






[toc]
python 文件的IO三

CSV文件
csv文件简介
逗号分隔值 Comma-Separated Values。
CSV是一个被行分隔符、列分隔符分成行和列的文本文件;
没有指定字符编码。
参看RFC4180
行分隔符为\r\n,最后一行可以没有换行符;
列分隔符常为逗号或者制表符;
每一行为一条记录record。
字段可以使用双引号括起来,也可以不使用。如果字段中出现了双引号、逗号、换行符必须使用双引号括起来。如果字段的值是双引号,使用两个双引号表示一个转义。
表头可选,和段列对就就可以了。
csv生成测试
s = """
1,tom,20
2,jerry,16,
"""
with open('./test.csv','w') as f:
for line in s.splitlines():
f.write(line + '\n')
from pathlib import Path
p = Path('./tmp/myscv.test.csv')
parent = p.parent
if not parent.exists():
parent.mkdir(parents=True)
csv_body= '''
id,name,age,comment
1,zs,18,"I'm18"
2,ls,20,"This is a ""test"" string."
3,ww,23,"中国
国庆
"
'''
p.write_text(csv_body)
scv 模块
reader(csvfile,dialect=’excel’,**fmtparams)
返回DictReader的实例,是个行迭代器;
delimiter 列分隔符逗号
lineterminator 行分隔符\r\n
quotechar 字段的引用符号,缺少为”, 双引号
双引号的处理:
doublequote比引号的处理,默认为True。如果和quoterchar为同一个,True则使用2个双引号表示;
False表示使用转义字符将作为双引号的前缀;
escapechar一个转义字符,默认为None;
quoting指定双引号的规则。QUOTE_ALL所有字段;QUOTE_MINIMAL特殊符字段;
QUOtE_NONNUMERIC非数字字段; QUOTE_NONE都不使用引号。
write(csvfile,dialect=’excel’,**fmtparams)
返回DictWriter的实例。
主要方法有writerow、writerows。
from pathlib import Path
import csv
path = './csv/test.csv'
p = Path(path)
if not p.parent.exists():
p.parent.mkdir(parents=True)
line1 = [1,'tom',20,'']
line2 = [2,'tom',20,'']
line3 = [line1,line2]
s = """\
1,tom,20,
2,jerry,16,
3,,,
"""
with open(path,'w') as f:
writer = csv.writer(f)
writer.writerow(line1)
writer.writerow(line2)
writer.writerows(line3)
