地电脑中的驱动文件拷贝到RHEL5.4系统中去;
- 在RHEL5.4 系统中生成initramfs-2.6.27.el5.img文件;
- reboot
- 通过2.6.27内核启动,测试。
P2V技术
物理机迁移到虚拟机中
或者将物理机迁移到云中
解决迁移后启不来的问题
生产环境中很多迁移不成功,都是因为首个进程启动文件,或者内核文件中缺少驱动的问题
进入救援模式,切换根目录
NUMA: 非一致性内存访问# cp -a /boot/initramfs-3.10.0-229.el7.x86_64.img /root/ # rm -f /boot/initramfs-3.10.0-229.el7.x86_64.img # mkinitrd /boot/initramfs-3.10.0-229.el7.x86_64.img $(uname -r)(Non-Uniforrm Memory Access, 非一致性内存访问)
UMA: 一致性内存访问
FSB: 前端总线
物理内存: memory + swap
虚拟内存: 应用程序申请的内存,原则上可以无限申请
pagesize: 页大小
block szie: 文件系统的最小存储单元getconf -a | grep -i pagesize获取页大小pmap PID进程id对应调用的所有文件及其占用内存的大小dmidecode查看完
demsg bubber 记录最近启动时的状态
如果一个CPU只有两级缓存,则L1缓存是私有的,L2缓存是共享的,也就是说多个核共享L2
如果一个CPU有三级缓存,则L1和L2是私有的,L3是共享的
L1 cache一级缓存延迟周期有4个周期
L2 cache 二级缓存延迟周期有11个周期
L3 cache 三级缓存延迟周期有39个周期
Main memory Latency 107 cycles
L1,L2 一般都是每个核独占的,L3 则是每个插槽独有的# lscpu -p # 以下是可解析格式,可以输给其他程序。每列中的各个不同项有一个惟一 # 的从 0 开始的 ID。 # 编号,内核,插槽,NUMNODE,L1数据区,L2指令区,L2,L3 # CPU,Core,Socket,Node,,L1d,L1i,L2,L3 0,0,0,0,,0,0,0,0 1,0,0,0,,0,0,0,0
- 真题
CPU L1、L2、L3 缓存的大小,是共享,还是独立的,这个比较重要# dmidecode --dump-bin /boot/dmidecode.log # 这时会给出一个二进制格式的日志文件 # dmidecode --from-dump dmidecode.log > dmidecode.txt # 然后从中找出对应的L1 L2 L3 的缓存大小
dmidecode 查以对应缓存的16进制ID,再根据16进制ID 查对应ID缓存的大小CentOS8 加入的dmidecode查出缓存大小的计算方式
其中,L1 一级缓存,因为分为指令区和数据区,且为独占缓存,因此,其计算方式为L1缓存KB=L1总的缓存大小(KB)/corenum(核心数)/2(指使区,数据区)
其中,L2 二级缓存,若为独占缓存不分指令区和数据区,但为独占缓存,因此,其计算方式为L2缓存KB=L2总的缓存大小(KB)/corenum(核心数)
其中,L3 三级缓存,共享缓存不分指令区和数据区,为共享缓存,因此,其计算方式为L3缓存KB=L3总的缓存大小lshw -short显示硬件的详细信息内核调优
- 内核禁ping功能
# echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all - 开启内核转发功能
# echo 1 > /proc/sys/net/ipv4/ip_forwardsysctl -a可以列出系统中所有生效的内容
配置文件存放位置/etc/sysctl.conf全局配置文件/etc/sysctl.d/
使用# vim /etc/sysctl.conf net.ipv4.icmp_echo_ignore_all =1 net.ipv4.ip_forward =1sysctl -p 生效配置文件中的参数只能调/proc/sys/中的内容sysctl -w vm.drop_cache=3与echo的方式是一样的,即为立即生效 - 集成属性的调优工具
# cd /usr/lib/tuned # tuned-adm profile throughput-proformance # 修成调优属性 # sysctl -a | grep dirty - 新建集成组
# cp -a /usr/lib/tuned/throughput-performance/ /etc/tuned/rh442 # cd /etc/tuned/rh442 # 可以变更里面的内核参数 # tuned-admin profile rh442 # 加载新加入的集成组 # tuned-admin list
在调优的集成组配置文件里可以添加脚本,每当切入到当前组时可以执行指定的脚本# man tuned.conf # 可以查到详细的帮助信息[script] script=/backup/back.shCgroup
其实docker就是利用Cgroup实现资源的控制(Control Group 控制组)
在CentOS6及CentOS6 之前是使用limits来实现资源控制
