






[toc]
D0260-Ceph存储详解

Ceph 原理及架构
存储类型
- 块存储
- 文件系统存储
对象存储
集中式存储
- DAS
- SAN
- NAS
分布式存储
- moosefs
- glusterfs
- ceph
Ceph起源与特性
Ceph简介
Ceph是提供了软件定义的,统一存储解决方案的开源项目
Ceph是一个分布式、可扩展、高性能、不存在单点故障的存储系统(支持PB级规模数据)
同时支持块存储、文件系统存储、对象存储(兼容swift和S3协议)
Ceph起源
- Ceph项目起源于Sage Weil 2003年在加州大学圣克鲁兹分校攻读博士期间的研究课题《Lustre环境中的可扩展问题》
- (2006年,Ceph以LGPLv2协议开源
- 2011年,Inktank公司成立并资助上游开发,并通过其Inktank Ceph Enterprise产品为Ceph提供商业支持
- 2014年,Redhat收购Inktank,Inktank Ceph Enterprise也变为红帽Ceph存储
Ceph的特性
- 每个组件都可扩展(高扩展性)
- 无任何单点故障(高可靠)
- 可以运行在任何普通的商业硬件之上
- 每个组件都尽可能的拥有自我管理和自我修复的能力
Ceph发行版
- 开源Ceph发行版
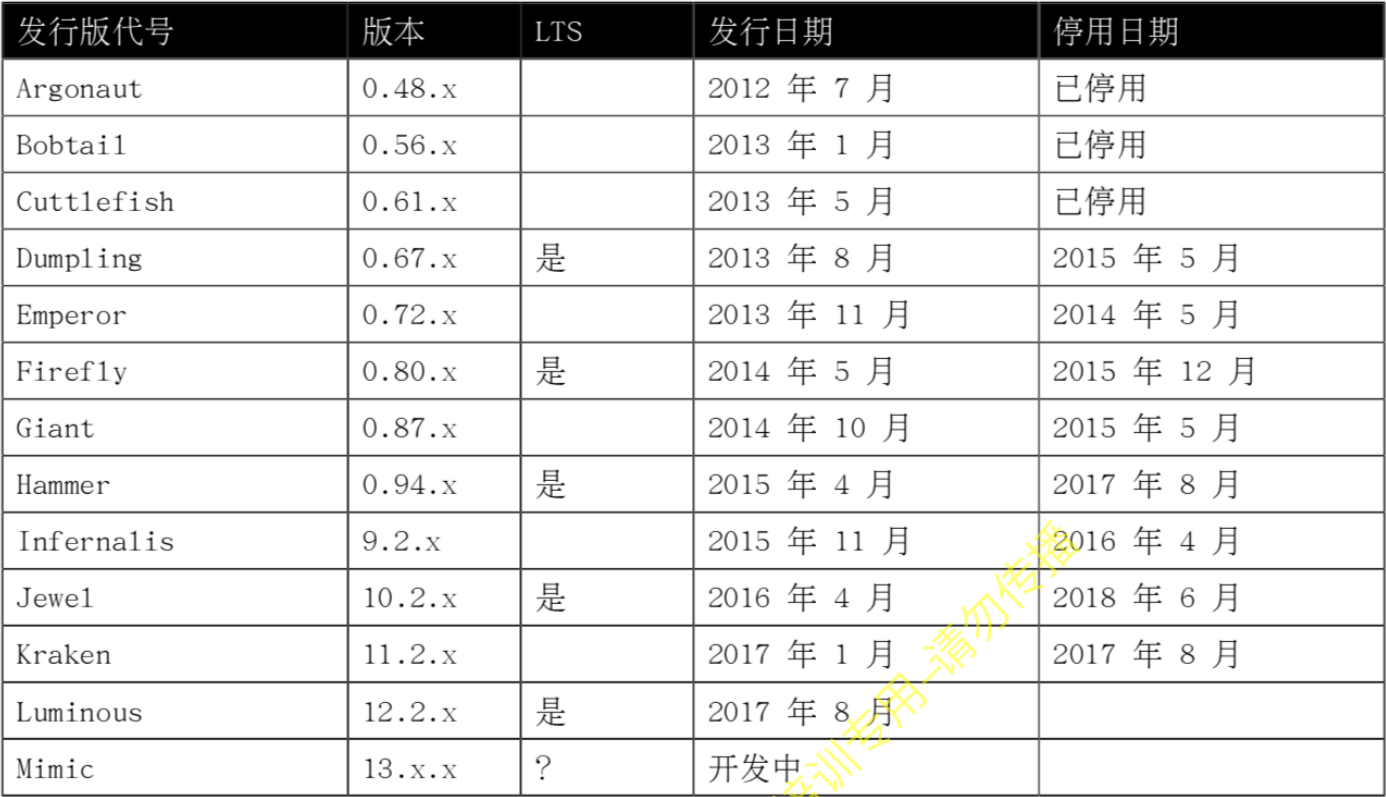
- 红帽Ceph存储发行版
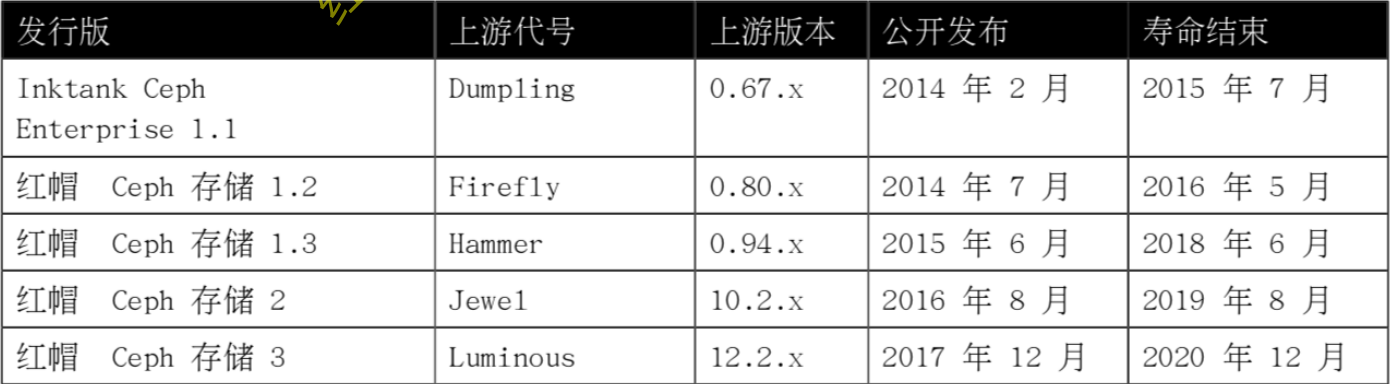
Ceph存储后端组件
- Monitors(MON):维护集群状态的map,帮助其他守护进程互相协调
- Object Storage Devices(OSD):存储数据,并且处理数据复制、恢复和再平衡
- Managers(MGR):通过Web浏览器和REST API,跟踪运行指标并显示集群信息
- Metadata Servers(MDS):存储供CephFS使用的元数据,能让客户端高效执行POSIX命令
- Ceph Monitors
- Ceph monitor通过保存一份集群状态映射来维护整个集群的健康状态。它分别为每个组件维护映射信息,包括OSD map、MON map、PG map和CRUSH map
- 所有集群节点都向MON节点汇报状态信息,并分享它们状态中的任何变化
- Ceph monitor不存储数据
- MON需要配置为奇数个,只有超过半数正常,Ceph存储集群才能运行并可访问
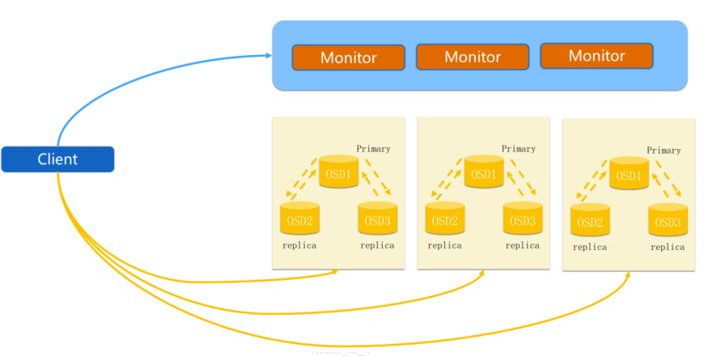
- Ceph OSD
- OSD是ceph集群的数据存储组件
- 通常,一个OSD守护进程绑定一块磁盘。所以在通常情况下,Ceph集群中的物理磁盘的总数与OSD进程数相同
- ceph通过crush算法将对象存储至osd中
- 对象被自动复制到多个OSD,OSD又被分为primary osd和secondary osd,客户端只会读到primary OSD
- Ceph MGR
- MGR提供一系列集群统计数据,在较旧版本的Ceph中,这些数据大部分是由MON收集和维护,负载太高
- 如果集群中没有MGR,不会影响客户端I/O操作,但是将不能查询集群统计数据。建议每集群至少部署两个MGR
- MGR将所有收集的数据集中到一处,并通过tcp的7000端口提供一个简单的web界面
- Ceph MDS
- MDS只为CephFS文件系统跟踪文件的层次结构和存储元数据。MDS不直接提供数据给客户端,从而消除了系统中故障单点。
- MDS本身只在内存中缓存元数据以加速访问
- 访问CephFS的客户端首先向MDS发出请求,以便从正确的OSD获取文件
ceph数据写入流程:ceph寻址流程
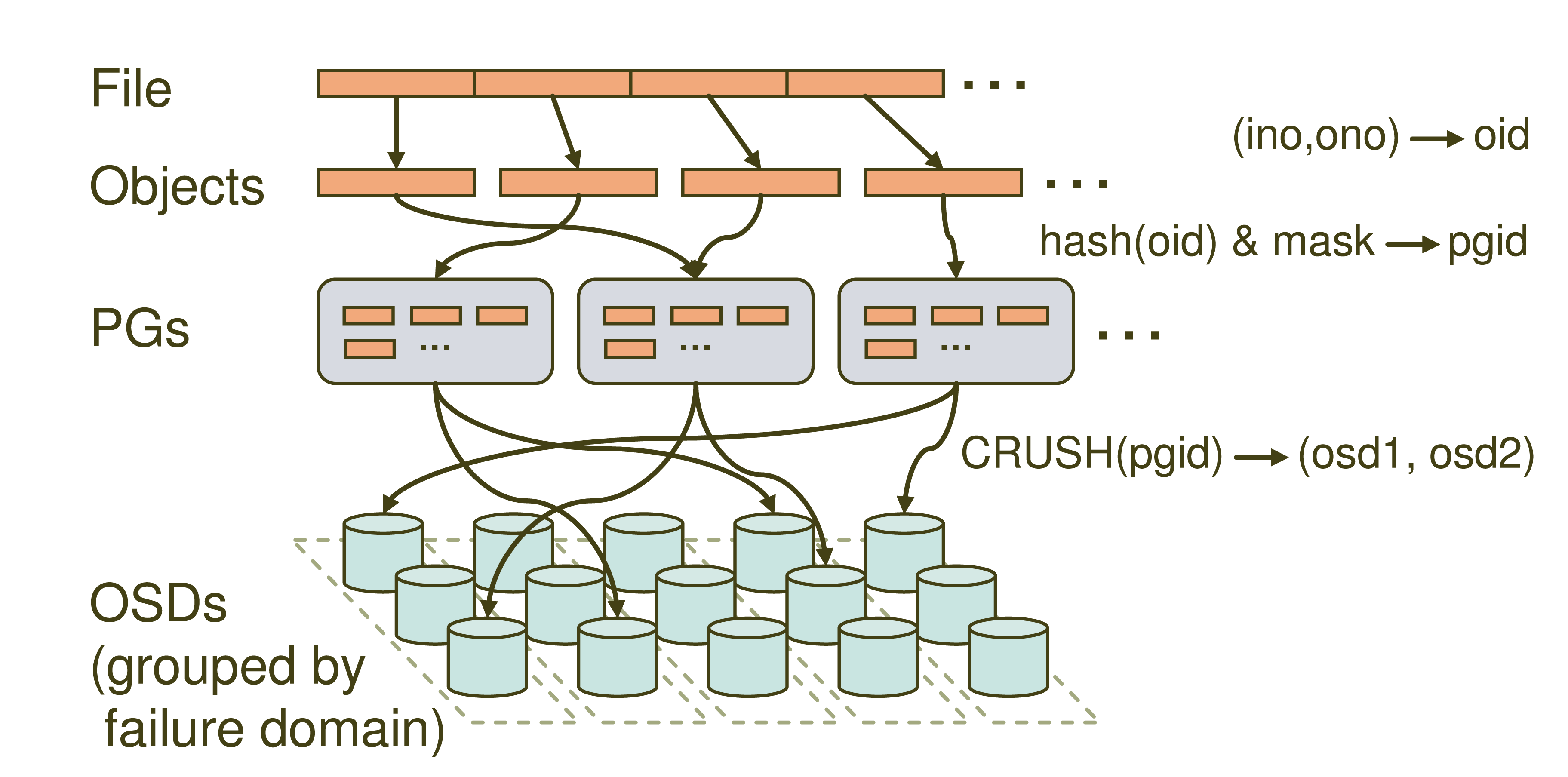
- Ceph数据写入流程:正常写入
- client 创建cluster handler
- client 读取配置文件
- client 连接上monitor,获取集群map信息
- client 读写io 根据crush map算法请求对应的主osd数据节点
- 主osd数据节点同时写入另外两个副本节点数据
- 等待主节点以及另外两个副本节点写完数据状态
- 主节点及副本节点写入状态都成功后,返回给client,io写入完成
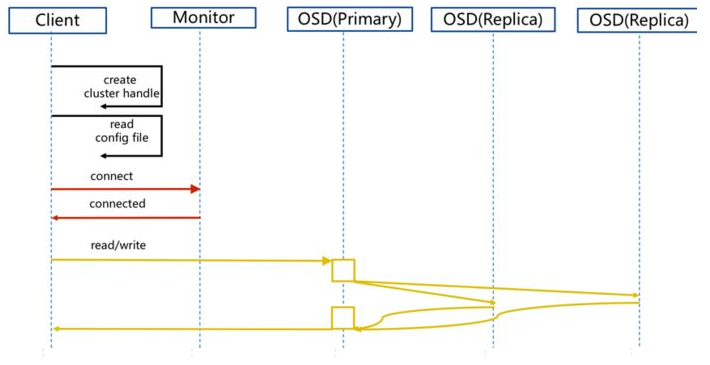
- Ceph数据写入流程:主OSD异常
- client连接monitor获取集群map信息
- 同时新主osd1由于没有pg数据会主动上报monitor告知让osd2临时接替为主
- 临时主osd2会把数据全量同步给新主osd1
- client IO读写直接连接临时主osd2进行读写
- osd2收到读写io,同时写入另外两副本节点
- 等待osd2以及另外两副本写入成功
- osd2三份数据都写入成功返回给client, 此时client io读写完毕
- 如果osd1数据同步完毕,临时主osd2会交出主角色
- osd1成为主节点,osd2变成副本
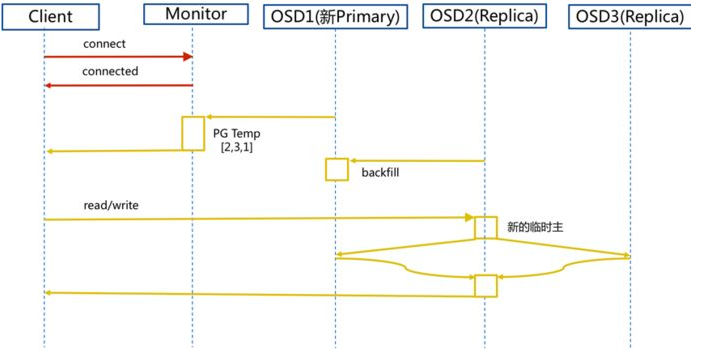
- Ceph数据读取流程
Ceph安装与扩容
生产环境最低配置
至少三个MON节点
至少三个OSD节点(每节点可以有多个OSD进程)
至少两个MGR节点
如果使用CephFS,至少需要两个配置完全相同的MDS节点
如果使用Ceph RADOSGW,则至少需要两个RGW节点
最底硬件要求
- MON 1个MON进程至少需要1 GHz CPU、1GB内存、10GB磁盘以及2Gbps的网络带宽
- OSD 1个OSD进程至少需要1 GHz CPU、1GB内存、一块磁盘以及2Gbps的网络带宽
- MDS 1个MDS进程至少需要1 GHz CPU 、1GB内存、1MB磁盘以及2Gbps的网络带宽
- RGW 1个RGW进程至少需要1 GHz CPU 、1GB内存、5GB磁盘以及2Gbps的网络带宽
注意事项
- OSD磁盘不应该使用RAID,Ceph使用复制或纠删码来保护数据
- 在生产环境部署Ceph集群,为便于管理,OSD主机应尽量使用统一的硬件。尽可能配置数量、大小和名称都相同的磁盘,有助于确保性能一致,并且简化故障排除
- 需要确认每个OSD主机提供的OSD的数量。密度较小的存储集群意味着osd守护进程分布到更多的主机上,分发工作负载。密度较高的存储意味着重平衡和数据恢复需要更高的流量
部署方式
- 纯手动部署
- 部署极其复杂
- 便于初学者理解具体的工作机制
- ceph-deploy
- ceph官方推荐的部署方式
- ceph-ansible
- 红帽官方推荐的部署方式
- cephadm
- O版后支持的部署方式,以容器的方式部署
- 红帽Ceph新版本推荐的部署方式
准备工作
- 配置软件仓库(centos epel源、ubuntu apt源、redhat使用subscription-manager命令注册系统)
- 所有节点配置网络及NTP时间同步
- 关闭selinux与防火墙
- 在部署节点安装ansbile
- 添加hosts
- 配置部署节点到其他所有节点的ssh免密登录
- 验证部署节点能够在集群节点上运行ansible任务
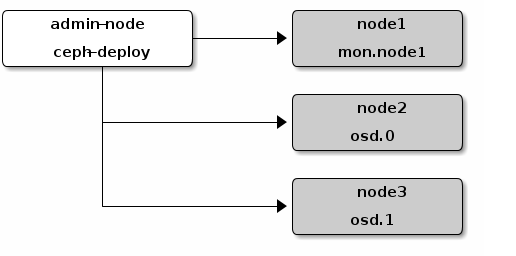
配置ceph-ansible
- 安装
yum install -y ceph-ansible ceph-ansible会被安装到/usr/share/ceph-ansible目录- 配置
- 修改ansible清单文件
- 修改
/usr/share/ceph-ansible/group_vars/all.yml组变量文件 - 修改
/usr/share/ceph-ansible/group_vars/osds.yml组变量文件 - 修改
/usr/share/ceph-ansible/group_vars/clients.yml组变量文件 - 修改
/usr/share/ceph-ansible/site.yml文件
- 部署ceph集群
ansible-playbook -i hosts site.yml
ansible清单文件配置示例
[mons]
monitor-host-name
[mgrs]
manager-host-name
[osds]
osd-host-name
group_vars/all.yml配置示例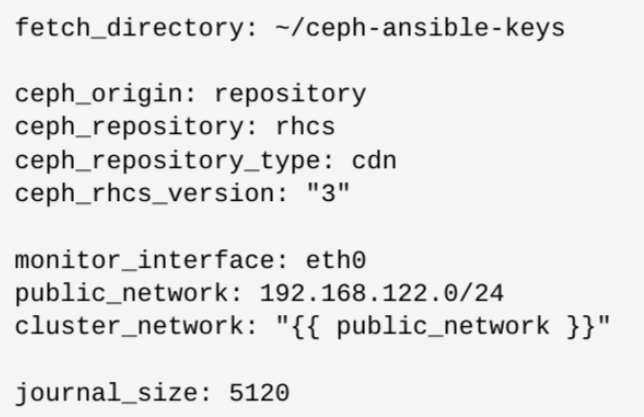
可以将
group_vars/all.yml中将common_single_host_mode设置为true,用于部署一个单节点ceph集群用于测试和学习group_vars/all.yml文件中的ceph_conf_overrides参数,可以覆盖ceph配置默认值:ceph_conf_overrides: section_name: ceph_parameter_name: value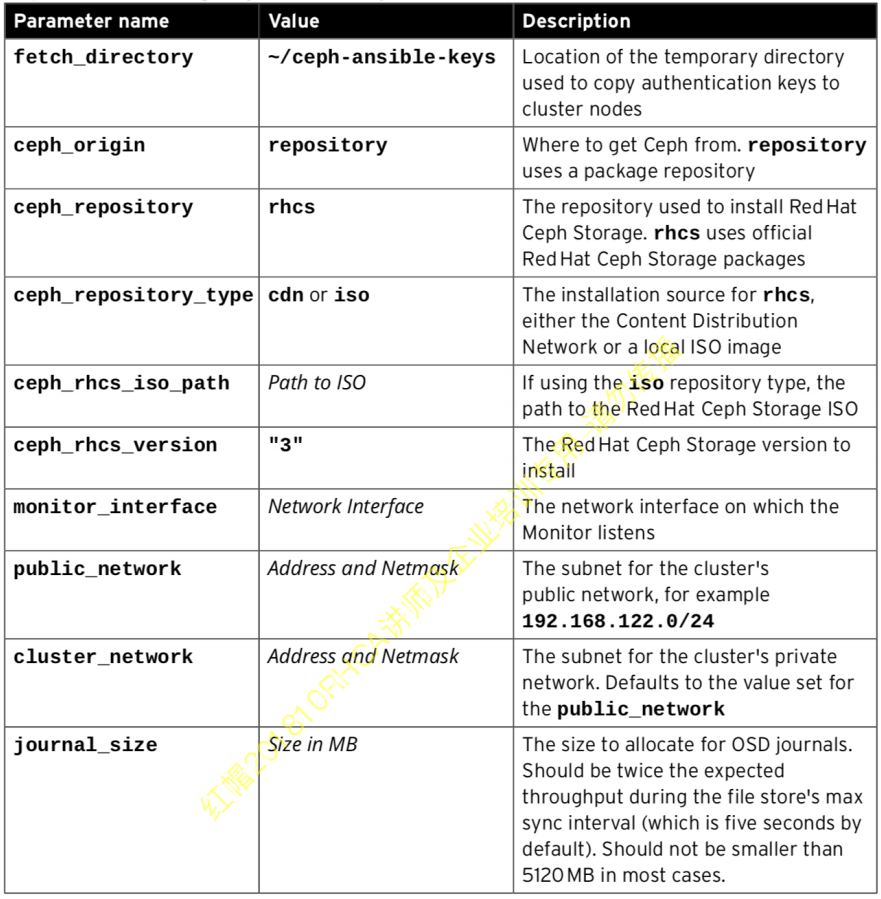
配置OSD
- 并置方案:假定所有OSD主机具有相同的硬件并使用相同的设备名称
group_vars/osds.yml配置示例:
- 非并置方案:将不同的存储设备用于OSD数据和OSD journal
group_vars/osds.yml配置示例:
组件端口说明
- Mon 6789/TCP:Communication within the Ceph cluster
- Mgr 6800/TCP:事件监听主线程,等待外界输入事件,并分派给各个处理者
- 7000/TCP:dashboard监听端口
- OSD 6800-7300/TCP:每个osd监听四个端口:
- 一个用于和与monitor和client通讯
- 一个用于多个osds之间同步数据
- 两个用于在各个网络之间传递心跳
Ceph集群基本操作
- 查看集群状态
ceph -s
- 监视集群状态
ceph -w
- 查看集群使用的空间状态
ceph df
- 查看osd使用率
ceph osd df
扩容集群容量
- 在不中断服务的前提下,扩展ceph集群存储容量
- 可通过ceph-ansible以两种方式扩展集群中的存储:
- 可以添加额外OSD主机到集群(scale-out)
- 可以添加额外存储到现有的OSD主机(scale-up)
- 开始部署额外的OSD前,需确保集群处于HEALTH_OK状态
- 通
cephadm以容器方式安装组件的扩容
配置ansible清单
[osds]
existing-osd-1
existing-osd-2
new-osd-1
new-osd-2
- 配置
group_vars/osds.yml 并置方案与非并置方案

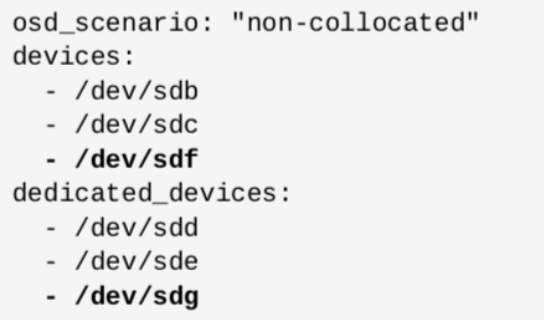
修改完成后,再次执行如下操作:
ansible-playbook -i hosts site.yml
Ceph 存储池
存储池说明
- 池是ceph存储集群的逻辑分区,用于存储对象
- 池具有特定的属性
- 池类型:一种用于提供数据冗余,一种用于提升数据的存取效率
- PG数量:将对象存储到由CRUSH算法决定的一组OSD中
- 访问级别:不同用户的访问权限
- 对象存储到池中时,使用CRUSH规则将该对象分配到池中的一个PG,PG根据池的配置和CRUSH算法自动映射到一组OSD
- 池中PG数量对性能有重要影响。通常而言,池应当配置为每个OSD包含100-200个归置组
- 创建池时,ceph会检查每个OSD的PG数是否超过200。如果超过,ceph不会创建这个池。(200的限制可通过mon_max_pg_per_osd参数修改)
- Ceph 3.0安装时不创建存储池
- 存储类型
- 用于提供数据冗余
- 复制池
- 纠删码池
- 用于提升数据读写效率
- 缓存池
- 用于提供数据冗余
创建复制池
ceph osd pool create <pool-name> <pg-num> [pgp-num] [replicated] [crush-rule] [expected-num-objects]
pool-name存储池的名称pg-num存储池的pg总数pgp-num存储池的pg的有效数,通常与pg相等replicated指定为复制池,即使不指定,默认也是创建复制池crush-rule用于这个池的crush规则的名字,默认为replicated_ruleexpected-num-objects池中预期的对象数量。如果事先知道这个值,ceph可于创建池时在OSD的文件系统上准备文件夹结构。否则,ceph会在运行时重组目录结构,因为对象数量会有所增加。这种重组一会带来延迟影响
为池启用ceph应用
- 创建池后,必须显式指定能够使用它的ceph应用类型:
- ceph块设备
- ceph对象网关
- ceph文件系统
- 如果不显示指定类型,集群将显示HEALTH_WARN状态(使用ceph health detail命令查看)
为池关联应用类型:ceph osd pool application enable pool-name app- cephfs
- rbd
- rgw
示例:ceph osd pool application enable myfirstpool rbd
列出集群中的池
- 列出存储池
ceph osd lspoolsceph osd pool ls detail
- 获取池统计信息
ceph df:获取池用量统计数据ceph osd df:获取osd上磁盘使用量统计数据ceph osd pool stats:获取池性能统计数据
设置池配额
- 语法
ceph osd pool set-quota pool-name [max_objects <obj-count>] [max_bytes bytes]
- 示例
ceph osd pool set-quota myfirstpool max_objects 1000
- 可将值设置为0来删除配额。同时通过ceph osd df命令查看池的用量统计数据
- 当ceph达到池配额时,操作会被无限期阻止
重命名池
- 语法
ceph osd pool rename current-name new-name