with open(path) as f :
reader = csv.reader(f)
for line in reader:
if line:
print(line)
ini 文件处理
作为配置文件,ini文件格式的很流行。
[DEFAULT]
a = test
[mysql]
default-character-set = utf8
[mysqld]
datadir = /dbserver/data
prot = 33060
character-set-sever=utf8
sql_mode=NO_ENGIN_SUBSITUTION,STRICT_TRANS_TABLES
configparser
configparser模块的ConfigParser类就是用来操作
read(filenames, endcoding=None)
读取ini文件,可以是单个文件,也可以是文件列表。可以指定文件编码;
sections()返回section列表。缺省section不包括在内;
add_section(section_name)增加一个section;
has_section(section_name)判断section是否存在;
opentions(section)返回section的所有option;
get(section,option,*,raw=False,vars=None[,fallback])
从指定的段的选项上取值,如果找到返回,如果没有找到就去找DEFAULT段有没有;
getint(section,option,,raw=False,vars=None[,fallback])
getfloat(section,option,raw=Flase,vars=None[,fallback])
getboolean(section,option,*,raw=False,vars=None[,fallback])
上面3 个方法和get一样,返回指定定类型数据
items(raw=False,vars=None)
items(section,raw=Fase,vars=None)
没有section,则返回所有section名字及其对象;如果指定section,则返回这个section的键值对组成二元组;
set(section,option,value)
section存在的情况下,写入option=value,要求option、value必须是字符串;
remove_section(section)
移除section及其所有option
remove_option(section,option)
移除section下的option。
write(fileobject,space_around_delimiters=True)
将当前config的所有的内容写入fileobject中,一般open的函数使用w模式;
from configparser import ConfigParser
cfg = ConfigParser()
cfg.read('./mysql.ini')
print(cfg.sections())
for section in cfg.sections():
# for opt in cfg.options(section):
# print(section,opt)
for k,v in cfg.items(section):