soft# vim /etc/security/limits.conf user1 soft nofile 10 user1 hard nofile 20(软限制)与hard(硬限制)的区别在于,soft 用户登录默认就是限制为打开10个文件的上限,但被限制的用户自己可以临时调unlmit -n 20为硬限制所设置的值的上限
是时也可以对组进行限制,例如@user1 hard as 102400代表user1这个组内用户使用的虚拟内存加起来不能超过 102400K
Cgroup = Control group 作用于更精细化的限制
在红帽6的情况下,需要安装包libcgroup
当cgconfig 服务启动时,会生成# vim /etc/cgconfig.conf # service cgconfig stop # service cgconfig start/cgroup目录 ,这个目录下的文件与/proc中的数据很相似,都是写在内存中的一些数据man cgconfig.conf
这个限制表示对对scsi sda 盘的读操作不能超过1M# vim cgconfig.conf group smalldata { blkio { blkio.throttle.read_bps_device = "8:0 1048576"; } } # service cgconfig restart/etc/cgrules.confcgroup 策略的配置文件
这个策略表示,所有用户的# vim /etc/cgrules.conf *:cp blkio smalldata/ # service cgred restartcp操作使用 controllers 规则为以上新建的blkio
红帽自带的消耗内存的程序bigmem-6.2.0-1.r13591.x86_64.rpmbigmem 512强行消耗512M内存 - 再次加入对内存的限制
ls /cgroup/memory/可以查到memory 相关的参数
配置 cgconfig 控制器
配置 cgrules策略# vim cgconfig.conf group smalldata { blkio { blkio.throttle.read_bps_device = "8:0 1048576"; } memory { memory.limit_in_bytes = 256m; } } # service cgconfig restart# vim /etc/cgrules.conf *:cp blkio,memory smalldata/ # 配置多个规则,可以这样写 *:/usr/local/bin/bigmem memory smalldata/ # 配置bigmem命令的内存限制 # service cgred restartbigmem 512强行消耗内存,free -m实时监控发现只给分配了256m 的内存man -k resource | grep resource-controlman 5 systemd.resource-control查看各自资源限制的方法CentOS7,8 系统对服务进行限制
验证# cd /etc/systemd/system # mkdir nginx.service.d # cd nginx.service.d # vim 10-limits.conf [Service] MemoryAccounting=yes MemoryMax=256M # systemctl daemon-reload ● nginx.service - The nginx HTTP and reverse proxy server Loaded: loaded (/usr/lib/systemd/system/nginx.service; disabled; vendor pres> Drop-In: /etc/systemd/system/nginx.service.d └─10-limits.conf /usr/lib/systemd/system/nginx.service.d └─php-fpm.conf Active: active (running) since Mon 2022-01-10 14:23:50 CST; 1 weeks 1 days a> Main PID: 3182938 (nginx) Tasks: 3 (limit: 23069) Memory: 24.9M (max: 256.0M) CGroup: /system.slice/nginx.service ├─3182938 nginx: master process /usr/sbin/nginx ├─3322963 nginx: worker process └─3322964 nginx: cache manager process# cd /sys/fs/cgroup/memory/system.slice/nginx.service # cat memory.limit_in_bytes 268435456全局资源的限制
# cd /etc/systemd/system/
# vim memlimits.slice
[Unit]
Description=memory slice
[Slice]
MemoryAccounting=yes
MemoryMax=20M
单个服务引入全局资源
# cd /etc/systemd/system
# mkdir nginx.service.d/
# vim 10-limits.conf
[Service]
Slice =memlimits.slice
# systemctl daemon-reload
# systemctl restart nginx
cpu优先级