- 示例
ceph osd pool rename mysecondpool mytestpool
- 重命名池,不影响池中的数据
向池中写入数据

创建池快照
- 创建快照
ceph osd pool mksnap pool-name snap-name
- 删除快照
ceph osd pool rmsnap pool-name snap-name
- 回滚快照
rados -p pool-name -s snap-name get object-name filerados -p pool-name rollback object-name snap-name
修改池参数
- 设置池参数
ceph osd pool set pool-name parameter value
- 获取池参数
ceph osd pool get pool-name parameter
- 列出所有参数及其值
ceph osd pool get pool-name all
删除池
- 删除池
ceph osd pool delete pool-name pool-name --yes-i-really-really-mean-it
- 在红帽ceph 3中,已将
mon_allow_pool_delete配置参数设置为false,以提供额外的保护。即使借助--yes-i-really-really-mean-it选项,ceph osd pool delete命令也不会导致池被删除 - 可以将
mon_allow_pool_delete参数设置为true,然后重启mon服务,以允许删除池 - 即使
mon_allow_pool_delete被设置为true,也可以通过在池级别上将nodelete选项设置为true来防止池被删除:ceph osd pool set pool-name nodelete true
在池中配置命名空间
- namespace是池中对象的逻辑组。可以限制用户对池的访问,使得用户只能存储或检索这个namespace内的对象
- namesapce的优点是能够使将用户访问权限池的某一部分
- namespace目前仅支持使用librados的应用
- 若要在命名空间内存储对象,客户端应用必须提供池和命名空间的名称
- 默认情况下,每个池包含一个具有空名称的namespace,称为默认namespace
- rados命令可以通过-N name或者—namespace=name选项存储和检索池中指定命名空间的对象
- 示例
rados -p mytestpool -N system put srv /etc/servicesrados -p mytestpool -N system lsrados -p mytestpool --all ls
纠删码池工作原理
- 纠删码的存储方法是将每个object划分成更小的数据块,每一个数据块称为data chunk,再用编码块(coding chunk)对它们进行编码,最后将这些数据块和编码块存储到Ceph集群的不同故障域中,从而保证数据安全。纠删码概念的核心公式n=k+m,解释如下:
- k:原始object被划分成的数据块的个数
- m:附加到所有原始数据块的额外编码块的个数
- n:执行纠删码处理后,所创建的块的总数
纠删码相关术语
- 恢复(recovery):执行数据恢复时,需要n个块中的任意k个块来恢复数据
- 可靠性等级(reliability level):通过使用纠删码,对于每个对象,ceph能容忍m个块出错。
- 编码率(Endoing Rate(r)): 编码率公式r=k/n,r小于1。
- 所需存储(Storage required):可以使用公式1/r计算。
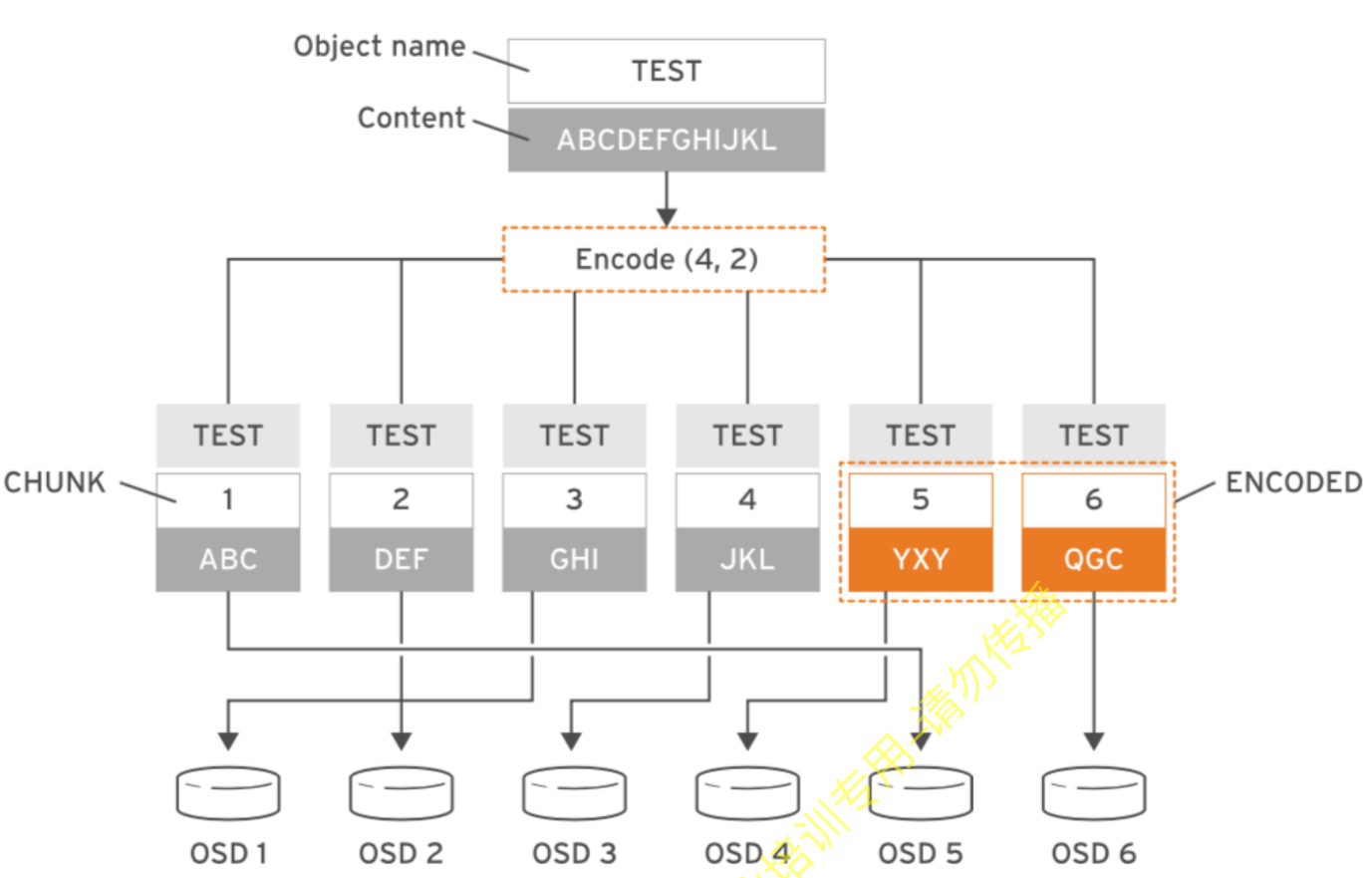
创建纠删码池
- 语法
ceph osd pool create <pool-name> <pg-num> [pgp-num] erasure [erasure-code-profile] [cursh-ruleset-name] [expected_num_objects]erasure用于指定创建一个纠删码池erasure-code-profile是要使用的profile的名称,可以使用ceph osd erasure-code-profile set命令创建新的profile。profile定义使用的插件类型以及k和m的值。默认情况下,ceph使用default profile
- 示例
ceph osd pool create mysecondpool 50 50 erasure
纠删码profiles
erasure code profile配置纠删码池用于存储对象的数据区块和编码区块的数量,以及要使用的纠删码插件和算法- 管理员可以创建新的profile来定义新的纠删码参数。
default profile配置为将对象分割为两个数据区块和一个编码区块 - ceph通过一个基于插件的系统来控制纠删码实施,也创建了多个管理纠删码的插件。default profile使用Jerasure插件,是最为灵活的通用选项,另外还有LRC(Locally repairable erasure code plugin)以及SHEC(Shingled erausure code pluing)
- 红帽Ceph 3支持Jerasure和LRC插件
查看纠删码profile
- 列出当前集群中的profile:
ceph osd erasure-code-profile ls
- 查看指定profile的内容:
ceph osd erasure-code-profile get <profile-name>- 示例:
ceph osd erasure-code-profile get default
创建纠删码Profile
ceph osd erasure-code-profile set EC-profile crush-failure-domain=osd k=3 m=2- k:一个对象拆成多少个数据块。默认值为 2
- m:允许最大故障的OSD数目。默认值为1
- directory:插件库的位置。默认值为 /usr/lib64/ceph/erasure-code
- plugin:定义要使用的纠删代码插件。默认值为jerasure
- crush-failure-domain:定义CRUSH故障域,它控制区块放置。默认情况下,为host,这可以确保对象的区块放置到不同主机的OSD上。如果设置为osd,则对象的区块可以放置到同一主机的OSD上。将故障域设置为osd时弹性欠佳,如果主机出现故障,则该主机上的所有OSD都会失败。设置为rack可以确保ceph不会将两个区块存储在不同的机架中。
- crush-device-class:仅将某一类别设备支持的OSD用于池。典型的类别可能包括hdd、ssd 或nvme
- crush-root:设置CRUSH规则集的根节点
- key=value:自定义键值对
- technique:每个插件提供一组不同的技术来实施不同的算法。对于Jerasure插件,默认的技术是reed_sol_van。还提供其他的技术:reed_sol_r6_op、cauchy_orig、cauchy_good、liberation、blaum_roth和liber8tion
- 使用指定profile创建纠删码池
- 示例:
ceph osd pool create mysecond 128 128 erasure EC-profile - 说明: 无法修改或更新现有纠删码池的profile
删除纠删码profile
- 删除现有的配置
ceph osd erasure-code-profile rm <profile-name>
纠删码池操作
- 查看纠删码池状态
ceph osd dump |grep -i EC-pool
- 添加数据到纠删码池
rados -p EC-pool lsrados -p EC-pool put object1 hello.txt
- 查看数据状态
ceph osd map EC-pool object1
- 读取数据
rados -p EC-pool get object1 /tmp/object1
Ceph配置说明
Ceph配置文件说明
- 默认情况下,无论是ceph的服务端还是客户端,配置文件都存储在/etc/ceph/ceph.conf文件中
- 如果修改了配置参数,必须使/etc/ceph/ceph.conf文件在所有节点(包括客户端)上保持一致。
- ceph.conf 采用基于 INI 的文件格式,包含具有 Ceph 守护进程和客户端相关配置的多个部分。每个部分具有一个使用 [name] 标头定义的名称,以及键值对的一个或多个参数
- 配置文件使用#和;来注释
- 参数名称可以使用空格、下划线、中横线来作为分隔符。如osd journal size 、 osd_jounrnal_size 、 osd-journal-size是有效且等同的参数名称
- 通过中括号将特定守护进程的设置分组在一起:
- [global] 部分,存储所有守护进程之间通用配置。它应用到读取配置文件的所有进程,包括客户端。可以在更为具体的部分中覆盖此处设置的参数
- [mon] 部分,监视器 (MON) 相关的配置
- [osd] 部分,OSD 守护进程相关的配置
- [mgr] 部分,管理器 (MGR) 相关的配置
- [mds] 部分,元数据服务器 (MDS) 相关的配置
- [client] 部分,所有客户端的配置
- 配置示例
/usr/share/doc/ceph/sample.ceph.conf
元变量
- 所谓元变量是即Ceph内置的变量。可以用它来简化ceph.conf文件的配置:
- $cluster:Ceph存储集群的名称。默认为ceph,在
/etc/sysconfig/ceph文件中定义。例如,log_file参数的默认值是/var/log/ceph/$cluster-$name.log。在扩展之后,它变为/var/log/ceph/ceph-mon.ceph-node1.log
*$type:守护进程类型。监控器使用mon;OSD使用osd,元数据服务器使用mds,管理器使用mgr,客户端应用使用client。如在[global]部分中将pid_file参数设定义为/var/run/$cluster/$type.$id.pid,它会扩展为/var/run/ceph/osd.0.pid,表示ID为0的 OSD。对于在ceph-node1上运行的MON守护进程,它扩展为/var/run/ceph/mon.ceph-node1.pid
$id:守护进程实例ID。对于ceph-node1上的MON,设置为ceph-node1。对于osd.1,它设置为1。如果是客户端应用,这是用户名
$name:守护进程名称和实例ID。这是$type.$id的快捷方式
$host:其上运行了守护进程的主机的名称
- $cluster:Ceph存储集群的名称。默认为ceph,在
实例设置
- 管理员可以将配置应用到特定守护进程
- 名称采用
[daemon-type.instance-ID]形式。例如,对于serverc上的监控器,可以写成[mon.serverc]
- 上述示例同样适用于[osd]、[mgr]、[mds]和[client]部分* OSD守护进程的实例ID始终是数字,例如[OSD.0]
- 客户端的实例ID是用户名,例如[client.admin]
定义全局参数
[global]
fsid = 23078e5b-3f38-4276-b2ef-7514a7fc09ff
# 设置为monitor的列表,这些monitor必须在集群启动时处于就绪状态以便能建立仲裁mon_initial_members = ceph-node1,ceph-node2,ceph-node3
# monitor的列表
mon_host = 192.168.31.122,192.168.31.91,192.168.31.124
# ceph组件之间启用cephx认证
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
public_network=10.5.10.0/24
cluster_network=10.5.10.0/24
osd_pool_default_size = 3
osd_pool_default_min_size = 2
osd_pool_default_pg_num = 100
osd_pool_default_pgp_num = 100
查看运行时配置
- 列出所有参数及其当前值
- 语法:
ceph daemon type.id config show - 示例:
ceph daemon osd.0 config show
- 语法:
- 获取具体参数的值
- 语法:
ceph daemon type.id config get parameter - 示例:
ceph daemon mds.servera config get mds_data
- 语法:
使用ansible管理ceph配置文件
- 所有ceph节点上的
/etc/ceph/ceph.conf配置文件都需要保持一致(包括客户端) - 如果配置文件有修改,可使用ansible统一推送
- 修改
group_vars/all.yml,示例如图 - 重新执行playbook:
ansible-playbook site.yml
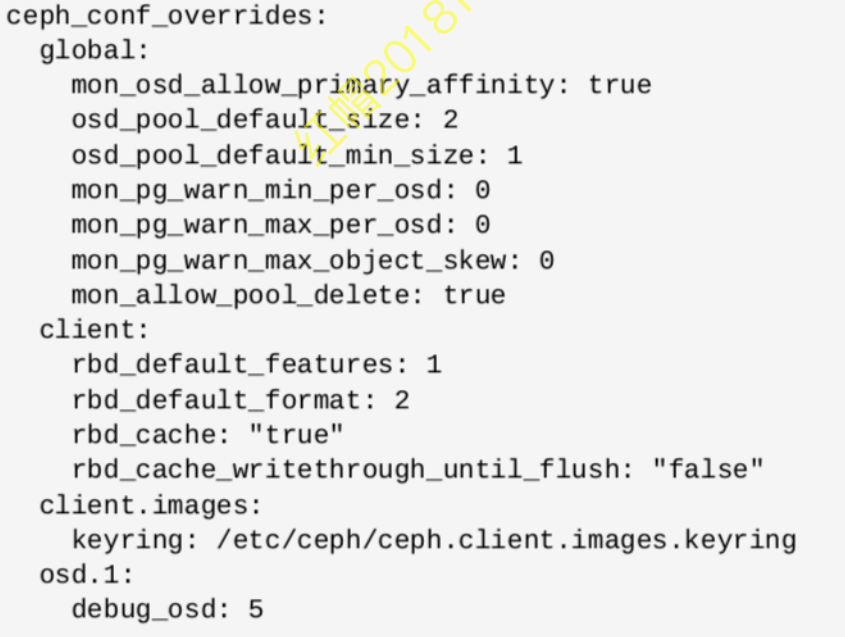
Ceph守护进程启停操作
| Managing Ceph daemons with systemd | |
|---|---|
| Stop a specific daemon | systemctl stop ceph-$type$id |
| Stop all OSD daemons | systemctl stop ceph-osd.target |
| Stop all daemons | systemctl stop ceph.target |
| Stop a specific daemon | systemctl start ceph-$type$id |