print(k,v)
if not cfg.has_section('test'):
cfg.add_section('test')
cfg.set('test','test1','123')
cfg.set('test','test2','abc')
with open('./mysql.ini','w') as f:
cfg.write(f)
写入后如下
[DEFAULT]
a = test
[mysql]
default-character-set = utf8
[mysqld]
datadir = /dbserver/data
prot = 33060
character-set-sever = utf8
sql_mode = NO_ENGIN_SUBSITUTION,STRICT_TRANS_TABLES
[test]
test1 = 123
test2 = abc
获取
from configparser import ConfigParser
cfg = ConfigParser()
cfg.read('./mysql.ini')
print(cfg.sections())
for section in cfg.sections():
# for opt in cfg.options(section):
# print(section,opt)
for k,v in cfg.items(section):
print(k,v)
# if not cfg.has_section('test'):
# cfg.add_section('test')
# cfg.set('test','test1','123')
# cfg.set('test','test2','abc')
#
# with open('./mysql.ini','w') as f:
# cfg.write(f)
print('!'*50)
a = cfg.get('test','test1')
print(a,type(a))
b = cfg.getint('test','test1')
print(b+1,type(b))
# 输出
['mysql', 'mysqld', 'test']
a test
default-character-set utf8
a test
datadir /dbserver/data
prot 33060
character-set-sever utf8
sql_mode NO_ENGIN_SUBSITUTION,STRICT_TRANS_TABLES
a test
test1 123
test2 abc
!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
123 <class 'str'>
124 <class 'int'>
序列化和反序列化
为什么要序列化
内存中的字典,链表如何保存到一个文件中 ?
如果是自己定义的类的实例,如何保存到一个文件中?
如何从文件中读取数据,并让它们的内存中再次变成自己对应的类的实例 ?
要设计一套协议,按照某种规则,把内存中数据保存到文件中。文件是一个字节序列,所以必须把数据转换成字节序列,输出到文件。这就是序列化。反之,从文件的字节序列恢复到内存,就是反序列化。