动态优先级调整,即贫民级 数字越小,优先级越高 范围 -20至19nice -n -15 COMMANDrenice -n -15 PID
静态优先级调整,即为贵族级,数字越大,估先级越高 范围 1到99
# ps aux pid,pri,rtprio,ni,cls,comm
其实CLS 中的TS 代表非实时优先级
Static priority 1-99: SCHED_FIFO and SCHED_RR
Static priority 0 (dynamic 100-139):SCHED_OTHER and SCHED_BATCH
SCHED_FIFO 先进先出 FIFO 高于RR
如果有进程的优先级是FIFO那么这个进程几首是独占一颗CPU
SCHED_RR轮询 轮询时,优先更高的,会分配到更多的CPU时间片
# chrt -f -p 15 3480 # -f 指定策略为先进行出,-p 优先级 最后更PID
# chrt -p PID # 查看当前的优先级与策略
# chrt -f 16 dd if=/dev/zero of=/dev/null &
# chrt -p 5523
# chrt -r 16 md5sum /dev/zero & # 轮询三个进程
# chrt -r 18 sha1sum /dev/zero &
# chrt -r 18 sha1sum /dev/zero &
CPU缓存
CPU Cache(CPU 缓存)
CPU命中率: 一程序在缓存中被读到的比例
# watch -n1 'ps axo pid,comm,psr | grep -w nginx'
重新调度均衡策略
默认CPU很忙的情况平均每100ms会均衡一次;
而默认CPU很空闲的时候默认1ms会均衡一次;
将程序调到一个CPU上时:
CPU cache的命令率高会降底服务的响应时间;
Unbalanced (不均衡的队列)会导致较长的等待时间;
当然可以指定在一个NUMA里,可以利用红帽的程序,模拟一个NUMA;
# taskset -p 9217
pid 9217's current affinity mask: 3
# 这里mask 3 指的是0号CPU与1号CPU均衡,mask=2^0+2^1,0即为0号CPU,1即为1号CPU2;
# taskset -p 2 9217
# 这里将mask 调整为2时,指的是将进程直接指定在1号CPU上;
mask(掩码)运算 2^0(0号CPU)+2^1(1号CPU)+2^2(2号CPU)+2^3(3号CPU)… 可以应用于需要特定CPU的应用场景,比如数据库的应用场景就可以这样绑定CPU
也可以指定CPU编号来绑定CPU
# taskset -pc 0 1
# taskset -pc 1 1
设置CPUAffinity 在服务中可以所行在所有的CPU上时
[Sservice]
CPUAfinity=""
示例
# cd /etc/systemd/system/
# vim nginx.service.d/10-limits.conf
[Service]
#Slice=memlimits.slice
CPUAffinity="1"
# 将服务绑定在1号逻辑cpu上运行
- 以调用脚本的方式
# vim /usr/local/bin/cpuset0 mkdir -p /sys/fs/cgroup/cpuset/cpuset0 echo 2-8 > /sys/fs/cgroup/cpuset/cpuset0/cpuset.cpus echo 0-1 > /sys/fs/cgroup/cpuset/cpuset0/cpuset.mems for PID in $(pgrep httpd); do echo ${PID} > /sys/fs/cgroup/cpuset/cpuset0/tasks done # vim /etc/systemd/system/httpd.service.d/cpuset.conf [Service] ExecStartPost=/usr/local/bin/cpuset0 # systemctl daemon-reload # systemctl restart httpd - 隔离一个CPU,将隔离的CPU再绑定其它应用程序时,可以这样做
假如当前四个逻辑CPU
这样启动的时候只会用的’0,1,2’ 这三个CPU# vim /etc/grub.conf isolcpus = 0,1,2 - BIOS 支持热插拔的情况下临时关闭CPU
临时关闭一颗CPUgrep processor /proc/cpuinfo cat /proc/interruptsecho 0 > /sys/devices/system/cpu/cpu1/onlinecat /proc/interrupts其中第一列是中断号,中间几列是对应的几号CPU,最后几列是设备
CentOS8 默认情况下会开启中断号均衡服务# watch -n1 "cat /proc/interrupts | grep ens160" # 可以看到四个CPU都有数据在使用,若无数据可以再将ping物理网卡对应的ip地址# systemctl status irqbalance.service # systemctl stop irqbalance.service # cd /proc/irq/56 # cat smp_affinity # echo 1 > smp_afinity在NUMA架构中
CPU、内存、磁盘、网卡
虚拟机感知NUMA架构,当运行虚拟机
虚拟机所使用的CPU和内存尽可能使用同一个NUMA中资源