| Start all OSD daemon | systemctl start ceph-osd.target |
| Start all daemon | systemctl start ceph.target |
| Restart a specific daemon | systemctl restart ceph-$type$id |
| Restart all OSD daemons | systemctl restart ceph-osd.target |
| Restart all daemons | systemctl rstart ceph.target |
Ceph认证与授权
Ceph认证说明
Ceph认证机制
- None:这种模式下,任何用户可以在不经过身份验证时就访问Ceph集群
auth_cluster_required = noneauth_service_required = noneauth_client_required = none
- Cephx:Cephx协议类似于Kerberos协议,它允许经过验证的客户端访问ceph集群
auth_cluster_required = cephxauth_service_required = cephxauth_client_required = cephx
Ceph密钥创建机制
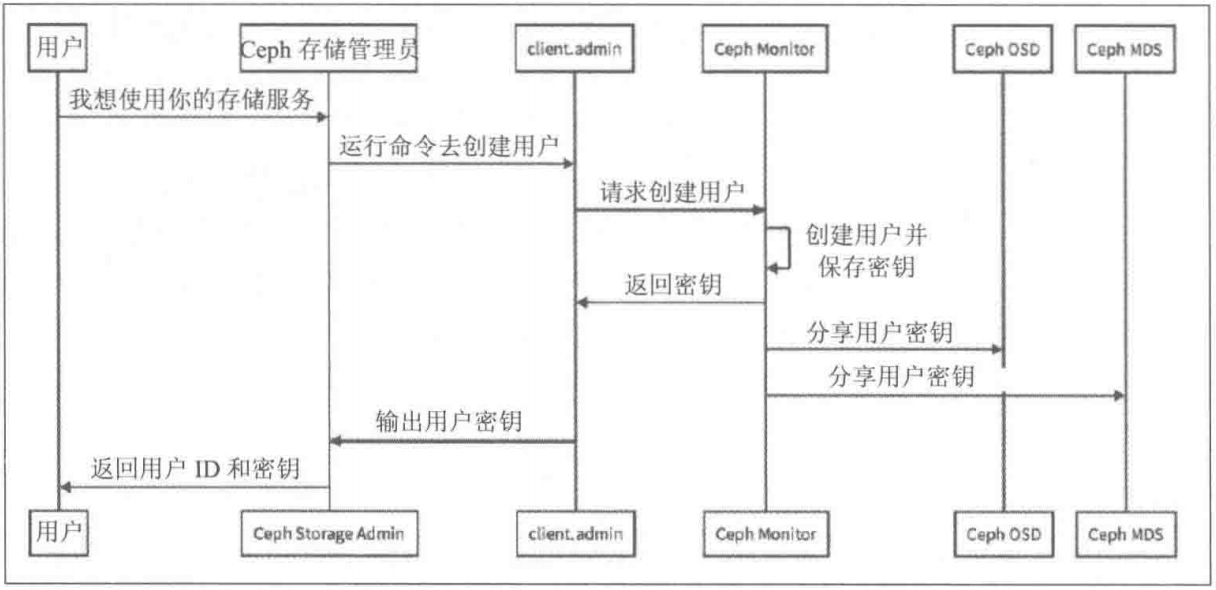
Ceph身份验证过程
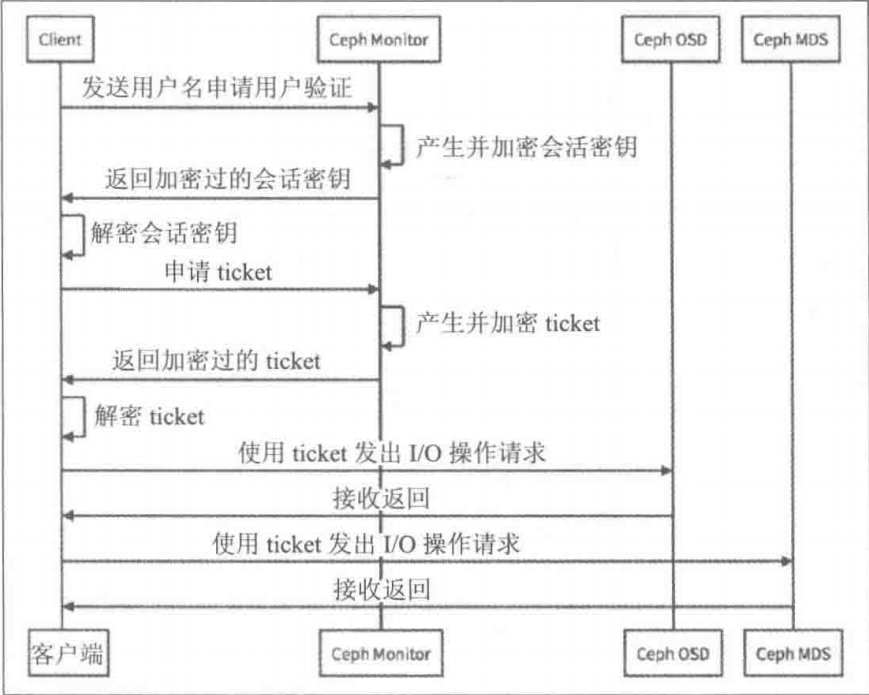
Ceph授权
- Ceph把数据以对象的形式存于各存储池中,Ceph用户必须具有访问存储池的权限才能够读写数据
- Ceph用caps来描述给用户的授权,这样才能使用Mon、OSD和MDS的功能
- caps也用于限制对某一存储池内的数据或某个命名空间的访问
- Ceph管理员用户可在创建或更新普通用户时赋予其相应的caps
Ceph常用权限说明
r:赋予用户读数据的权限,如果我们需要访问集群的任何信息,都需要先具有monitor的读权限w:赋予用户写数据的权限,如果需要在osd上存储或修改数据就需要为OSD授予写权限x:赋予用户调用对象方法的权限,包括读和写,以及在monitor上执行用户身份验证的权限*:将一个指定存储池的完整权限(r、w和x)以及执行管理命令的权限授予用户profile rbd: 授权管理rbd块存储profile osd:授权一个用户以OSD身份连接其它OSD或者Monitor,用于OSD心跳和状态报告profile mds:授权一个用户以MDS身份连接其他MDS或者Monitorprofile bootstrap-osd:允许用户引导OSD。比如ceph-deploy和ceph-disk工具都使用client.bootstrap-osd用户,该用户有权给OSD添加密钥和启动加载程序profile bootstrap-mds:允许用户引导MDS。比如ceph-deploy工具使用了client.bootstrap-mds用户,该用户有权给MDS添加密钥和启动加载程序
Ceph授权对象
- 授权语法:
{daemon-type} allow {capability}' [{daemon-type} 'allow {capability}']
- 授权对象:
monitor caps,包括r、w、x参数以及allow profiles {cap}mon 'allow rwx'mon 'allow profile osd'
osd caps,包括r、w、x、class-read、class-write以及profile osdosd 'allow rw'osd 'allow rw pool=rbd'
- mds
mds 'allow'
授权操作
- 普通授权
mon 'allow r' osd 'allow rw'
- 基于存储池的授权
mon 'allow r' osd 'allow rw pool=myfirstpool'
- 基于对象前缀授权
mon 'allow r' osd 'allow rw object_prefix pref'
- 基于命名空间授权
mon 'allow r' osd 'allow rw pool=myfirstpool namespace=photos'
- 基于路径授权
- 只适用于CephFS,CephFS通过这种方式来限制对特定目录的访问
mon 'allow r' osd 'allow rw pool=cephfs_data' mds 'allow rw path=/webcontent'
- 限制用户只能使用特定的管理员指令
mon 'allow r, allow command "auth get-or-create", allow command "auth list"'
Ceph用户命名规范
- Ceph守护进程使用的帐户名与相关守护进程名称匹配:
osd.1或mon.ceph-node1,这些用户默认会在安装时被创建 librados的客户端应用,帐户名以client.开头。例如,将OpenStack与Ceph集成时,常常会创建专用的client.openstack用户。另外,当部署 Ceph Object Gateway时,会创建client.rgw.帐户。如果要在librados基础上部署自定义软件,也应当创建特定帐户- Ceph客户端所使用的帐户名以client.开头,运行ceph和rados等命令时使用。安装程序会创建超级管理员
client.admin,它具有访问所有内容及修改集群配置的功能。如果运行命令时不通过--name或--id明确指定用户名,Ceph默认使用client.admin
添加用户
ceph auth add- 当用户不存在,则创建用户并授权
- 当用户存在,当权限不变,则不进行任何输出
- 当用户存在,不支持修改权限
- 示例:
ceph auth add client.breeze mon 'allow r' osd 'allow rw pool=myfirstpool'
ceph auth get-or-create- 当用户不存在,则创建用户并授权并返回用户和key
- 当用户存在,权限不变,返回用户和key
- 当用户存在,权限修改,则返回报错
- 示例:
ceph auth get-or-create client.tina mon 'allow r' osd 'allow rw pool=mysecondpool'
ceph auth get-or-create-key- 当用户不存在,则创建用户并授权只返回key
- 当用户存在,权限不变,只返回key
- 当用户存在,权限修改,则返回报错
- 示例:
ceph auth get-or-create client.bernie mon 'allow r' osd 'allow rw pool=mysecondpool'
用户的查询、删除
- 罗列用户
ceph auth list
- 获取某个用户的详细信息
ceph auth get client.admin
- 获取用户的key
ceph auth print-key client.admin
- 删除指定用户
ceph auth del client.breeze
用户的导入导出
- 导出用户
ceph auth get client.breeze -o /etc/ceph/ceph.client.breeze.keyring
- 导入用户
ceph auth import -i /etc/ceph/ceph.client.breeze.keyring
修改用户权限
ceph auth caps用户修改用户授权。如果给定的用户不存在,直接返回报错。如果用户存在,则使用新指定的权限覆盖现有权限。所以,如果只是给用户新增权限,则原来的权限需要原封不动的带上。如果需要删除原来的权限,只需要将该权限设定为空即可。ceph auth get client.breezeceph auth caps client.breeze mon 'allow r' osd 'allow rw pool=liverpool'ceph auth caps client.breeze mon 'allow r'
Ceph密钥管理
- 客户端访问ceph集群时,会使用本地的keyring文件,默认依次查找下列路径和名称的keyring文件:
/etc/ceph/$cluster.$name.keyring/etc/ceph/$cluster.keyring/etc/ceph/keyring/etc/ceph/keyring.bin
推送用户至客户端
- 创建的用户主要用于客户端授权,所以需要将创建的用户推送至客户端。如果需要向同一个客户端推送多个用户,可以将多个用户的信息写入同一个文件,然后直接推送该文件:
# ceph-authtool -C /etc/ceph/ceph.keyring
# ceph-authtool ceph.keyring --import-keyring ceph.client.breeze.keyring
# ceph-authtool ceph.keyring --import-keyring ceph.client.Bernie.keyring
通过命令行使用用户
- 默认情况下,我们直接在用户端执行ceph指令,使用的是client.admin用户。如果在客户端使用指定用户访问ceph集群,就需要在命令行中传递认证信息:
ceph --id breeze --keyring /etc/ceph/ceph.keyring healthceph --user breeze --keyring /etc/ceph/ceph.keyring healthceph --name client.breeze --keyring /etc/ceph/ceph.keyring health
管理Ceph RBD块设备
Ceph RBD特性
- 支持完整和增量的快照
- 自动精简配置
- 写时复制克隆
- 动态调整大小
- 内存内缓存
Ceph RBD挂载
配置RBD示例
- 创建RBD池
ceph osd pool create rbd 50 50ceph osd pool application enable rbd rbd
- 初始化RBD池
rbd pool init rbd
- 创建client.rbd用户
ceph auth get-or-create client.rbd mon 'profile rbd' osd 'profile rbd'
- 创建RBD镜像
rbd create --size 1G rbd/test
- 在客户端映射镜像
rbd map rbd/test --name client.rbd
- 格式化并访问
mkfs.xfs /dev/rbd0
- 挂载镜像
mount /dev/rbd0 /mnt
- 创建并初始化RBD池
# ceph osd pool create <pool-name> <pg-num> [pgp-num]
# ceph osd pool application enable <pool-name> rbd
# rbd pool init -p <pool-name>
创建RBD块设备
rbd create [pool-name/]<image-name> --size <megabytes> --image-format <1|2> --image-feature <image-feature1[,image-feature2,...]> --stripe-unit=1M --stripe-count=4rbd create rbd/data --size 1G --image-format 2 --image-feature layering,exclusive-lock,journaling--size: 指定块设备大小--image-format: 指定块设备类型,默认为2, 1已经废弃(1和2在底层的存储实现上不同)--stripe-unit:块存储中object大小,不得小于4k,不得大于32M,默认为4M(即一个对象的大小)--stripe-count:并发写对象的个数--image-feature:指定rbd块设备开启的特性
RBD启用特性
- 在前面执行rbd映射时,可能会遇到如下报错:
- RBD image feature set mismatch. You can disable features unsupported by the kernel with “rbd feature disable test object-map fast-diff deep-flatten”
- 这是说RBD启用了一些内核不支持的功能,需要关闭之后才能正常映射
- 可通过
rbd feature enable/disable来开启或禁用功能 rbd feature enable rbd/test object-map
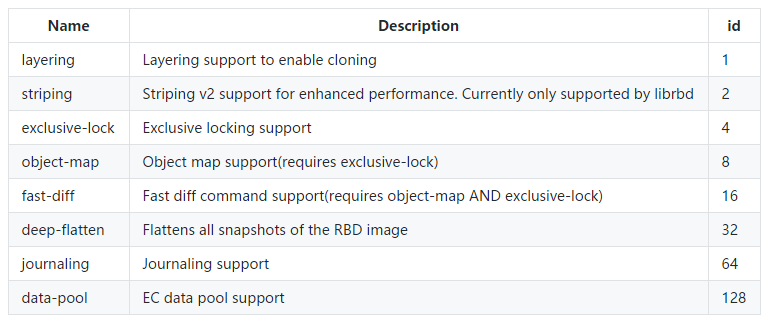
- RBD启用特性
能过配置文件配置rbd块的默认开启的特性rbd_default_features = 1
RBD查询操作
- 列出所有的rbd
rbd [-p pool-name] ls
- 查询指定rbd的详细信息
rbd info [pool-name/]image-name
- 查询指定rbd镜像的大查询指定rbd的状态信息
rbd status [pool-name/]image-name
- 查看大小
rbd du [pool-name/]image-name
RBD的复制与修改
- 修改rbd镜像的大小
rbd resize [pool-name/]image-name --size nM|G|Trbd resize rbd/test --size 2Gxfs_growfs -d /mnt 扩大xfs文件系统resie2fs /mnt 扩大ext文件系统
- 复制rbd镜像
rbd cp [pool-name/]src-image-name [pool-name/]tgt-image-name- 如果src-image正在被挂载使用,则tgt-image无法正常挂载
- 移动rbd镜像,不能跨存储池,相当于重命名