定义
serialization序列化
将内存中的对象存储下来,把它变成一个个字节。 -> 二进制
deserialization反序列化
将文件中的一个个字恢复成内存中对象。 <- 二进制
序列化保存到文件 就是持久化;
可以将数据序列化后持久化,或者网络传输;也可以将从文件中或者网络接收到的字节序列反序列化;
Python提供了pickle库。
pickle库
Python中的序列化、反序列化模块;
dumps对象序列化;
dump对象列化到文件对象,就是存入文件;
loads 对象反序列化;
load 对象反序列化,从文件读取数据
from pathlib import Path
import pickle
lst = 'a b c'.split(' ')
d = dict(zip('abc',range(3)))
class AA:
def show(self):
a = 'abcdefghijklmn1230456789'
print(a)
aa = AA()
with open('./bin','wb') as f:
# pickle.dump(lst,f)
# pickle.dump(d,f)
pickle.dump(aa,f)
with open('./bin','rb') as f:
tmp = pickle.load(f)
print(type(tmp))
tt = tmp
tmp.show()
文件序列化和反序列化
import pickle
class AA:
def show(self):
print('123')
with open('bin','rb') as f:
t = pickle.load(f)
t.show()
对象序列化
import pickle
class AA:
tttt = 'ABC'
def show(self):
print('abc')
a1 = AA()
sr = pickle.dumps(a1)
print('sr={}'.format(sr)) # AA
a2 = pickle.loads(sr)
print(a2.tttt)
a2.show()
上面的例子中,其实就保存了一个类名,因为所有的东西都是类定义的东西,是不变的,所以只序列化一个AA类名。反序列化的时候找到类可以恢复一个对象。
import pickle
class AAA:
def __ini__(self):
self.tttt = 'abc'
b1 = AAA()
sr = pickle.dumps(bs)
print('sr={}'.format(sr))
b2 = pickle.loads(sr)
print(b2.tttt)
可以看出,保存了AAA、ttt 和abc,因为每一个对象每次都是变化的。但是反序列化的时候要找到AAA类的定义,才能成功。否则会抛出异常;
这样可以理解,反序列化的时候,类是模子,二进制序列就是铁水。
应用
本地序列化的情况应用较少;
一般来说大多场景都应用在网络中。将数据序列化通过网络传输到远程节点,远程服务器上的接收到数据反序列化后,就可以使用了;
但是,要注意一点,远程接收端,反序列化时必须有对应的数据类型,否则就会报错。尤其是自定义类型,必须远程得有。
实验
class AA:
def __init__(self):