同时也尽量让硬盘和网卡选择同一个NUMA nodecpuset
顾名思义cpu设置分组
同时也可以用以下方式来挂载# cat /proc/filesystems | grep cpu nodevcpuset # mount nodev -t cpuset /cpuset
不挂载的情况和读这个目录是一样的# vim /etc/fstab 添加以下内容 nodev /cpuset cpuset defaults 0 0 # mount -a# cd /sys/fs/cgroup/cpuset/ - 临时将一个进程调一个新建的cpuset中
当目录不在使用时可以使用# cd /cpuset # mkdir rh442 # cd rh442/ # echo 0 > cpuset.cpus # echo 0 > cpuset.mems # pidof nginx # pidof nginx # echo "1926586" > tasks # cat /proc/1926586/cpuset /rh442rmdir来清除 rh442类似的目录- 每一个cpuset代表一个调度域
- 可以通过cpuset 虚拟文件系统来管理cpuset
- root
(根)cpuset 包涵所有的系统资源 - 子cpuset 可以嵌套,子cpuset可以继承根cpuset中的资源
- 每一个cpuset必须包涵一个cpu 和一个内存zone
CPU的命中率
workstation节点CPU Cache
一个程序必须在CPU中才能被执行
一程序在CPU Cache 中才能运行,
一个程序在CPU Cache中命中比率, Cache hit cache命中率
反之,如果没有命中,则称为cache miss cache丢失率
一个程序cache miss丢失率越高,则意味着程序性能越差
一个程序从内存中移动到CPU cache中,Cache line cache 填充
BBU 损坏了,后备电池,给cache供电
如果一个程序在CPU Cache中改变了,则需要更新到内存中,需要写入硬盘
Write-through VS write-back(透写VS回写)
透写: 一个数据不经过缓存的整合,直接写入硬盘,称之为透写,当CPU Cache 中数据发生了改变,则立即写入内存;
回写: 一个数据需要先写入缓存,经过IO整合后再写入硬盘 80MB/S,当CPU Cache 中数据发生了改变,不会立即写入内存,当CPU Cache被再次改变的时候,才写入内存
node节点# lab cputuning-cpucache start # cd cache-lab-8.0# yum -y install valgrind # valgrind --tools=cachegrind ./cache1 # 可以详细打印一个程序被执行时的命中率 # valgrind --tools=cachegrind ./cache2内存调优
内存管理
- 虚拟内存:
进程所申请的内存管理空间,它是一段线性的,连续的地址空间
32位架构: 2^32 4GB
64位架构: 2^64 16EB,目前根据内核 支持大小不同,但最大不会超过256TB
虚拟内存在分配后,应用程序以为自己申请的是一段连续的地址空间,但对应物理的内存地址空间,它是不连续的,可以理解为拆物理内存的西墙,来补物理内存的东墙,应用程序申请的虚拟内存为连续的内存地址空间,如果物理内存和swap都用完后,便会发生内存溢出。 - 物理内存:
主板上的内存+SWAP - 虚拟内存如和与物理内存做映射:
通过映射表来记录虚拟内存到物理内存的映射关系;
可以看到申请的内存为连续的虚拟内存# pidof nginx # pmap 1991345 | tail -5 00007ffe98f2e000 132K rw--- [ stack ] 00007ffe98ffb000 12K r---- [ anon ] 00007ffe98ffe000 8K r-x-- [ anon ] ffffffffff600000 4K r-x-- [ anon ] total 128432K ps aux | grep 1991345 nginx 1991345 0.0 0.1 128428 7264 ? S 1月20 0:00 nginx: cache manager process
可以看到这个pid 申请的虚拟内存为128432K但实际分配的物理内存为7264
~ 然,经过以上输出,可以看到,每个调用的文件申请的虚拟内存都为4k的倍数,可以经过页大小来验证
pageszie 是由内核来决定的,在操作系统中是不可调的值# getconf -a | grep -i pagesize PAGESIZE 4096
oom out of memory 内存溢出
虚拟内存与物理内存的关系由 MMU内存管理单元来维护 负责地址映射
PTE: page table entries 页表条目,记录虚拟地址到物理地址的映射关系,内存中有一个独立的区域作用于PTE,其大小为128M
TLB: PTE buffer 映射表提供缓存
Hugepage 大页 也称之为 Big page
可以看出系统中默认的大页数据为# sysctl -a | grep -w vm.nr_hugepages vm.nr_hugepages = 00,因为配置大页是需要占用连续的物理地址空间的