rbd mv [pool-name/]src-image-name [pool-name/]new-image-name
RBD的删除与恢复
- 删除RBD需要先将其移动至回收站
rbd trash mv [pool-name/]image-name
- 从回收站删除RBD
rbd trash rm [pool-name/]image-name
- 从回收站恢复RBD
rbd trash restore [pool-name]/image-id
- 查看当前回收站中的RBD
rbd trash ls [pool-name]
RBD的映射
- 所有映射操作都需要在客户端执行
- RBD映射
rbd map [pool-name/]image-name
- 取消映射
rbd unmap /dev/rbd0
- 查看映射
rbd showmapped
- RBD映射
- 配置rbd开机自动挂载
# vim /etc/ceph/rbdmap
# RbdDevice Parameters
poolname/imagename id=client,keyring=/etc/ceph/ceph.client.keyring
# systemctl enable rbdmap
# vim /etc/fstab
UUID= /mnt/rbd xfs defaults,_netdev 0 0
RBD快照
- RBD快照是创建于特定时间点的RBD镜像的只读副本
- RBD快照使用写时复制(COW)技术来最大程度减少所需的存储空间
- 所谓写时复制即快照并没有真正的复制原文件,而只是对原文件的一个引用(理解这一点,对理解clone有用)
- RBD快照常用操作
# rbd snap create [pool-name/]image-name@snap-name
# rbd snap ls [pool-name]/image-name
# rbd info [pool-name]/image-name@snap-name # 查看快照的信息
# rbd snap limit set --limit n [pool-name]/image-name # 设置最大快照数量
# rbd snap limit clear [pool-name]/image-name # 取消快照数量限制
# rbd snap rename [pool-name]/{image-name@old-snap-name} [pool-name]/{image-name@new-snap-name} # 重命名
# rbd snap rm [pool-name]/image-name@snap-name # 删除
# rbd snap purge [pool-name]/image-name # 清空所有的快照
# rbd snap rollback [pool-name]/image-name@snap-name # 回滚快照
# rbd snap protect [pool-name]/image-name@snap-name # 保护快照,快照无法被删除
# rbd snap unprotect [pool-name]/image-name@snap-name # 取消保护快照
- RBD快照示例
# echo "Hello Ceph This is snapshot test" > /mnt/snapshot_test_file
# rbd snap create rbd/test@snapshot1 --name client.rbd
# rbd snap ls rbd/test --name client.rbd
# echo "Hello Ceph This is snapshot test2" > /mnt/snapshot_test_file2
# rm -f /mnt/snapshot_test_*
# umount /mnt
# rbd snap rollback rbd/test@snapshot1 --name client.rbd
# mount /mnt
RBD克隆
- RBD克隆是RBD镜像副本,将RBD快照作基础,转换为彻底独立于原始来源的RBD镜像
- 创建克隆:
- 创建快照:
rbd snap create pool/image@snapshot - 保护快照:
rbd snap protect pool/image@snapshot - 创建克隆:
rbd clone pool/image@snapshot pool/clonename - 合并父镜像,只有将父镜像信息合并到clone的子镜像,子镜像才能独立存在,不再依赖父镜像:
rbd flatten pool/clonename
- 创建快照:
- 查看指定快照的子镜像:
rbd children pool/image@snapshot
RBD客户端说明
- Ceph客户端可使用原生linux内核模块krbd挂载RBD镜像
- 对于OpenStack和libvirt等云和虚拟化解决方案使用librbd将RBD镜像作为设备提供给虚拟机实例
- librbd无法利用linux页面缓存,所以它包含了自己的内存内缓存 ,称为RBD缓存
- RBD缓存是使用客户端上的内存
- RBD缓存又分为两种模式:
- 回写(write back):数据先写入本地缓存,定时刷盘
- 直写(write direct):数据直接写入磁盘
RBD缓存参数说明
- RBD缓存参数必须添加到发起I/O请求的计算机上的配置文件的[client]部分中。
| Parameter | Description | Default |
|---|---|---|
| rbd_cache | Enable RBD caching. Value=true | false|true |
| rbd_cache_size | Cache size in bytes per RBD image.Value=n | 32M |
| rbd_cache_max_dirty | Max dirty bytes allowed per RBD image.Value=n | 24M |
| Parameter | Description | Default |
|---|---|---|
| rbd_cache_target_dirty | Dirty bytes to start preemptive flush per RBD image.Value=n | 16M |
| rbd_cache_max_dirty | Max Page age in seconds before flush.Value=n | 1 |
| rbd_cache_writethrough_until_flush | start in write-through mode until the first flush is received Value=true | false | true |
RBD导出与导入
- ceph存储可以利用快照做数据恢复,但是快照依赖于底层的存储系统没有被破坏
- 可以利用rbd的导入导出功能将快照导出备份
- RBD导出功能可以基于快照实现增量导出
RBD快照创建和导出

导出操作
- 创建快照
rbd snap create testimage@v1rbd snap create testimage@v2
- 导出创建image到快照v1时间点的差异数据
rbd export-diff rbd/testimage@v1 testimage_v1
- 导出创建image到快照v2时间点的差异数据
rbd export-diff rbd/testimage@v2 testimage_v2
- 导出v1快照时间点到v2快照时间点的差异数据
rbd export-diff rbd/testimage@v2 --from-snap v1 testimage_v1_v2
- 导出创建image到当前时间点的差异数据
rbd export rbd/testimage testimage_now
导入操作
- 随便创建一个image,名称大小都不限制(恢复时会覆盖大小信息,增量导入才需要创建image,全量导入不需要)
rbd create testbacknew --size 1
- 恢复到v2时间点
- 直接基于v2的时间点快照做恢复
rbd import-diff testimage_v2 rbd/testbacknew
- 基于v1的时间点数据,增量v1_v2的数据
rbd import-diff testimage_v1 rbd/testbacknewrbd import-diff testimage_v1_v2 rbd/testbacknew
- 直接基于v2的时间点快照做恢复
快照的数据恢复
Ceph RBD镜像配置
Why RBD-mirror
- Ceph采用的是强一致性同步模型,所有副本都必须完成写操作才算一次写入成功,一个请求需要异地返回再确认完成,如果副本在异地,网络延迟就会很大,拖垮整个集群的写性能。因此,Ceph集群很少有跨域部署的,也就缺乏异地容灾
- Ceph从Jewel版本开始引入 RBD-mirror以实现异地容灾
RBD-mirror架构说明
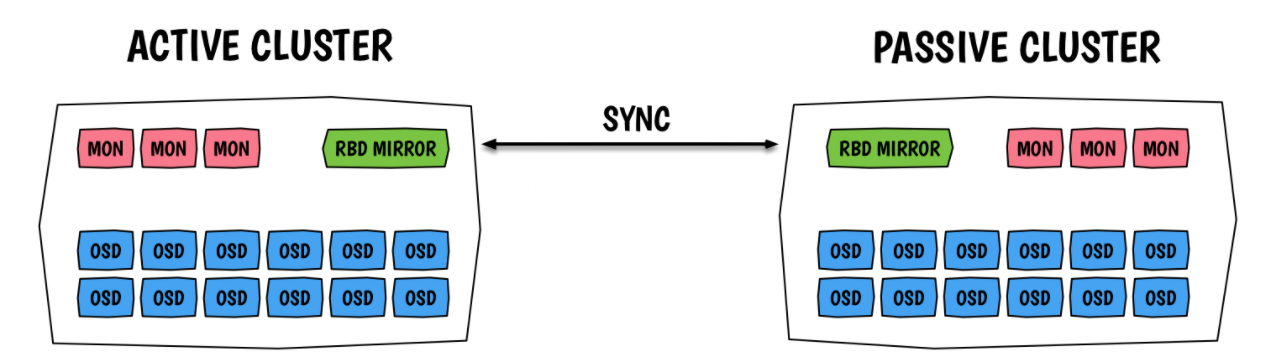
RBD mirror流程
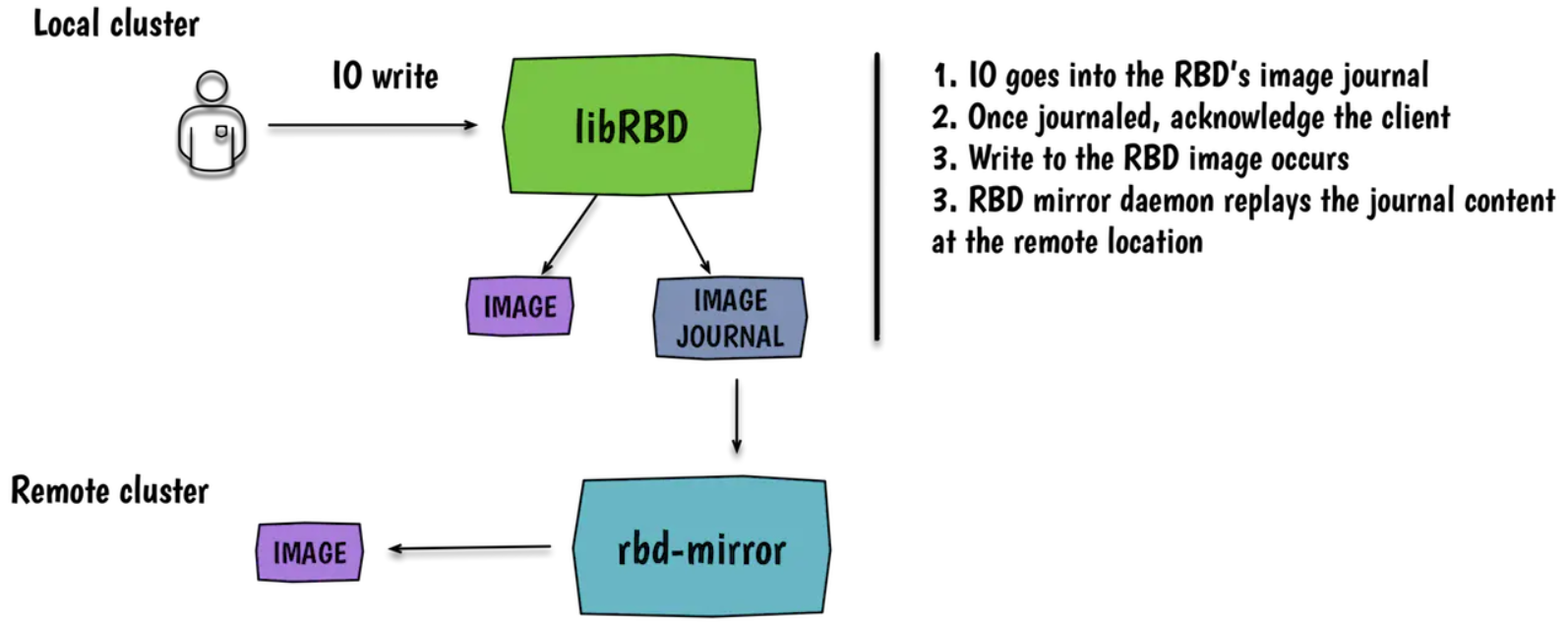
RBD mirror优缺点
优点:
- 当副本在异地的情况下,减少了单个集群不同节点间的数据写入延迟
- 减少本地集群或异地集群由于意外断电导致的数据丢失
缺点:
- 成本高昂
- 会导致主集群性能下降
- 如果人为误操作删除镜像,则异地镜像也会被删除
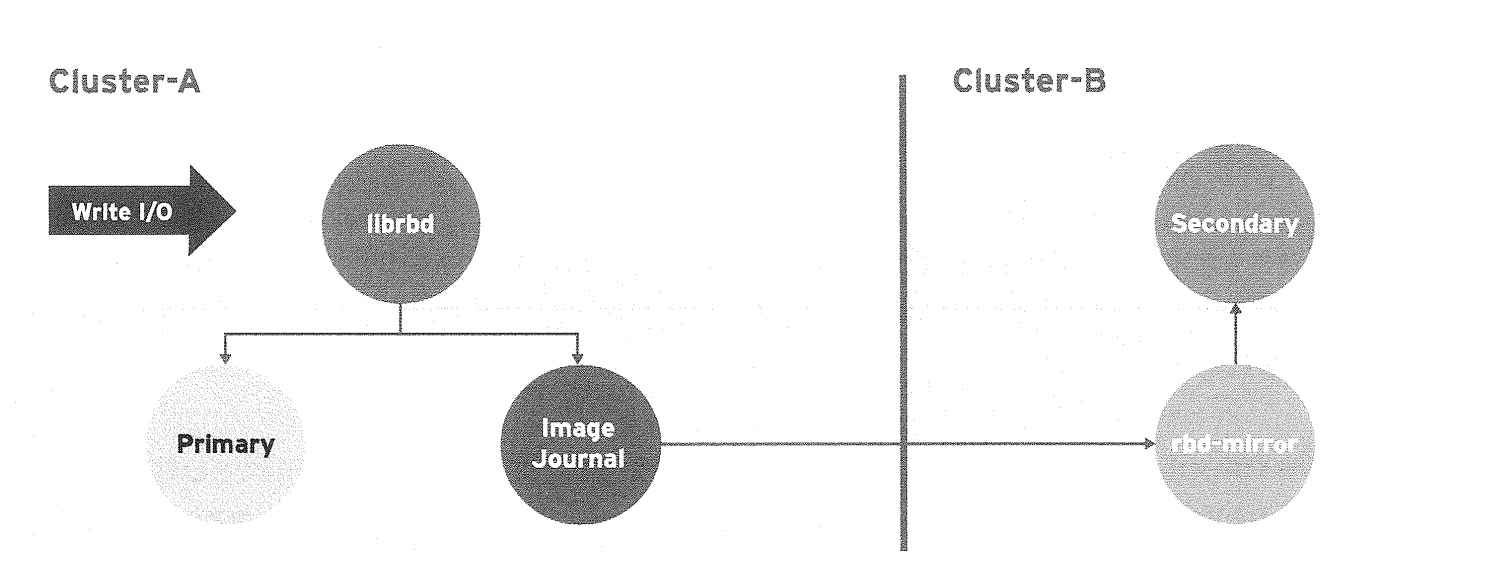
单向备份
- 当数据从主集群备份到备用集群的时候,rbd-mirror仅在备份集群运行
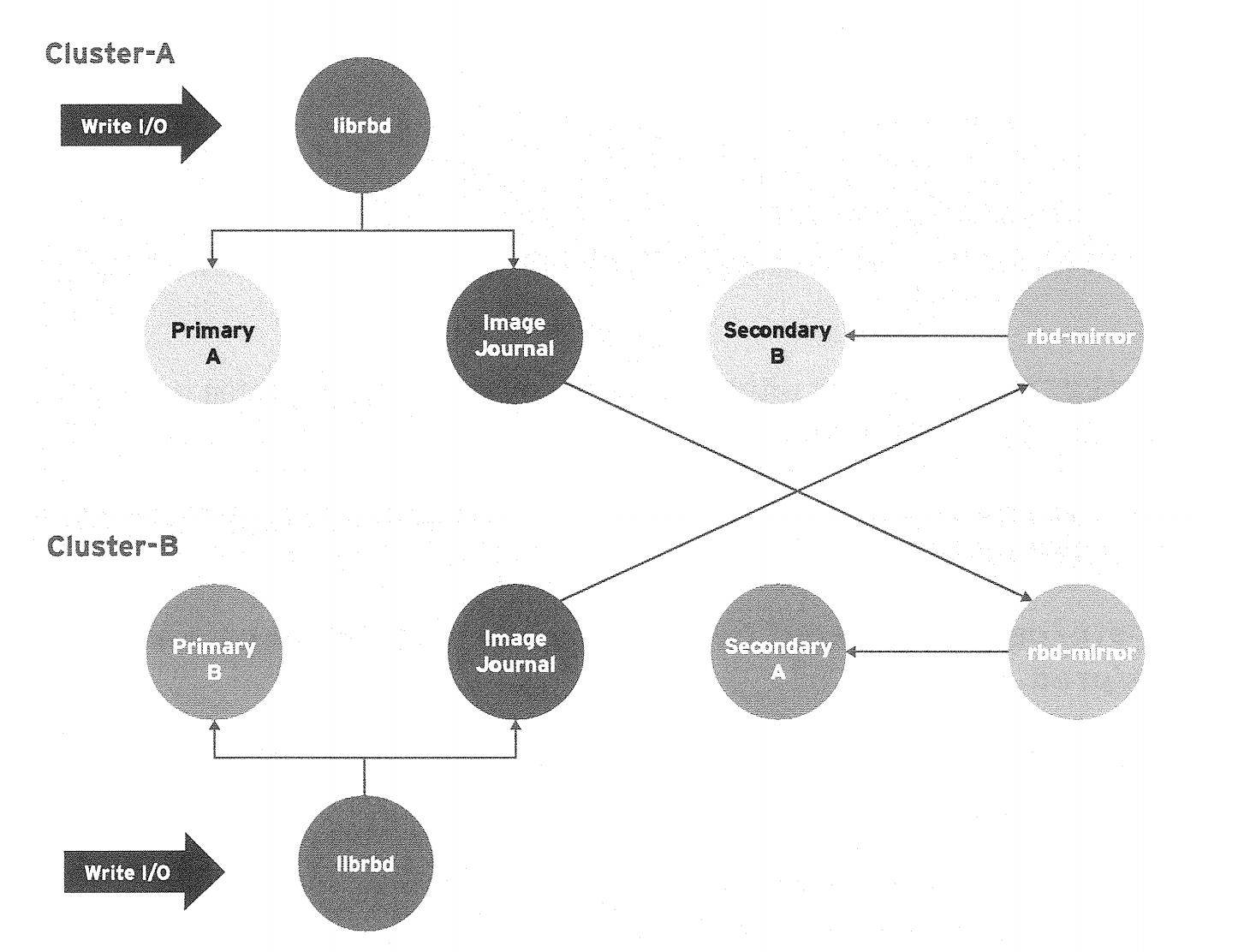
双向备份
- 如果两个集群互为备份的时候,rbd-mirror需要在两个集群上都运行
镜像模式
- mirroring是基于存储池进行的peer,ceph支持两种模式的镜像:
- 存储池模式:一个存储池内的所有镜像都会进行备份
- 镜像模式:只有指定的镜像才会备份
Image状态
- 做了mirroring的image的状态:
- primary(可以修改)
- non-primary(不能修改)
安装须知
- RBD镜像功能需要Ceph Jewel或更新的发行版本
- 两个集群需要能够互通
- 单向同步可以一对多,双向同步只能一对一
- RBD需要开启journal特性,用于记录image事件
- 开启journaling特性,需要先开启exclusive-lock特性
单节点安装ceph集群
- ceph-ansible安装
- 修改inventoryfile:
[mons]serverf[osds]serverf[mgrs]serverf[clients]serverf[rbdmirrors]serverf - 创建
all.yml文件(单节点部署需要加上,修改ceph的故障域为osd)common_single_host_mode: true
- 执行安装
ansible-playbook -i hosts site.yml
安装rbd-mirror
- rbd-mirror是一个新的守护进程,负责将一个镜像从一个集群同步到另一个集群
- 如果是单向同步,则只需要在备份集群上安装
- 如果是双向同步,则需要在两个集群上都安装
- rbd-mirror需要连接本地和远程集群
- 每个集群只需要运行一个rbd-mirror进程
- 手动安装
yum install rbd-mirror
- ceph-ansible安装
- 修改inventoryfile:
[rbdmirrors]serverf
- 修改inventoryfile:
- 创建
rbd-mirrors.yml文件cd /usr/share/ceph-ansible/group_vars;cp rbd-mirrors.yml.sample rbd-mirrors.yml
- 执行安装
ansible-playbook -i hosts site.yml
修改配置
- 如果是单向同步,则只需要在主集群修改,如果是双向同步,需要在两个集群上都修改:
rbd_default_features = 69 - 也可不修改配置文件,而在创建镜像时指定需要启用的功能
配置rbd-mirror节点能访问两个集群
# serverf上执行:
# scp serverc:/etc/ceph/ceph.conf /etc/ceph/prod.conf
# scp serverc:/etc/ceph/ceph.client.admin.keyring /etc/ceph/prod.client.admin.keyring
# cp /etc/ceph/ceph.conf /etc/ceph/bup.conf
# cp /etc/ceph/ceph.client.admin.keyring /etc/ceph/bup.client.admin.keyring
# chown -R ceph.ceph /etc/ceph
# 验证:
# ceph --cluster prod mon stat
# ceph --cluster bup mon stat
启动rbd-mirror进程
# 先手动在前台启动:
# rbd-mirror -d --setuser ceph --setgroup ceph --cluster bup -i admin
# 确认没问题,切入后台启动:
# systemctl start ceph-rbd-mirror@admin
查询池同步状态
# rbd mirror pool status --pool=rbdmirror --cluster bup
# rbd mirror image status rbdmirror/test --cluster bup
# rbd info rbdmirror/test --cluster bup
配置同步模式为镜像模式(双向同步)
- 配置池模式为镜像模式