self.tttt = 'abc'
aaa = AA()
sr = pickle.dumps(aaa)
print(len(sr))
file = './ser'
with open(file, 'wb') as f:
pickle.dump(aaa,f)
将生产的充列化文件发往其它节点,运行:
with open('ser','rb') as f:
a = pickle.load(f)
增加类定义即可解决
现在大多数项目,都不是单机的,也不是单服务的,需要通过网络数据传送到其它节点上去,这就需要大量的序列化,反序列化。
但是,问题是,Python 程序之间还可以通过pickle解决序列化、反序列化,如果是跨平台、跨语言、跨协议pickle就不太合适了,就需要共公的协议。 如XML、Json、ProtocolBuffer 等。
不同的协议,效率不同,学习曲线不同,适用的场景不同,要根据不同情况造型。
Json
Json(Javascript Object Notation JS标记对象), 是一种轻量级的数据交互格式。它基于ECMASciprt(w3c制定的JS规范)的一个子集。采用完全独立的编程语言文本格式来存储和表示数据;
Json 数据类型
值
双引号引起来的字符串,数值。 True和False,null,对象,数组这些都是值;
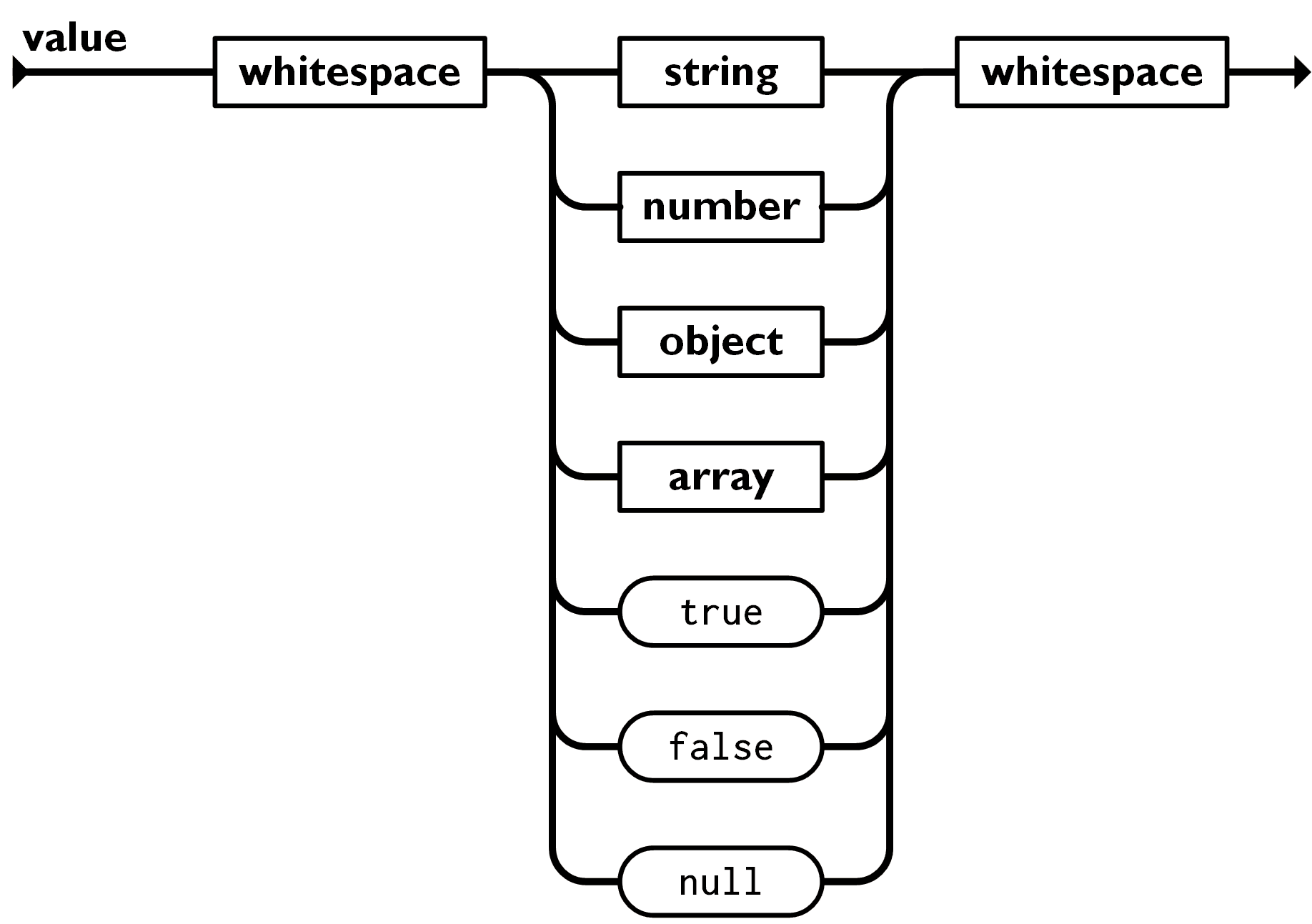
字符串
由双引号包围起来的任意符号组合,可以有转义符;
数值
有负数、有整数、有浮点数;
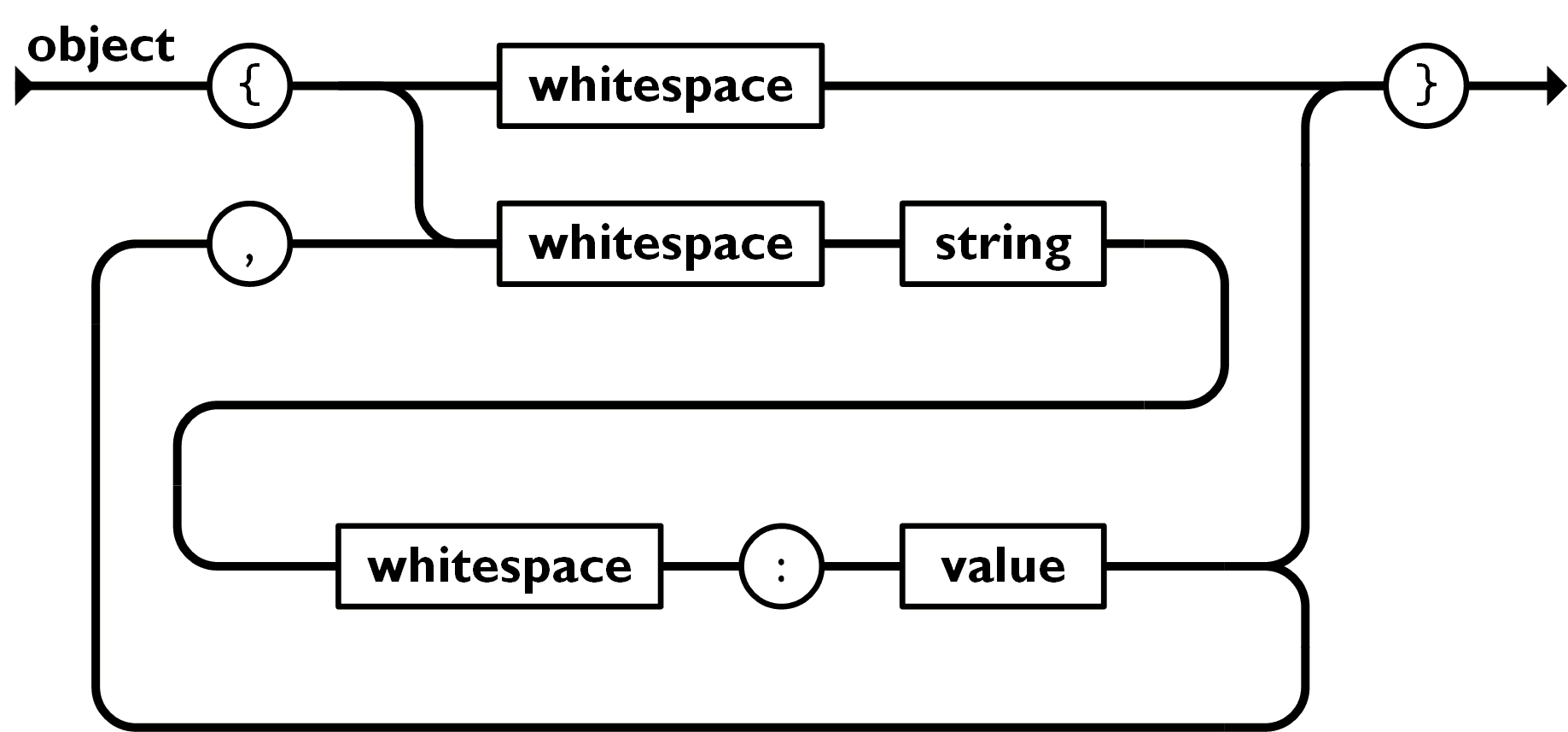
对象
无序的健值对的组合;
格式{key:vluae1 ,...,key:vlualen}
key 必须是一个字符串,需要双引号包围这个字符串;
value 可以是任意合法的值;
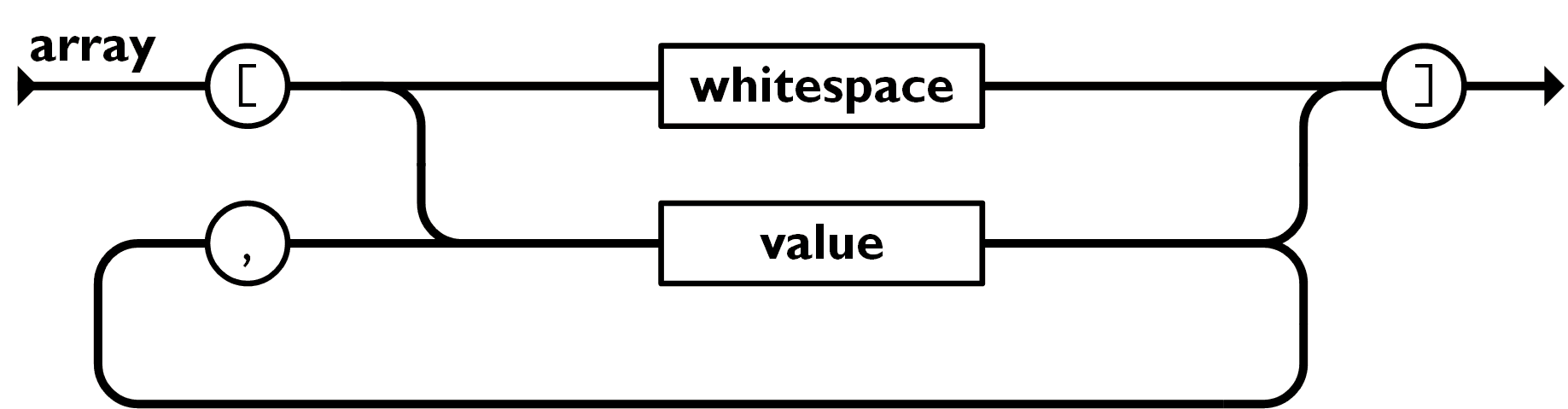
数组
有序的值的集合
格式:[val1,…,valn]
{
"persion": [
{
"n": "tom",
"a": 18
},
{
"n": "jerry",
"age": 16
},
{
"name": "ben",
"age": 24
}
],
"total":2
Python 与 Json
Python支持少量内建数据类型到Json类型的转换。
| Python类型 | Json类型 |
|---|---|
| True | True |
| False | false |
| None | null |
| str | string |
| int | integer |
| float | float |
常用方法
dumps json编码
dumps json编码并存入文件
loads json解码
load json解码,从文件读取数据
import json
d = {'name': 'Tom','age':'20','interset':['music','movie'],'e':False, 'f':None}
j = json.dumps(d)
print(j)
d1 = json.loads(j)
print(d1)
# 输出
{"name": "Tom", "age": "20", "interset": ["music", "movie"], "e": false, "f": null}