再次查看内存,可以看到内存占用空间多了200M左右# vim /etc/sysctl.conf vm.nr_hugepages = 100 # free -m total used free shared buff/cache available Mem: 3634 2704 119 34 810 642 Swap: 0 0 0 # cat /proc/meminfo | egrep -iw "(hugepagesize|hugepages_total)" HugePages_Total: 0 Hugepagesize: 2048 kB # sysctl -p
32位架构: 4G 内存,实际应用程序可以申请到3G的内存
内核保留:
DMA: 直接内存访问,即不需要经过地址转换的,比如给设备直接分配缓存
设备分配缓存,ARP buffer
# modprobe st
# mondeinfo st # 可以看到其实质调整的bufferzie 才32K,这是因为系统IO 的总的分配内存为1M
高位内存: 是给应用程序用的
低位内存: 是给内核与BIOS,驱动用的
1024 MiB direct-mapped memory
128 Mib for mapping memory above 1 Gib(pgage tables)
896 MiB for ZONE_NORMAL
1 MiB for BIOS and IO devices
16 MiB for ZONE_DMA to support ISA limitations
879 MiB usable memory for ZONE_NORMAL ON 32-bit
因此,内核使用的这段低位内存使用完了,也会导到内存溢出的
# cat /proc/buddyinfo
# cat /proc/slabinnfo
而在64位的架构中,总共最大可以支持256T的内存
默认大页是没有被分配的,需要手动分配的
至于系统分配多少,取决于用户对系统结业务的理解
THP透明大页
# cat /sys/kernel/mm/transparent_hugepage/enabled
超大页面必须在引导时分配。它们也很难手动管理,且经常需要更改代码可以有效使用。因此Linux也部署了透明大页面(THP)。THP是一个提取层,可自动创建、管理和使用超大页面的大多数方面。THP可以改进系统的性能。
- 开关文件
使用命令查看时,如果输出结果为[always]表示透明大页启用了。[never]表示透明大页禁用、[madvise]表示只在MADV_HUGEPAGE标志的VMA中使用THPcat /sys/kernel/mm/transparent_hugepage/enabled - 存在问题
THP在有些应用场景会出现异常,因此Oracel、MongoDB、Redis等服务都建议关闭这个特性,因为这个可能导致延迟和内存使用问题 - 临时解决办法
# echo never > /sys/kernel/mm/transparent_hugepage/enabled # echo never > /sys/kernel/mm/transparent_hugepage/defragman vmstat
overcommit 内存过量分配in: 每秒钟处理的中断数 cs: 每秒钟有多少上下文切换,如果这个值很大,则代表有很大的页进页出
应用程序申请的内存超过物理内存(包含swap)
开关vm.overcommit_memory = 0 # 0 = heuristic overcommit # 尝试过量分配 # 1 = always overcommit # 总是过量分配 # 2 = commit all swap plus a percentage of RAM(may be > 100) vm.overcommit_ratio = 50vm.overcommit_memory = 2vm.overcommit_ratio = 50
这个参数的意思是,应用程序可以过量分配内存= swap + memory *50vm.dirty_expire_centisecs = 3000脏页回收的时间,单位是 1/100S
数据读取操作,什么把数据先临时放到脏页里面vm.dirty_ratio = 30脏页在内存中的比例,即为底水位,只要超过底水位就会对脏页进行回收
正常情况我们一定要确保正常关机,临时数据会存储内存的脏页里面,如果发生了断电重启会导致内存中的脏页丢失,这样的话数据就不会落在磁盘上cat /proc/meminfo | grep Dirty目前脏页中的数据大小
执行sync命令可以立即回收脏页
电梯算法
500 扇区 10000扇区 1000扇区 11000扇区,在磁盘中会有众多的扇区,如果不经过IO的整合会导致磁头频繁移动读写
然而缓存中经过IO整合,可以一次性将合的数据写入到硬盘中
小IO更加有用vm.dirty_bytes = 0脏页最大的大小,默认为0代表不设置vm.dirty_background_ratio = 10某一个程序脏页使用最大内存比例,则进行回收vm.dirty_background_centisecs = 500即监控的巡视脏页使用的时间为5s,即每五秒钟巡视一次,巡视脏页的使用有没有超过底水位
yum -y install kernel-doc/usr/share/doc/kernel-doc-4.18.0/Documentation/admin-guide/sysrq.rst 系统触发器
比如强制断电重启的信息 echo b > /proc/sysrq-trigger
强制尝试同步所有的挂载文件系统 echo s > /proc/sysrq-trigger
当内存紧张的时候,先释放cache呢 ? 还是先使用 swap ?