rbd mirror pool enable rbd image --cluster prodrbd mirror pool enable rbd image --cluster bup
- 增加同伴集群
rbd mirror pool peer add rbd client.admin@bup --cluster prodrbd mirror pool peer add rbd client.admin@prod --cluster bup
- 创建RBD并开启journaling特性
rbd feature enable rbd/test exclusive-lock --cluster prodrbd feature enable rbd/test journaling --cluster prod
- 开启指定rbd的镜像功能
rbd mirror image enable rbd/test --cluster prod
镜像升降级操作
- 将主集群中的rbd/test降级:
rbd mirror image demote rbd/test --cluster prod
- 将备份集群中的rbd/test升级:
rbd mirror image promote rbd/test --cluster bup
- 将主集群中的rbdmirror池降级
rbd mirror pool demote rbdmirror
- 将备集群中的rbdmirror池升级
rbd mirror pool promote rbdmirror
其他常用操作
| RBD commands for mirroring | |
|---|---|
| Enable RBD Mirroring | rbd mirror pool enable pool-name mirror-mode |
| Disable RBD Mirroring | rbd mirror pool enable pool-name |
| Add a cluster peer | rbd mirror pool peer add pool-name client-name@cluster-name |
| Display mirror information | rbd mirror pool info pool-name |
| Remove a cluster peer | rbd mirror pool peer remove pool-name peer-uuid |
| Enable a feature | rbd feature enable pool-name/image-name feature-name |
| Disable a feature | rbd feature disable pool-name/image-name feature-name |
| Enable mirroring per RBD image(image mode) | rbd mirror image enable pool-name/image-name |
| Disable mirroring per RBD image(image mode ) | rbd mirror image disable pool-name/image-name |
| Demote the primary copy | rbd mirror image demote pool-name/image-name |
| Demote all primary copies in pool | rbd mirror pool demote pool-name |
| Demote the secondary copy | rbd mirror image promote pool-name/image-name |
| Promote all secondary copies in pool | rbd mirror pool promote pool-name |
| Promote the secondary copy | rbd mirror image promte pool-name/image-name |
| Promote all secondary copies in pool | rbd mirror pool promote pool-name |
| Force resynchronization | rbd mirror image resync pool-name/image-name |
| RBD image mirroring status | rbd mirror image status pool-name/image-name |
| Pool mirroring status | rbd mirror pool status pool-name |
| RBD image journal commands | rbd journal info pool-name/image-name rbd jounal status poo-name/images-name |
| RBD image journal check | rbd jounal inspect pool-name/image-name |
| RBD and clear the journal in case of corruption | rbd journal reset pool-name/image-name |
故障转移
- 正常关机故障转移
- 关掉所有正在使用的主image客户端
- 将主集群的主image降级
- 将backup集群的主image升级
- 重新让客户端连接新的主image
- 非正常关机故障转移
- 确认主集群异常无法进行正常操作
- 停止所有使用主image的客户端
- 将backup集群的非主状态的image升级为主image,需要使用—force选项
- 重新让客户端连接新的主image
故障恢复
- 主集群恢复以后,先将主集群上的旧的主image降级
- 重新同步image,将备份集群的主image往主集群的降级的image上同步
rbd mirror image resync <pool-name>/<image-name> --cluster ceph
- 确认同步完成
- 将备份集群上的image降级
- 将主集群上的image升级
Ceph RGW对象存储
对象存储介绍
- 通过对象存储,将数据存储为对象,每个对象除了包含数据,还包含数据自身的元数据
- 对象通过Object ID来检索,无法通过普通文件系统操作来直接访问对象,只能通过API来访问,或者第三方客户端(实际上也是对API的封装)
- 对象存储中的对象不整理到目录树中,而是存储在扁平的命名空间中,Amazon S3将这个扁平命名空间称为bucket。而swift则将其称为容器
- 无论是bucket还是容器,都不能嵌套
- bucket需要被授权才能访问到,一个帐户可以对多个bucket授权,而权限可以不同
- 对象存储的优点:易扩展、快速检索
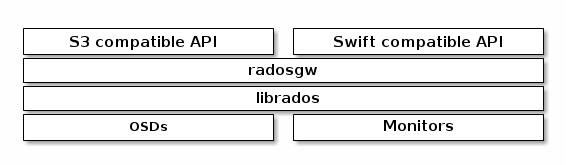
RADOS网关介绍
- RADOS网关也称为Ceph对象网关、RADOSGW、RGW,是一种服务,使客户端能够利用标准对象存储API来访问Ceph集群。它支持S3和Swift API
- rgw运行于librados之上,事实上就是一个称之为Civetweb的web服务器来响应api请求
- 客户端使用标准api与rgw通信,而rgw则使用librados与ceph集群通信
- rgw客户端通过s3或者swift api使用rgw用户进行身份验证。然后rgw网关代表用户利用cephx与ceph存储进行身份验证
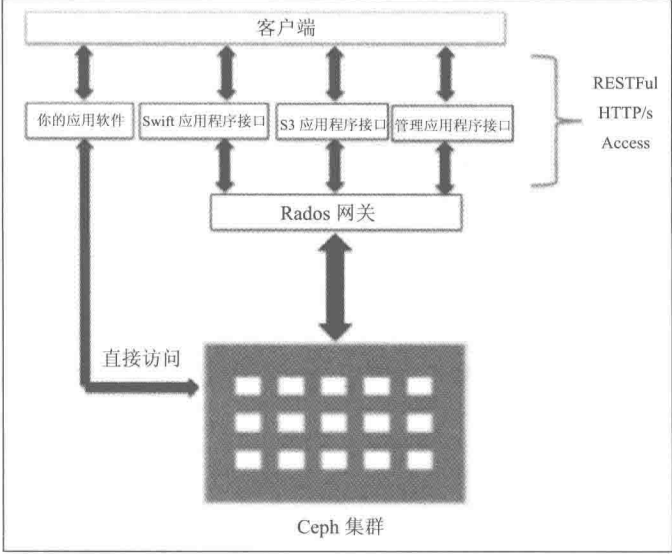
- RGW层次结构
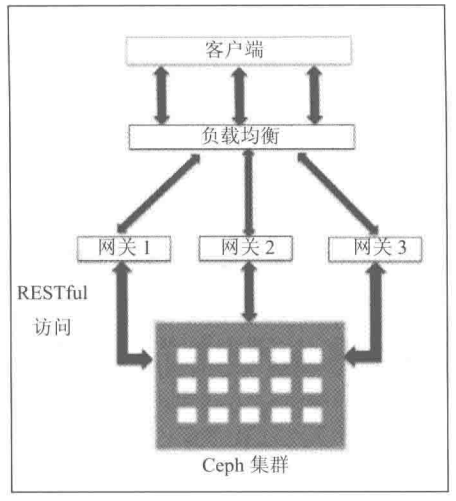
- Ceph网关部署架构
RADOS网关部署步骤
- 生成用于网关验证的cephx用户
ceph auth get-or-create client.rgw.servera mon 'allow rwx' osd 'allow rwx' -o /etc/ceph/ceph.client.rgw.servera.keyring
修改ceph.conf配置文件
[client.rgw.servera]host = serverakeyring = /etc/ceph/ceph.client.rgw.servera.keyringrgw_frontends = civetwebport=80
安装ceph-radosgw
yum install -y ceph-radosgw
- 启动ceph-radosgw
systemctl restart ceph-radosgw@rgw.servera
civetweb常用配置

civetweb配置示例
/etc/ceph/ceph.conf
[client.rgw.servera]
keyring = /etc/ceph/ceph.client.rgw.servera.keyring
rgw_frontends = civetweb
port=80
log_file=/var/log/ceph/servera.rgw.log
access_log_file=/var/log/ceph/civetweb.access.log
error_log_file=/var/log/ceph/civetweb.error.log
num_threads=100
- 访问radosgw
curl http://servera
S3简介
- S3由Amazon于2006年推出,全称为Simple Storage Service
- S3定义了对象存储,是对象存储事实上的标准,从某种意义上说,S3就是对象存储,对象存储就是S3
- S3是对象存储市场的霸主,后续的对象存储都是对S3的模仿
RGW的S3 API支持
- 对象存储在bucket中
- 若要利用S3 API访问对象,需要为RADOS网关配置用户
- 每个用户具有一个access key和一个secret key。access key标识用户,secret key验证用户身份
创建S3 API用户
radosgw-admin user create --uid=john --display-name="John Doe" --email=john@example.com --access-key=12345 --secret=67890--uid指定用户名--display-name指定备注名--email指定邮箱--access-key指定access key,如果不指定,会自动生成--secret指定secret key如果不指定,会自动生成- 当
radosgw-admin自动生成密钥时,有时会在access key和secretkey中包含josn转义符”\”。在使用的时候,不能包含这个字符
S3用户管理
- 修改用户:
radosgw-admin user modify --uid=uid --display-name="John E. Doe" --max-buckets=2000
- 禁用用户:
radosgw-admin user suspend --uid=uid
- 启用用户:
radosgw-admin user enable --uid=uid
- 删除用户:
radosgw-admin user rm --uid=uid [--purge-data] [--purge-keys]
- 列出当前所有用户:
radosgw-admin user list
- 查看指定用户的详细信息:
radosgw-admin user info --uid=uid
管理用户密钥
- 创建一个用户的key
radosgw-admin key create --uid=uid --key-type=s3 [--access-key=key] [--secret=secret]
- 删除一个用户的key
radosgw-admin key rm --uid=uid --access-key=key
- 在创建密钥时,可以通过—gen-access-key和—gen-secret来生成随机的access key和secret key
设置配额
- 基于用户的配额
radosgw-admin quota set --quota-scope=user --uid=uid [--max-objects=number] [--max-size=sizeinbytes]
- 基于bucket的配额
radosgw-admin quota set --quota-scope=bucket --uid=uid [--max-objects=number] [--max-size=sizeinbytes]
- 启用配额
radosgw-admin quota enable --quota-scope=[user|bucket] --uid=uid
- 禁用配额
radosgw-admin quota disable --quota-scope=[user|bucket] --uid=uid
- 取消配额
radosgw-admin quota set --uid=marry --quota-scope=bucket --max-objects=-1 --max-size=-1
统计数据
# radosgw-admin usage show --uid=uid --start-date=start --end-date=end
# radosgw-admin usage trim --start-date=start --end-date=end
# radosgw-admin usage show --show-log-entries=false
# date的表示方法:
# YYYY-MM-DD hh:mm:ss
利用rados网关访问S3对象
# 修改网关服务的/etc/ceph/ceph.conf,添加如下内容:
rgw_dns_name = servera
配置s3 api客户端s3cmd
yum install -y s3cmd
s3cmd --configure- 配置密钥