{'name': 'Tom', 'age': '20', 'interset': ['music', 'movie'], 'e': False, 'f': None}
一般json编码的数据很少落地,数据都是通过网络传输。传输的时候,要考虑压缩它;
本质上来说 它就是个文本,就是个字符串;
json很简单,几乎语言编程都支持json,所以应用范围十分广泛。
MesagePack
MessagePack 是一个基于二进制高效的对象序列化类库,可用于跨语言通信;
它可以像Json那样,在许多语言之间交换数据对象;
但是它比Json更快速也更轻巧;
支持Python、Ruby、 Java、 C/C++ 等众多语言。宣称比Google Protocol Buffer 还要快4倍;
兼容Json和pickle。
安装
pip install msgpack-python
常用方法
packb 序列化对象。提供了dumps来兼容pickle和json;
unpackb 反充列化对象。提供了loads 来兼容;
pack序列化对象保存到文件对象,提供了dump 来兼容;
unpack 反序列化对象保存到文件对象,提供laod来兼容。
import msgpack
import json
js = '{"person":[{"name":"tom","age":10},{"name":"jerry","age":16},{"name":"ben","age":24}],"total":2}'
d = json.loads(js)
print(d)
msg = msgpack.packb(d)
print(len(msg))
print(msg)
bts = msgpack.unpackb(msg)
print(type(bts))
print(bts)
# 输出
{'person': [{'name': 'tom', 'age': 10}, {'name': 'jerry', 'age': 16}, {'name': 'ben', 'age': 24}], 'total': 2}
63
b'\x82\xa6person\x93\x82\xa4name\xa3tom\xa3age\n\x82\xa4name\xa5jerry\xa3age\x10\x82\xa4name\xa3ben\xa3age\x18\xa5total\x02'
<class 'dict'>
{b'person': [{b'name': b'tom', b'age': 10}, {b'name': b'jerry', b'age': 16}, {b'name': b'ben', b'age': 24}], b'total': 2}
MessagePack简单易,高效压缩,支持语言丰富;
所以,用它序列化也是一种很好的选择;
格言
做一个出乎意料的决定:”好汉打脱呀和血吞”。这是一句湖南的土话,好汉被打家打掉了牙,不要吐出来让别人看到,要咽到肚子里,继续战斗。他不再和长沙官场纠缠争辩,而是卷起铺盖,带着自己募来的湘军。前往僻静的衡阳。全省官员都瞧不起我,我不争一日之短长。等到我在衡阳练成一支劲旅,打几个胜仗给你们看看,那时自会分出高。这才是挽回面子的最好办法—即逆境时不暴露也不让人看到,冷嘲热讽时也不争一日之短长,不争乃大争