# sysctl -a | grep swappiness
vm.swappiness = 0
取值范围是0-100,默认是60,也就是说这里的这个值是一个倾向的值,这个数字越小,越倾向于少使用,或不使用swap(即尽量释放cache),反之数字越大,则越倾向于使用swapcat /usr/share/doc/kernel-doc-4.18.0/Documentation/sysctl/vm.txt 相关内核参数说明文档/proc/PID/oom_adj 调整的值 -17 - 15 数字越大,一旦oom发生,被kill掉概率越大
反之,数字越小,发生oom 时,不会被 kill/proc/PID/oom_score 即为被杀的概率
当系统oom时,系统会作出反应,将被杀的概率较大的程序先杀死,来确保内存,保证系统的正常运行
disable oom-kill 的机制 vm.panic_on_oom = 1
- 内存泄露
一个应用程序运行时,会分配100MB内存,当应用程序关闭时,则释放该内存,但是释放总是不彻底,长此以往 ,就会导致内存占用过高,windows 系统在其设计原理上,普遍存在这样的问题;
SWAP 交换分区# valgrind --tool=memcheck --trace-children=yes ./bigmem 512M
anonymous 匿名页
多个SWAP情况下的优先级
这样的话,那么意味着,这两个swap 的优先级是一样的# vim /etc/fstab /dev/vdb1 swap swap defaults,pri=2 0 0 /dev/vdb2 swap swap defaults,pri=2 0 0 # swapnon -a
内存越大,建议swap相对来说,设备大一些# swapon -s # 查看优先级 - 将数据直接写在内存中
# vim /etc/fstab nodev /data3 tmpfs defaults 0 0 # mount -a
在内存中写入40M的数据,这时候用# dd if=/dev/zero of=/data3/testfile bs=4k count=10000sysctl -w vm.drop_cache=3这时候用 vm.drop_cache=3的这种方式是清不了的,只能用rm -f /data3/testfile的形势来进行删除,以上这种方法可以应用在缓存服务器中,将内存作用于磁盘。numctl
在numa 里平均分配资源给固定的程序# bigmem 200M # numstat -c bigmem# numactl --interleave all -- bigmem 600M# numastat -c bigmem磁盘文件系统
在cpu 内存配置很高的情况下xfs 的文件系统性能要高于ext4的文件系统
xfs文件系统不可以伸缩文件系统,而ext4是可以的
ext4相对而言跟兼容于ext2 ext3的文件系统
xfs 中支持最大的单个文件是1PB, 而单个的文件系统可以达到一个EB
ext4支持最大的文件系统,即最大的单个分区 50TB 而支持最大的的单个文件大小是16TB
ext4支持持续的分配、多block分配、还有一些条带的分配
没有特定的场景推荐使用xfs
大的服务 推荐使用xfs
大的存储设备推荐使用xfs
大的文件推荐使用xfs
多线程(Multi-threaded)的I/O 推荐使用xfs
小的文件 推荐使用ext4
单线程(Single-threaded)的IO 推荐使用ext4
限制IO 能力capability 1000IOPS 推荐使用ext4
限制带宽200M/s 推荐使用ext4
CPU 负责过高推荐使用ext4
支持离线扩展推荐使用ext4
ext4 文件系统
# dd if=/dev/zero of=/dev/vdc1 bs=4k count=10 # 模拟文件系统损坏
# fsck -yv /dev/vdc1 # 用于修复文件系统
# e2fsck -yv 98304 /dev/vdc1 # 用于恢复文件系统的group1 的98304个块
这里说明下: fsck 修复文件系统,默认找的是group1的超级块备份来恢复数据,然而,当文件系统group1 损坏时,grup1 是恢复不了的,需要人为手动指定group(n) n 的超级块备份数据来进行恢复,即group3
# tune2fs -l /dev/vdc1 # 查看磁盘设备文件系统详细信息
# dumpe2fs -l /dev/vdc1 # 查看更详细的vdc的内容
其中日志型文件系统 ext3 ext4 xfs NTFSext2 fat32 非日志型文件系统
xfs 文件系统