- 配置cloudfront_host
- 配置host_base
- 配置host_bucket
- 配置website_endpoint
使用s3cmd
- 创建bucket
s3cmd mb s3://demobucket
- 上传文件至bucket
s3cmd put --acl-public /tmp/demoobject s3://demobucket/demoobject
- 获取文件
s3cmd get s3://demobucket/demoobject ./demoobjectcurl http://demobucket.servera/demoobjectcurl http://servera/test/demoobject
bucket常用操作
- 列出bucket
radosgw-admin bucket list
- 删除bucket
radosgw-admin bucket rm --bucket=bucket
- 查看bucket信息
radosgw-admin bucket stats --bucket=bucket
- 检查bucket
radosgw-admin bucket check --bucket=bucket
Swift简介
- openstack swift是openstack开源云计算项目开源的对象存储,提供了强大的扩展性、冗余和持久性
- swift特性:
- 极高的数据持久性
- 完全对称的系统架构
- 无限的可扩展性
- 无单点故障
RGW的Swift API支持
- 对象存储在容器中
- Openstack Swift API的用户模型与Amazon S3 API稍有不同。若要使用swift api通过rados网关的身份验证,需要为rados网关用户帐户配置子用户
- Amazon S3 API授权和身份验证模型具有单层设计。一个用户可以有多个access key和secret key,用于在同一帐户中提供不同类型的访问
- 而swift有租户概念,rados网关用户对应swift的租户,而子帐号则对应swift的api用户
- RADOS网关支持Swift v1.0以及OpenStack keystone v2.0身份验证
创建swift子用户
radosgw-admin subuser create --uid tom --subuser tom:swift --access=full--uid指定现有的rgw网关用户--subuser指定子用户--access指定用户权限readwritereadwritefull
swift用户管理
- 修改子用户
rados-admin subuser modify --subuser=uid:subuserid --access=full
- 删除子用户
radosgw-admin subuser rm --subuser=uid:subuserid [--purge-data] [--purge-keys]
- 修改子用户密钥
radosgw-admin key create --subuser=uid:subuserid --key-type=swift [--access-key=key] [--secret=secret]
- 删除子用户密钥
radosgw-admin key rm --subuser=uid:subuserid
使用swift客户端
- 安装swift客户端
yum install -y python-swiftclient
- 创建一个容器
swift -V 1.0 -A http://servera/auth -U john:swift -K secret post container
- 向容器中上传一个文件
swift -A http://servera/auth/v1.0 -U john:swift -K secret upload container file
- 列出容器中的文件
swift -A http://servera/auth/v1.0 -U john:swift -K secret list [container]
- 查看容器状态
swift -A http://servera/auth/v1.0 -U john:swift -K secret stat
swift中的多租户支持
- swift api支持使用租户来隔离bucket和用户。swift api将用户创建的每个新bucket与租户关联,允许将同一名称用于不同租户的bucket
- 创建租户中的用户:
radosgw-admin user create --tenant testtenant --uid testuser --display-name "swift user" --subuser testuser:testswift --key-type swift --access full
- 使用租户中的用户:
radosgw-admin --subuser 'testtenant$testuser:testswift' --key-type swift --scecret redhat
Ceph 多区域网关
多区域概念
- Multi-Site功能是从J版本开始的。一个single zone配置通常由一个zone group组成,该zone group包含一个zone和多个用于负载均衡的RGW实例。从K版本开始,ceph为RGW提供了Multi-Site的配置选项
多区域相关术语
- 区域(zone): 一个ceph集群可以包含多个区域,一个区域只属于一个集群,一个区域可以有多个RGW
- 区域组(zonegroup):由一个或多个区域组成,包含一个主区域(master zone),其他区域称为Secondary Zone,区域组内的所有区域之间同步数据
域(realm): 同一个或多个区域组组成,包含一个主区域组,其他都次区域组。域中的所有rados网关都从位于主区域组和主区域中的rados网关拉取配置
注意: master zone group中的master zone处理所有元数据更新,因此创建用户、bucket等操作都必须经由master zone
多区域网关配置架构
- single-zone:一个realm中只有一个zonegroup和一个zone,可以有多个RGW
- multi-zone:一个relam中只有一个zonegroup,但是有多个zone。一个realm中存储的数据复制到该zonegroup中的所有zone中
- multi-zonegroup:一个realm中有多个zonegroup,每个zonegroup中又有一个或多个zone
- multi-realms:多个realm
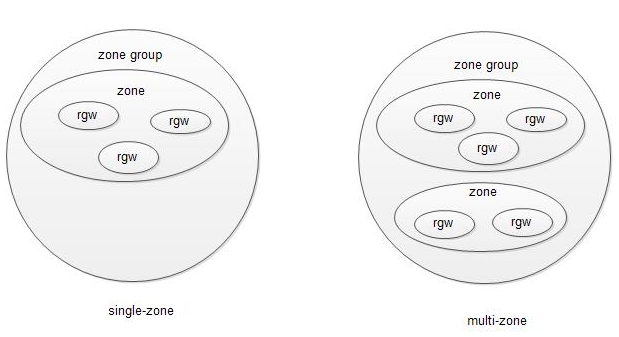
Periods和Epochs
- 每个zone有关联的period,每个period有关联的epoch。
- period用于跟踪zone、zone group和realm的配置状态
- epoch用于跟踪zone period的配置变更的版本号
- 每个period具有唯一ID,含有zone配置,并且知道其先前period的id
- 在更改zone的配置时,需要更新zone的当前period
多区域同步流程
- RGW在所有zone group集合之间同步元数据和数据操作。元数据操作与bucket相关:创建、删除、启用和禁用版本控制、管理用户。meta master位于master zone group中的master zone,负责管理元数据更新
- 多区域配置后处于活跃状态时,RGW会在master和secondary区域之间执行一次初始的完整同步。随后的更新是增量更新
- 当RGW将数据写入zone group的任意zone时,它会在该zone group的所有其他zone之间同步这一数据
- 当RGW同步数据时,所有活跃的网关会更新数据日志并通知其他网关
- 当RGW网关因用户操作而同步元数据时,主网关会更新元数据日志并通知其他RGW网关
多区域网关配置
- Master区域配置(在servera上配置)
- 创建realm
radosgw-admin realm create --rgw-realm movies --default
- 创建zonegroup
radosgw-admin zonegroup create --rgw-realm movies --rgw-zonegroup us --master --default
- 创建zone
radosgw-admin zone create --rgw-zonegroup us --rgw-zone us-east --endpoints http://servera --default
- 创建用户绑定zone
radosgw-admin user create --uid syncuser --display-name "sync user" --systemradosgw-admin zone modify --rgw-zonegroup us --rgw-zone us-east --access-key access-key --secret secret
- 更新period
radosgw-admin period update --commit
- 更新RGW配置文件
[client.rgw.servera]rgw_zone = us-east - 启动RGW
systemctl restart ceph-radosgw@rgw.servera
- 测试
radosgw-admin user create --uid yutian --display-name 'yutian'radosgw-admin subuser create --uid yutian --subuser yutian:swift --access=fullswift -A http://servera/auth/v1.0 -U yutian:swift -K secret-key post testbucketswift -A http://servera/auth/v1.0 -U yutian:swift -K secret-key upload testbucket /etc/hosts
- 创建realm
- Secondary区域配置(在serverf上配置)
- 拉取realm
radosgw-admin realm pull --url http://servera --access-key access-key --secret secret-key # 主区域中syncuser的key
- 拉取period
radosgw-admin period pull --url http://servera --access-key access-key --secret secret-key
- 创建 Secondary Zone
radosgw-admin zone create --rgw-zonegroup us --rgw-zone us-west --access-key access-key --secret secret-key --endpoints http://serverf [--read-only] --default
- 更新rgw配置文件
[client.rgw.serverf]rgw_zone = us-west - 更新period
radosgw-admin period update --commit
- 启动RGW
systemctl restart ceph-radosgw@rgw.serverf
- 检查同步状态
radosgw-admin sync status
- 拉取realm
维护
- 查看同步状态
radosgw-admin sync status
- 变更metadata master zone(需要在元数据完全同步完成之后才能进行变更操作,否则可能会丢失数据):
radosgw-admin zone modify --rgw-zonegroup us --rgw-zone us-east --masterradosgw-admin period update --commit
故障切换
假如当前master zone故障,需切换到secondary zone以进行容灾恢复:
- 提升secondary zone为master zone
radosgw-admin zone modify --rgw-zone us-west --master --default [--read-only=False]
- 更新period以使修改生效
radosgw-admin period update --commit
- 重启RGW
systemctl restart ceph-radosgw@rgw.serverf
- 在servera上执行重新拉取period
radosgw-admin period pull --url http://serverf --access-key access-key --secret secret-key
故障恢复
- 原master zone恢复以后,将该zone再恢复到master
- 拉取period
- 设置恢复后的zone为master zone
- 重启恢复后的zone的rgw
- 更新period以使修改生效
- 重启secondary zone的rgw
CephFS文件系统
Ceph文件系统简介
- CephFS提供兼容POSIX的文件系统,将其数据和元数据作为对象存储在Ceph中
- CephFS依靠MDS节点来协调RADOS集群的访问,及管理元数据
元数据服务器
- MDS管理元数据(文件的所有者、时间戳和模式等),也负责缓存元数据访问权限,管理客户端缓存来维护缓存一致性。
- CephFS客户端首先联系MON,进行身份验证后,将查询活跃MDS的文件元数据,并通过直接与OSD通信来访问文件或目录的对象。
- Ceph支持一个集群中有多个活跃的MDS,多个备用MDS。
- Ceph支持一个集群中有多个活跃的CephFS文件系统
- 目前CephFS的快照功能尚未GA
部署元数据服务器
/etc/ansible/hosts
...
[mdss]