# xfs_info /dev/vdd1 # 查看xfs 文件系统的详细信息
# dd if=/dev/zero of=/dev/vdc1 bs=4k count=10 # 模拟文件系统损坏
# xfs_repair /dev/vdd1 # xfs_repair 用于修复故障的xfs 文件系统
ext4日志区
only the metadata(default)mount -o data=ordered
Data and metadatamount -o data=journal
Only the metadata, but no guarantee for order of commitsmount -o data=writeback
外部日志区: /dev/vdc1日志区+ block + inode
接下来,我们专门建立一个磁盘用于放 /dev/vdc1 的数据
# tune2fs -O ^has_journal /dev/vdc1
# tune2fs -l /dev/vdc1 | more # 可以看到vdc1 这时没有日志区了,即去掉原设备的日志区
# mke2fs -O journal_dev -b 4096 /dev/vdd1 # 把/vdd1格式化成一个专有的日志区设备
# tune2fs -j -J device=/dev/vdd1 /dev/vdc1 # 把 /vdd1做为/vdc1的一个专有日志区
xfs日志区
# mkfs.xfs -l logdev=/dev/vdd1 /dev/vdc1
# mount -o logdev=/dev/vdd1 /dev/vdc1 /data
# vim /etc/fstab
/dev/vdc1 /data xfs defaults,logdev=/dev/vdd1 0 0
# mount -a
衡量一个存储的性能应该从 IOPS、带宽、时延三个方面来考虑
磁盘预取策略
当磁盘读100的时候,会把101 102 103 104预取到缓存中,那下次过来读数据的时候,这个数据正好在缓存中,那么这样就命中。
智能预取策略: 默认为智能预取策略,当遇到顺序IO的时候,就预取,如果是随机IO则不预取;
可变预取策略: 倍数据预取,读100数据的时候,则100数据大小*4
固定预取策略: 64K 128K 那么每次预取的大小都是相同的
不预取: 随机IO不预取
在Linux 系统当中则使用预取策略
# cat /sys/block/vda/queue/read_ahead_kb
# vim /usr/lib/tuned/throughput-performance/tuned.conf
readahead=>4096
修改以上值可以下次开机,或者重新配置调优的策略时生效
一般raid卡做了缓存的时候,磁盘就不需要再做缓存了
JBOD 直通模式,不经过RAID卡,直接通到操作系统,这种情况会在分布式存储下会用到
即多个磁盘直接交给分存式存储软件来解决副本的,而并非是RAID
IO的队列长度
# Queue length
# /sys/block/sda/queue/nr_requests # 队列整合完了,要写在磁盘中去
# Scheduler algorithm
# /sys/block/sda/queue/scheduler
磁盘调度算法
单队列架构下,常用的调度算法有3种: noop, deadline 和cfq
- noop
noop 只会对请求做一些简单的排序,其本质就是一个FIFO的队列,只会简单地合并临近的IO请求后,本质还是按先来处理的原则提交给磁盘。 - cfq 完全公平原则
CFQ算法会为每个进程单独创建一个队列,保存该进程产生的所有IO请求。不同队列之间按时间片来高度,以此保证每个进程都能很好的分到I/O带宽。这IO的时间版调度跟进程高度是非常相似的,进程调度有进程优先级,而IO调也有IO优先级。
CFQ的出发点是对IO地址进行排序,以尽量少的磁盘旋转次数来满足尽可能多的IO请求。在CFQ算法下,SAS盘的吞吐量大大提高了。但是相比于NOOP 的缺点是,先来的IO请求并不一定能被满足,可能会出现饿死的情况。 - deadline 最终期限,更适合处理小的IO
deadline 确保请求在一个用户可配置的时间内得到响应,避免请求饿死。其分别为读IO 和写IO 提供不同的FIFO队列,读FIFO 队列的最大等待时间是500ms,写FIFO队列的最大等待时间是5s。deadline会把提交时间相近的请求放在一批。在同一批中,请求会被排序。当一批请求达到了大小上限或着定时器超时,这些请求就会提交到设备队列上去。比如在数据库的应用中,可以使用RAID10 而算法则使用 deadline,OLTP: 联机事物处理,交易型。OLAP:联机分析处理大IO,而RAID5有写惩罚的机机制,会有频繁的数据库读写操作,这样就是灾难性的,RAID5更适应用于视频监控,数据备份等。
# ionice -p1
# ionice -p1 -n7 -c2
- 为什么 deadline 调度算法适用于数据库?