servera
# cd /usr/share/ceph-ansible/group_vars
# sudo cp mdss.yml.sample mdss.yml
# cd ..
# ansible-playbook site.yml --limit mdss
创建Ceph文件系统
- CephFS文件系统需要两个存储池,一个用于存储CephFS数据,一个用于存储CephFS元数据
ceph osd pool create cephfs_metadata 64 64ceph osd pool create cephfs_data 128 128ceph fs new cephfs cephfs_metadata cephfs_data- 如果使用ceph-ansible部署mds,则以上文件系统和存储池会被默认创建
ceph fs status cephfs
CephFS常用操作
# ceph fs new fs-name meta-pool data-pool
# ceph fs ls
# ceph fs rm fs-name [--yes-i-really-mean-it]
# ceph mds fail gid/name/role
# ceph mds repaired role
挂载CephFS
# 创建挂载用户
# ceph auth get-or-create client.cephfs mon 'allow r' mds 'allow' osd 'allow rw pool=cephfs_metadata, allow rw pool=cephfs_data' -o /etc/ceph/ceph.client.cephfs.keyring
# 使用ceph-fuse挂载
# ceph-fuse --keyring /etc/ceph/ceph.client.cephfs.keyring --name client.cephfs -m mon1:6789,mon2:6789,mon3:6789 /mnt/cephfs
# echo "id=cephfs,keyring=/etc/ceph/ceph.client.cephfs.keyring,conf=/etc/ceph/ceph.conf /mnt/cephfs fuse.ceph defaults,_netdev 0 0 " >> /etc/fstab
使用内核客户端挂载
# ceph auth get-key client.cephfs -o /etc/ceph/cephfskey
mount -t ceph mon1:6789,mon2:6789,mon3:6789:/ /mnt/cephfs -o name=cephfs,secretfile=/etc/ceph/cephfskey
# echo "mon1:6789,mon2:6789,mon3:6789:/ /mnt/cephfs ceph name=cephfs,secretfile=/etc/ceph/cephfskey,noatime,_netdev 0 0" >> /etc/fstab
CephFS工具
- cephfs-journal-tool:用于检查和修复MDS日志
- cephfs-table-tool:用于检查和修复MDS表
- cephfs-data-scan:用于检查和重建元数据
映射文件到对象
# 若要对问题进行故障排除,需要了解文件存储在哪些OSD中
# 下列步骤用于检索Ceph中文件的对象映射信息
# printf '%x\n' $(stat -c %i filepath) # 检索指定文件的节点编号并转换成16进制
# rados -p cephfs_data ls |grep 10000000000 #查找该编号的对象
# ceph osd map cephfs_data 10000000000.00000000 # 通过对象查找其pg和osd
# ceph osd find 0 # 查找osd.0在哪个节点
管理和自定义CRUSHMAP
主要内容
- CRUSH和CRUSH map简介
- CRUSH map的解译、编译和更新
- 编写自定义CRUSH map,以控制对象放置策略
- 使用命令行配置CRUSH map
Ceph集群写操作流程
- client首先访问ceph monitor获取cluster map的一个副本,知晓集群的状态和配置
- 数据被转化为一个或多个对象,每个对象都具有对象名称和存储池名称
- 以PG数为基数做hash,将对象映射到一个PG
- 根据计算出的PG,再通过CRUSH算法得到存放数据的一组OSD位置(副本个数),第一个是主,后面是从
- 客户端获得OSD ID,直接和这些OSD通信并存放数据
注: 以上所有操作都是在客户端完成的,不会影响ceph集群服务端性能
RUSH的作用,就是根据PG ID得一个OSD列表
- Ceph使用CRUSH算法(Controlled Replication Under Scalable Hashing 可扩展哈希下的受控复制)来计算哪些OSD存放哪些对象
- 对象分配到PG中,CRUSH决定这些PG使用哪些OSD来存储对象。理想情况下,CRUSH会将数据均匀的分布到存储中
- 当添加新OSD或者现有的OSD出现故障时,Ceph使用CRUSH在活跃的OSD上重平衡数据
- CRUSH map是CRUSH算法的中央配置机制,可通过调整CRUSH map来优化数据存放位置
- 默认情况下,CRUSH将一个对象的多个副本放置到不同主机上的OSD中。可以配置CRUSH map和CRUSH rules,使一个对象的多个副本放置到不同房间或者不同机柜的主机上的OSD中。也可以将SSD磁盘分配给需要高速存储的池
CRUSH map的解译、编译和更新
# 导出CRUSH map
# ceph osd getcrushmap -o ./crushmap.bin
# 解译CRUSH map
# crushtool -d ./crushmap.bin -o ./crushmap.txt
# 修改后的CRUSH map重新编译
# crushtool -c ./crushmap.txt -o ./crushmap-new.bin
# 更新CRUSH map
# ceph osd setcrushmap -i ./crushmap-new.bin
# 查看CRUSH map
# ceph osd crush dump
# Ceph osd tree
CRUSH map组成部分
- CRUSH hierarchy(层次结构):一个树型结构,通常用于代表OSD所处的位置。默认情况下,有一个根bucket,它包含所有的主机bucket,而OSD则是主机bucket的树叶。这个层次结构允许我们自定义,对它重新排列或添加更多的层次,如将OSD主机分组到不同的机柜或者不同的房间
- CRUSH rule(规则):CRUSH rule决定如何从bucket中分配OSD pg。每个池必须要有一条CRUSH rule,不同的池可map不同的CRUSH rule
CRUSH map配置段
- CRUSH可调参数及其设置
- 所有物理存储设备列表
- 所有基础架构bucket以及各自含有的存储设备或其他bucket ID的列表
- 包含PG和OSD map的CRUSH rule列表
物理存储设备
- 存储设备的ID
- 存储设备的名称
- 存储设备的权重(以TB为单位的容量)
- 存储设备的类别
- HDD
- SSD
- NVMe SSD
- 示例:
device 0 osd.0 weight 0.015 class hdddevice 1 osd.0 class ssd
CRUSH bucket类型
- 默认bucket类型:
- osd
- host
- chassic
- rack
- row
- pdu
- pod
- room
- datacenter
- region
- root
- bucket类型支持自定义
图解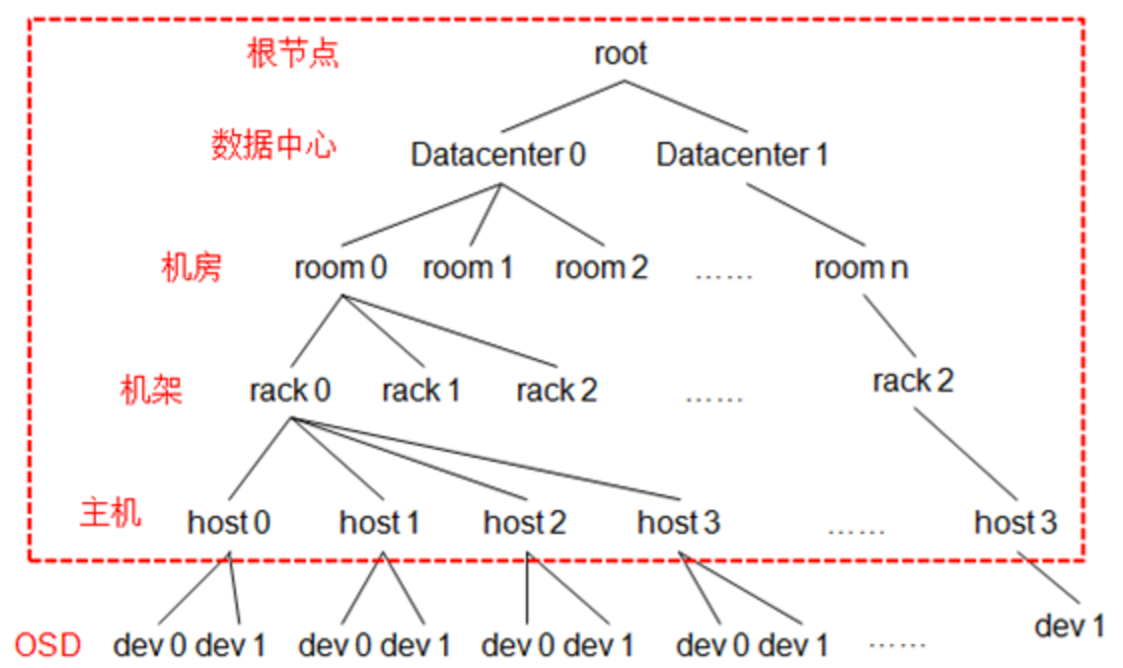
CRUSH map bucket配置项
[bucket-type] [bucket-name] {
id [一个负整数,以便与存储设备id区分]
weight [权重]
alg [将pg map到osd时的算法,默认使用straw2]
hash [每个bucket都有一个hash算法,目前Ceph支持rjenkins1算法,设为0即使用该算法]
item [一个bucket包含的其他bucket或者叶子]
}
host servere {
id -3 # do not change unnecessarily
id -4 class hdd # do not change unnecessarily
# weight 0.044
alg straw2
hash 0 # rjenkins1
item osd.2 weight 0.015
item osd.4 weight 0.015
item osd.8 weight 0.015
}
CRUSH规则
- CRUSH map包含数据放置规则,默认有两个规则: replicated_rule和erasure-code
- 通过ceph osd crush rule ls可列出现有规则,也可以使用ceph osd crush rule dump打印规则详细详细
CRUSH规则配置说明
rule <rulename> {
id <id > [整数,规则id]
type [replicated|erasure] [规则类型,用于复制池还是纠删码池]
min_size <min-size> [如果池的最小副本数小于该值,则不会为当前池应用这条规则]
max_size <max-size>[如果创建的池的最大副本大于该值,则不会为当前池应用这条规则]
step take <bucket type> [这条规则作用的bucket,默认为default]
step [chooseleaf|choose] [firstn] <num> type <bucket-type>
# num == 0 选择N(池的副本数)个bucket
# num > 0且num < N 选择num个bucket
# num < 0 选择N-num(绝对值)个bucket
step emit
}
CRUSH规则配置示例
rule replicated_rule {
id 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
CRUSH可调参数
- 可通过选项来调整、禁用、启用CRUSH算法的功能
- CRUSH map的开头定义可调参数,可使用ceph osd crush show-tunables来查看
- 调整CRUSH map的参数可能会改变CRUSH将pg映射到OSD的方式。发生这种情况时,集群将把对象移到集群中的不同OSD,来反映重新计算后的map
- 除了修改个别可调项外,可以通过
ceph osd crush tunables profile命令选择预定义的profile。一些profile需要ceph或ceph客户端的更低版本 - 预定义的profile:
- legacy
- Argonaut
- bobtail
- firefly
- hammer
- jewel
- optimal:当前版本的最佳值
从命令行更新CRUSH map层次结构
- 创建bucket
ceph osd crush add-bucket <name> <type>
- 示例:
ceph osd crush add-bucket DC1 datacenterceph osd crush add-bucket rackA1 rackceph osd crush add-bucket rackB1 rack
- 将bucket整理到层次结构中
ceph osd move <name> type=<parent>
- 示例:
ceph osd crush move rackA1 datacenter=DC1ceph osd crush move rackB1 datacenter=DC1ceph osd crush move DC1 root=default
- 设置osd的位置
ceph osd add osd.0 0.01500 root=default host=serverf
从命令行添加crushmap规则
- 添加规则
ceph osd crush rule create-replicated <rulename> <root> <failure-domain-type> [class]rulename:规则名称root:CRUSH map层次结构的起始节点failure-domain-type:故障域class:要使用的设备类型,如ssd或者hdd,此参数可选- 示例:
ceph osd crush rule create-replicated inDC2 DC2 rack
- 查看规则
ceph osd crush rule lsceph osd crush rule dump <rule name>
- 应用规则
- 创建一个新池,直接应用新的规则
ceph osd pool create myfirstpool 50 50 inDC2
- 创建一个新池,直接应用新的规则
- 修改一个池的规则到新的规则
ceph osd pool set rbd crush_ruleset 1
关于纠删码池的规则
# ceph osd erasure-code-profile set myprofile k=3 m=2 crush-root=DC2 crush-# failure-domain=rack crush-device-class=ssd# ceph osd pool create myecpool 50 50 erasure myprofile# ceph osd crush rule ls基于机柜级别的故障域
- 添加一个root为dc1
# ceph osd crush add-bucket dc1 root
- 添加三个机柜bucket
# ceph osd crush add-bucket rack1 rack# ceph osd crush add-bucket rack2 rack# ceph osd crush add-bucket rack3 rack
将三个机柜移动到dc1的root中
# ceph osd crush move rack1 root=dc1# ceph osd crush move rack2 root=dc1# ceph osd crush move rack3 root=dc1
分别将三台主机添加到三个机柜中
# ceph osd crush link serverc rack=rack1# ceph osd crush link serverd rack=rack2# ceph osd crush link servere rack=rack3
添加crush rule定义故障域为机柜级别
#ceph osd crush rule create-replicated indc1 dc1 rack
- 创建一个存储池,应用新的crush rule
# ceph osd pool create rackpool 32 32 replicated indc1;ceph osd pool get rackpool all
- 添加一个数据,查看pg状态
# rados -p rackpool put test ceph.conf# ceph osd map rackpool test
创建一个基于ssd的池
假设每台主机的最后一个osd为ssd
# for i in 0 3 6;do ceph osd crush rm-device-class osd.$i;done# for i in 0 3 6;do ceph osd crush set-device-class ssd osd.$i;done# ceph osd crush class ls# ceph osd crush rule create-replicated ssd_rule default host ssd# ceph osd crush rule ls
创建基于ssd_rule规则的存储池
# ceph osd pool create cache 64 64 ssd_rule
- 将一个现有的池迁移至ssd的osd上
#ceph osd pool set cephfs_metadata crush_rule ssd_rule
- 写入数据,测试数据分布
# rados -p cache put test test.txt# ceph osd map cache test
管理Ceph集群
Cluster Map简介
- cluster map由monitor维护,用于跟踪ceph集群状态
- 当client启动时,会连接monitor获取cluster map副本,发现所有其他组件的位置,然后直接与所需的进程通信,以存储和检索数据
- monitor跟踪这些集群组件的状态,也负责管理守护进程和客户端之间的身份验证
- cluster map实际是多种map的集合,包含:monitor map、osd map、pg map、mds map、mgr map、service map
Cluster Map内容
- monitor map:包含集群ID、monitor节点名称、IP以及端口号以及monitor map的版本号
- OSD map:包含集群ID、自身的版本号以及存储池相关的信息,包括存储池名称、ID、类型、副本级别和PG。还包括OSD的信息,比如数量、状态、权限以及OSD节点信息
- PG map:包含PG的版本、时间戳、OSD map的最新版本号、容量相关的百分比。还记录了每个PG的ID、对象数量、状态、状态时间戳等
- MDS map:包含MDS的地址、状态、数据池和元数据池的ID
- MGR map:包含MGR的地址和状态,以及可用和已启用模块的列表
- service map:跟踪通过librados部署的一些服务的实例,如RGW、rbd-mirror等。service map收集这些服务的信息然后提供给其他服务,如MGR的dashboard插件使用该map报告这些客户端服务的状态
Cluster Map基本查询
ceph mon dumpceph osd dumpceph osd crush dumpceph pg dump allceph fs dumpceph mgr dumpceph service dump
多Monitor同步机制
- 在生产环境建议最少三节点monitor,以确保cluster map的高可用性和冗余性
- monitor使用paxos算法作为集群状态上达成一致的机制。paxos是一种分布式一致性算法。每当monitor修改map时,它会通过paxos发送更新到其他monitor。Ceph只有在大多数monitor就更新达成一致时提交map的新版本
- cluster map的更新操作需要Paxos确认,但是读操作不经由Paxos,而是直接访问本地的kv存储
Monitor选举机制
- 多个monitor之间需要建立仲裁并选择出一个leader,其他节点则作为工作节点(peon)
- 在选举完成并确定leader之后,leader将从所有其他monitor请求最新的map epoc,以确保leader具有集群的最新视图
- 要维护monitor集群的正常工作,必须有超过半数的节点正常
Monitor租期
- 在Monitor建立仲裁后,leader开始分发短期的租约到所有的monitors。让它们能够分发cluster map到OSD和client
- Monitor租约默认每3s续期一次
- 当peon monitor没有确认它收到租约时,leader假定该monitor异常,它会召集新的选举以建立仲裁
- 如果peon monitor的租约到期后没有收到leader的续期,它会假定leader异常,并会召集新的选举
OSD map生命周期
- 每当OSD加入或离开集群时,Ceph都会更新OSD map
- OSD不使用leader来管理OSD map,它们会在自身之间传播map。OSD会利用OSD map epoch标记它们交换的每一条信息,当OSD检测到自己已落后时,它会使用其对等OSD执行map更新
- 在大型集群中OSD map更新会非常频繁,节点会执行递增map更新
- Ceph也会利用epoch来标记OSD和client之间的消息。当client连接到OSD时OSD会检查epoch。如果发现epoch不匹配,则OSD会以正确的epoch响应,以便客户端可以更新其OSD map
- OSD定期向monitor报告自己的状态,OSD之间会交换心跳,以便检测对等点的故障,并报告给monitor
- leader monitor发现OSD故障时,它会更新map,递增epoch,并使用Paxos更新协议来通知其他monitor,同时撤销租约,并发布新的租约,以使monitor以分发最新的OSD map
Ceph 集群运行状况诊断
- 集群状态:
HEALTH_OKHEALTH_WARNHEALTH_ERR
- 常用查询状态指令:
ceph health detailceph -sceph -w
设置集群标志
noup:OSD启动时,会将自己在MON上标识为UP状态,设置该标志位,则OSD不会被自动标识为up状态nodown:OSD停止时,MON会将OSD标识为down状态,设置该标志位,则MON不会将停止的OSD标识为down状态,设置noup和nodown可以防止网络抖动noout:设置该标志位,则mon不会从crush映射中删除任何OSD。对OSD作维护时,可设置该标志位,以防止CRUSH在OSD停止时自动重平衡数据。OSD重新启动时,需要清除该flagnoin:设置该标志位,可以防止数据被自动分配到OSD上norecover:设置该flag,禁止任何集群恢复操作。在执行维护和停机时,可设置该flagnobackfill:禁止数据回填noscrub:禁止清理操作。清理PG会在短期内影响OSD的操作。在低带宽集群中,清理期间如果OSD的速度过慢,则会被标记为down。可以该标记来防止这种情况发生nodeep-scrub:禁止深度清理norebalance:禁止重平衡数据。在执行集群维护或者停机时,可以使用该flagpause:设置该标志位,则集群停止读写,但不影响osd自检full:标记集群已满,将拒绝任何数据写入,但可读
集群flag操作
- 只能对整个集群操作,不能针对单个osd
语法
ceph osd set <flag>ceph osd unset <flag>
示例:
ceph osd set nodownceph osd unset nodownceph -s
验证OSD状态
- OSD运行状态
- up
- down
- out
- in
- OSD容量状态
- nearfull
- full
- 常用指令
- ceph osd stat # 显示OSD状态
- ceph osd df # 报告osd使用量
- ceph osd find #查找指定osd位置
管理OSD容量
- 当集群容量达到mon_osd_nearfull_ratio的值时,集群会进入HEALTH_WARN状态。这是为了在达到full_ratio之前,提醒添加OSD。默认设置为0.85,即85%
当集群容量达到mon_osd_full_ratio的值时,集群将停止写入,但允许读取。集群会进入到HEALTH_ERR状态。默认为0.95,即95%。这是为了防止当一个或多个OSD故障时仍留有余地能恢复数据
设置方法:
ceph osd set-full-ratio 0.95ceph osd set-nearfull-ratio 0.85ceph osd dump
OSD状态解读
- 正常状态的OSD为up且in
- 当OSD故障时,守护进程offline,在5分钟内,集群仍会将其标记为down和in,这是为了防止网络抖动
- 如果5分钟内仍未恢复,则会标记为down和out。此时该OSD上的PG开始迁移。这个5分钟的时间间隔可以通过mon_osd_down_out_interval配置项修改
- 当故障的OSD重新上线以后,会触发新的数据再平衡
- 当集群有noout标志位时,则osd下线不会导致数据恢复
- OSD每隔6s会互相验证状态。并每隔120s向mon报告一次状态。
OSD心跳参数
osd_heartbeat_interval # osd发送heartbeat给其他osd的间隔时间osd_heartbeat_grace # 一个osd多久没心跳,就会被集群认为它down了mon_osd_min_down_reporters # 确定一个osd状态为down的最少报告来源osd数mon_osd_min_down_reports # 一个OSD必须重复报告一个osd状态为down的次数mon_osd_down_out_interval # 当osd停止响应多长时间,将其标记为down和outmon_osd_report_timeout # mon标记一个osd为down的最长等待时间osd_mon_report_interval_min # 一个新的osd加入集群时,等待多长时间,开始向monitor报osd_mon_report_interval_max # monitor允许osd报告的最大间隔,超时就认为它down了osd_mon_heartbeat_interval # osd向monitor报告心跳的时间
管理文件到PG映射
示例
[root@serverc ~]# rados -p test put test /etc/ceph/ceph.conf
[root@serverc ~]# ceph osd map test test
osdmap e201 pool 'test' (10) object 'test' -> pg 10.40e8aab5 (10.35) -> up ([2,1,8], p2) acting ([2,1,8], p2)
- test对象所在pg id为10.35,存储在三个osd上,分别为osd.2、osd.1和osd.8,其中osd.2为primary osd
- 处于up状态的osd会一直留在PG的up set和acting set中,一旦主osd down,它首先会从up set中移除,然后从acting set中移除,之后从OSD将被升级为主。Ceph会将故障OSD上的PG恢复到一个新OSD上,然后再将这个新OSD加入到up和acting set中来维持集群的高可用性
PG状态解读
Creating:PG正在被创建。通常当存储池被创建或者PG的数目被修改时,会出现这种状态Active:PG处于活跃状态。可被正常读写Clean:PG中的所有对象都被复制了规定的副本数Down:PG离线Replay:当某个OSD异常后,PG正在等待重新发起操作Splitting:PG正在被分割,通常在一个存储池的PG数增加后出现,现有的PG会被分割,部分对象被移动到新的PGScrubbing:PG正在做不一致校验Degraded:PG中部分对象的副本数未达到规定数目Inconsistent:PG的副本出现了不一致。如果出现副本不一致,可使用ceph pg repair来修复不一致情况Peering:Perring是由主OSD发起的使用存放PG副本的所有OSD就PG的所有对象和元数据的状态达成一致的过程。Peering完成后,主OSD才会接受客户端写请求Repair:PG正在被检查,并尝试修改被发现的不一致情况Recovering:PG正在迁移或同步对象及副本。通常是一个OSD down掉之后的恢复过程Backfill:一个新OSD加入集群后,CRUSH会把集群现有的一部分PG分配给它,被称之为数据回填Backfill-wait:PG正在等待开始数据回填操作Incomplete:PG日志中缺失了一关键时间段的数据。当包含PG所需信息的某OSD不可用时,会出现这种情况Stale:PG处理未知状态。monitors在PG map改变后还没收到过PG的更新。集群刚启动时,在Peering结束前会出现该状态Remapped:当PG的acting set变化后,数据将会从旧acting set迁移到新acting set。新主OSD需要一段时间后才能提供服务。因此这会让老的OSD继续提供服务,直到PG迁移完成。在这段时间,PG状态就会出现Remapped
手动控制PG的Primary OSD
- 可以通过手动修改osd的权重以提升 特定OSD被选为PG Primary OSD的概率,避免将速度慢的磁盘用作primary osd
- 需要先在配置文件中配置如下参数:
mon_osd_allow_primary_affinity = true
- 调整权重示例:
- 查看现在有多少PG的主OSD是osd.0
ceph pg dump |grep active+clean |egrep "\[0," |wc -l
- 修改osd.0的权重
ceph osd primary-affinity osd.0 0# 权重范围从0.0到1.0
- 再次查看现在有多少PG的主OSD是osd.0
ceph pg dump |grep active+clean |egrep "\[0," |wc -l
- 查看现在有多少PG的主OSD是osd.0
移除故障OSD
方法一
# ceph osd out osd.3
# systemctl stop ceph-osd@3
# ceph osd crush remove osd.3
# ceph osd auth del osd.3
# ceph osd rm osd.3
删除配置文件中针对该osd的配置
方法二
# ceph osd out osd.3
# systemctl stop ceph-osd@3
# ceph osd purge osd.3
删除配置文件中针对该osd的配置
移除故障节点
方法一
- 先移除节点上所有osd
ceph osd crush remove serverc
方法二:
- 先迁移节点上所有osd
- 修改crushmap,删除所有与该节点相关的配置
恢复和回填OSD
- 在OSD添加或移除时,Ceph会重平衡PG。数据回填和恢复操作可能会产生大量的后端流量,影响集群性能。
- 为避免性能降低,可对回填/恢复操作进行配置:
osd_recovery_op_priority# 值为1-63,默认为10,osd_client_op_priority#默认客户端操作的优先级为63osd_recovery_max_active# 每个osd一次处理的活跃恢复请求数量,默认为15,增大此值可加速恢复,但会增加集群负载osd_recovery_threads# 用于数据恢复时的线程数,默认为1osd_max_backfills# 单个osd的最大回填操作数,默认为10osd_backfill_scan_min# 回填操作时最小扫描对象数量,默认为64osd_backfill_scan_max# 回填操作的最大扫描对象数量,默认为512osd_backfill_full_ratio# osd的占满率达到多少时,拒绝接受回填请求,默认为0.85osd_backfill_retry_interval# 回填重试的时间间隔
故障排查
- 确认所有安装步骤正确
- 确认配置文件正确配置
- 确认密钥权限正确配置
- 对于rbd确认是否正确开启特性
- 通过
ceph -s或者ceph health detail等指令诊断系统异常 - 将进程在前台运行,并开启
debug - 查看进程相关日志
- 开启
debug日志,如rgw_enable_ops_log和rgw_enable_usage_log
Ceph 性能调优
整体系统架构优化
- 选择正确的CPU和内存。OSD、MON和MDS节点具有不同的CPU和内存需求
- 尽可能关闭NUMA
- 规划好存储节点的数据以及各节点的磁盘要求
- 磁盘的选择尽可能在成本、吞吐量和延迟之间找到良好的平衡
- journal日志应该使用SSD
- 如果交换机支持(MTU 9000),则启用巨型帧。
- 启用ntp。Ceph对时间敏感
- 集群网络至少10GB带宽
快速调优系统
- 使用tuned-admin工具,它可帮助系统管理员针对不同的工作负载进行系统调优
tuned-adm list# 列出现有可用的profiletuned-adm active# 查看当前生效的profiletuned-adm profile profile-name# 使用指定的profiletuned-adm off# 禁用所有的profile
- tuned-admin使用的profile默认存放在
/usr/lib/tuned/<profile-name>目录中,可以参考其模板来自定义profile - 对于ceph而言,
network-latency可以改进全局系统延迟,network-throughput可以改进全局系统吞吐量
IO调度算法
noop:电梯算法,实现了一个简单的FIFO队列。基于SSD的磁盘,推荐使用这种调度方式Deadline:截止时间调度算法,尽力为请求提供有保障的延迟。对于Ceph,基于sata或者sas的驱动器,应该首选这种调度方式cfq:完全公平队列,适合有许多进程同时读取和写入大小不等的请求的磁盘,也是默认的通用调度算法- 查看当前系统支持的调度算法:
dmesg|grep -I scheduler
- 查看指定磁盘使用的调度算法:
cat /sys/block/vdb/queue/scheduler
- 修改调度算法
echo "deadline" > /sys/block/vdb/queue/scheduler# vim /etc/default/grub
GRUB_CMDLINE_LINUX="elevator=deadline numa=off"
网络IO子系统调优
- 用于集群的网络建议尽可能使用10Gb网络
- 以下参数用于缓冲区内存管理
net.ipv4.tcp_wmem#设置OS接收缓冲区的内存大小,第一个值告知内核一个TCP socket的最小缓冲区空间,第二值为默认缓冲区空间,第三个值是最大缓冲区空间net.ipv4.tcp_rmem#设置Os发送缓冲区的内存大小net.ipv4.tcp_mem#定义TCP stack如何反应内存使用情况- 交换机启用大型帧
- 默认情况下,以太网最大传输数据包大小为1500字节。为提高吞吐量并减少处理开销,一种策略是将以太网网络配置为允许设备发送和接收更大的巨型帧。
- 在使用巨型帧的要谨慎,因为需要硬件支持,且全部以太网口配置为相同的巨型帧MTU大小。
虚拟内存调优
vm.dirty_background_ratio# 某个进程脏数据占总系统总内存的百分比,达到此比率时内核会开始在后台写出数据vm.dirty_ratio# 脏内存占总系统总内存的百分比,达到此比率时写入进程停滞,而系统会将内存页清空到后端存储- 设置较低的比率会导致高频但用时短的写操作,这适合Ceph等I/O密集型应用。设置较高的比率会导致低频但用时长的写操作,这会产生较小的系统开销,但可能会造成应用响应时间变长
vm.swappiness# 控制交换分区的使用,建议设置为10vm.min_free_kbytes# 系统尽力保持可用状态的RAM大小。在一个RAM大于48G的系统上,建议设置为4G
文件系统调优
- 格式化xfs文件系统的时候,使用
osd_mkfs_options_xfs指定的参数,默认为-f -i size=2048 - 挂载xfs文件系统的时候,使用
osd_mount_options_xfs指定的参数,默认为noatime,largeio,inode64,swalloc
Ceph部署最佳实践
- MON的性能对集群总体性能至关重要,应用部署于专用节点,为确保正确仲裁,数量应为奇数个
- 在OSD节点上,操作系统、OSD数据、OSD日志应当位于独立的磁盘上,以确保满意的吞吐量
- 在集群安装后,需要监控集群、排除故障并维护,尽管 Ceph具有自愈功能。如果发生性能问题,首先在磁盘、网络和硬件层面上排查。然后逐步转向RADOS块设备和Ceph对象网关
OSD建议
- 更快的日志性能可以改进响应时间,建议将单独的低延迟SSD或者NVMe设备用于OSD日志。
- 多个日志可以共享同一SSD,以降低存储基础架构的成本。但是不能将过多OSD日志放在同一设备上。
- 建议每个SATA OSD设备不超过6个OSD日志,每个NVMe设备不超过12个OSD日志。
- 需要说明的是,当用于托管日志的SSD或者NVMe设备故障时,使用它托管其日志的所有OSD也都变得不可用
RBD建议
- 块设备上的工作负载通常是I/O密集型负载,例如在OpenStack中虚拟机上运行数据库。
- 对于RBD,OSD日志应当位于SSD或者NVMe设备上
- 对后端存储,可以使用不同的存储设备以提供不同级别的服务
Ceph对象网关建议
- Ceph对象网关工作负载通常是吞吐密集型负载。但是其bucket索引池为I/O密集型工作负载模式。应当将这个池存储在SSD设备上
- Ceph对象网关为每个存储桶维护一个索引。Ceph将这一索引存储在RADOS对象中。当存储桶存储数量巨大的对象时(超过100000个),索引性能会降低,因为只有一个RADOS对象参与所有索引操作。
- Ceph可以在多个RADOS对象或分片中保存大型索引。可以在ceph.conf中设置
rgw_override_bucket_index_max_shards配置参数来启用该功能。此参数的建议值是存储桶中预计对象数量除以10000 - 随着索引变大,Ceph通常需要重新划分存储桶。
rgw_dynamic_resharding配置控制该功能,默认为true
CephFS建议
- 存放目录结构和其他索引的元数据池可能会成为CephFS的瓶颈。因此,应该将SSD设备用于这个池
- 每个MDS维护一个内存中缓存 ,用于索引节点等不同类型的项目。Ceph使用mds_cache_memory_limit配置参数限制这一缓存的大小。其默认值为1GB,可以在需要时调整,得不得超过系统总内存数
将OSD日志移到SSD
ceph osd set noout
systemctl stop ceph-osd@3
ceph-osd -i 3 --flush-journal
rm -f /var/lib/ceph/osd/ceph-3/journal
ln -s /dev/sdc1 /var/lib/ceph/osd/ceph-3/journal
ceph-osd -i 3 --mkjournal
systemctl start ceph-osd@3
ceph osd unset noout
存储池中PG的计算方法
- 通常,计算一个池中应该有多少个归置组的计算方法如下:
100 * OSDs / size(副本数)
- 一种比较通用的取值规则:
- 少于5个OSD时可把pg_num设置为128
- OSD数量在5到10个时,可把pg_num设置为512
- OSD数量在10到50个时,可把pg_num设置为4096
- OSD数量大于50时,建议自行计算
- 自行计算pg_num聚会时的工具
PG与PGP
- 通常而言,PG与PGP是相同的
- 当我们为一个池增加PG时,PG会开始分裂,这个时候,OSD上的数据开始移动到新的PG,但总体而言,此时,数据还是在一个OSD的不同PG中迁移
- 而我们一旦同时增加了PGP,则PG开始在多个OSD上重平衡,这时会出现跨OSD的数据迁移
- 建议的做法是将pg_num直接设置为希望作为最终值的PG数量,而PGP的数量应当慢慢增加,以确保集群不会因为一段时间内的大量数据重平衡而导致的性能下降
Ceph网络
- 尽可能使用10Gb网络带宽
- 尽可能使用不同的cluster网络和public网络
- 网络监控
OSD建议硬件
- 将一个raid1磁盘用于操作系统
- 每个OSD一块硬盘,将SSD或者NVMe用于日志
- 使用多个10Gb网卡,每个网络一个双链路绑定
- 每个OSD预留1个CPU,每个逻辑核心1GHz
- 分配16GB内存,外加每个OSD 2G内存
MON建议硬件
- 每个MON一个独立的服务器
- 小型和中型集群,使用10000RPM的磁盘,大型集群使用SSD
- 每个网络使用双链路绑定
- 使用一个多核CPU
- 最少16G内存
rados bench性能测试
rados bench -p <pool_name> <seconds> <write|seq|rand> -b <block size> -t --no-cleanuppool_name测试所针对的池seconds测试所持续的时间,以秒为单位<write|seq|rand>操作模式,分别是写、顺序读、随机读-b <block_size>块大小,默认是4M-t读/写的并行数,默认为16- —no-cleanup` 表示测试完成后不删除测试用的数据。在做读测试之前,需要使用该参数来运行一遍写测试来产生测试数据,在全部测试完成以后,可以行rados -p
cleanup来清理所有测试数据
- 示例:
rados bench -p rbd 10 write --no-cleanuprados bench -p rbd 10 seq
rbd bench性能测试
rbd bench -p <pool_name> <image_name> --io-type <write|read> --io-size <size> --io-threads <num> --io-total <size> --io-pattern <seq|rand>--io-type测试类型,读/写--io-size字节数,默认4096--io-threads线程数,默认16--io-total读/写的总大小,默认1GB--io-pattern读/写的方式,顺序还是随机
- 示例:
其他性能测试工具
ddecho 3 > /proc/sys/vm/drop_cachesdd if=/dev/zero of=/var/lib/ceph/osd/ceph-0/test.img bs=4M count=1024 oflag=directdd if=/var/lib/ceph/osd/ceph-0/test.img of=/dev/null bs=4M count=1024 oflag=direct
fio
监控OSD和数据一致性
- 清理:检查对象的存在性、校验和以及大小
- 深度清理:检查对象的存在性和大小,重新计算并验证对象的校验和。
- 清理会影响ceph集群性能,但建议不要禁用此功能,因为它能提供完数据的完整性
- 清理的调优参数:
osd_scrub_begin_hour = begin_hour# 取值范围0-24osd_scrub_end_hour = end_hour# 取值范围0-24osd_scrub_load_threshold# 当系统负载低于多少的时候可以清理,默认为0.5osd_scrub_min_interval# 多久清理一次,默认是一天一次(前提是系统负载低于上一个参数的设定)osd_scrub_interval_randomize_ratio# 在清理的时候,随机延迟的值,默认是0.5osd_scrub_max_interval# 清理的最大间隔时间,默认是一周(如果一周内没清理过,这次就必须清理,不管负载是多少)osd_scrub_priority# 清理的优先级,默认是5osd_deep_scrub_interal# 深度清理的时间间隔,默认是一周osd_scrub_sleep# 当有磁盘读取时,则暂停清理,增加此值可减缓清理的速度以降低对客户端的影响,默认为0,范围0-1
监控OSD和数据一致性
- 显示最近发生的清理和深度清理
ceph pg dump all# 查看LAST_SCRUB和LAST_DEEP_SCRUB
- 将清理调度到特定的pg
ceph pg scrub pg-id
- 将深度清理调度到特定的pg
ceph pg deep-scrub pg-id
- 为设定的池设定清理参数
ceph osd pool set <pool-name> <parameter> <value>noscrub# 不清理,默认为falsenodeep-scrub# 不深度清理,默认为falsescrub_min_interval# 如果设置为0,则应用全局配置osd_scrub_min_intervalscrub_max_interval# 如果设置为0,则应用全局配置osd_scrub_max_intervaldeep_scrub_interval# 如果设置为0,则应用全局配置osd_scrub_interval
修剪快照和OSD
- 快照在池级别和RBD级别上提供。当快照被移除时,ceph会以异步操作的形式删除快照数据,称为快照修剪进程
- 为减轻快照修剪进程会影响集群总体性能。可以通过配置
osd_snap_trim_sleep来在有客户端读写操作的时候暂停修剪,参数的值范围是0到1 - 快照修剪的优先级通过使用
osd_snap_trim_priority参数控制,默认为5
保护数据和OSD
- 需要控制回填和恢复操作,以限制这些操作对ceph性能的影响
- 回填发生于新的osd加入集群时,或者osd死机并且ceph将其pg分配到其他osd时。在这种场景中,ceph必须要在可用的osd之间复制对象副本
- 恢复发生于新的osd已有数据时,如出现短暂停机。在这种情形下,ceph会简单的重放pg日志
- 管理回填和恢复操作的配置项
osd_max_backfills# 用于限制每个osd上用于回填的并发操作数,默认为10osd_recovery_max_active# 用于限制每个osd上用于恢复的并发操作数,默认为0,以使用osd_recovery_max_active_hdd或者osd_recovery_max_active_ssd默认值,前者为3,后者为10osd_recovery_op_priority# 恢复操作的优先级,默认为10