deadline 是一种以提高机械硬盘吞吐量为思考出发的点的调度算法,所以准确来说,deadline调度算法适用于IO压力比较重,且业务功能单一的场景,而数据库毫无疑问是最为切尔西的场景了。 - 桌面系统: qq 微信 word excel等众多应用需要响应时,则cfq的调度算法更为合适。
SSD noop 减少CPU开销,磁盘是通过存储LUN映射过来的,LUN已经在存储上优化过,在主机端不需要优化。
红帽8 mq-deadlinefio红帽8自带的IO性能测试工具fio --name=randwrite --ioengine=libaio --iodepth=1 --rw=randwrite --bs=4k --durect=1 --size=512M --numjobs=2 --group_reporting --filename=/data/testfile1
网络调优
BDP 运算公式
当100M带宽延迟为2s的情况下
100 Megaits/s * 2s = (100 * 10^6)/8 * 2 = 25000000 bytes
# vim /etc/sysctl.conf
net.core.rmem_max = 25000000
net.ipv4.tcp_rmem = 4096 12500000 25000000
# 最小值 默认值(默认值为最大值的一半 最大值)
ethtool eth0 查看网卡支持信息
协商速度的检测
node1
# qperf 124.70.61.234 tcp_bw udp_bw
node2
# qperf
追踪一个命令的执行过程,比如ssh连接一台服务器比较慢时,可以通过命令追踪来判断它卡在哪里
# strace ssh 192.168.9.101
# strace -c ssh 192.168.9.101 # 可以统计出耗时最长的是open 文件 read 文件
# strace -e open ssh 192.168.9.101 # 追踪open了哪些文件,可以看到/etc/nsswitch.conf来做解析,用ip地址无法给解析成主机名,这样提供的解决方法就是要么解决DNS的问题,要么sshd的服务中不使用DNS
# vim /etc/ssh/sshd_config
UseDNS no
# systemctl restart sshd
# 再次执行ssh 192.168.9.101 发现速度会很快
shm 共享内存
kernel.shmall = 18446744073692774399 系统中所有共享内存大小,即不得超过的使用内存内存大小kernel.shmmax = 18446744073692774399 每个共享内存的大小,即每个SGA区域不得超过的内存大小kernel.shmmni = 4096 共享内存段数量ipcs -l 查看共享内存的状态
内核模块环境编译与装载
在特定环境中,编译好内核模块后,将其装载至所有的生产环境
- 在开发机器上安装编译所需要的软件包
# yum -y install gcc systemtap kernel-devel kernel-debuginfo # stap -v -p 4 -m iotop.ko /usr/share/systemtap/examples/io/iotop.stp # staprun iotop.ko # 在管理员的账户下则可以直接运行iotop.ko 这个模块 # scp iotop.ko root@serverb:/data - 在生产服务器上
在管理员的情况下就可以直接运行了,然普通用户运行则# yum -y install systemtap-runtime # staprun /data/iotop.ko# usermod -aG stapusr user2 # cp /data/iotop.ko /lib/modules/4.18.0-80.el8.x86_64/systemtap/ # su - user2 # staprun iotop


