






[toc]
python 集合、 字典

集合
- 基本概念
全集:所有元素的集合。例如实数集,所有实数组成的集合就是全集;
子集subset和超集superset: 一个集合A所有元素都在另一个集合B是A的真超集;
并集: 多个集合合并的结果;
交集: 多个集合的公共部分;
差集: 集合中除去和其他集合公共部分。
并集
将多个集合A和B的所有的元素合并到一起union(*others)
返回和多个集合合并后的新的集合
运算符重载,等同unionupdate(*others)
和多个集合合并,就地修改|=
等同update
In [8]: a = {1,2,3}
In [9]: b = {2,3,4}
In [10]: c = b.union(a)
In [11]: c
Out[11]: {1, 2, 3, 4}
In [29]: a = {1,2,3,4}
In [30]: b = {2,3,4,5}
In [31]: b.update(a)
In [32]: b
Out[32]: {1, 2, 3, 4, 5}
交集
- 集合A和B,由所有属于A且属于B的元素组成的集合
intersection(*others) - 返回和多个集合的交集
& 等同insersectionintersection_update(*others)
获取和多个集合的交集,并就地修改&=
等同intersection_update
In [1]: a={1,2,3}
In [2]: b={3,4,5}
In [3]: c = a & b
In [4]: c
Out[4]: {3}
Out[7]: {3}
In [8]: a.intersection_update(b)
In [9]: a
Out[9]: {3}
差集
集合A和B,是所有属于A且不属于B的元素组成的集合difference(*others)
返回和多个集合的差集- 等同differencedifference_update(*others)
获取和多个集合的差集并就地修改-=
等同difference_update
In [10]: a.update({1,2,3,4,5,6})
In [11]: a
Out[11]: {1, 2, 3, 4, 5, 6}
In [12]: b.update({3,4,5})
In [13]: a - b
Out[13]: {1, 2, 6}
In [15]: a -= b
In [16]: a
Out[16]: {1, 2, 6}
对称差集
集合A和B,由所有不属于A和B的交集元素组成的集合,记作(A-B)U(B-A)symmetric_differece(other)
返回和另一个集合的差集^
等同于symmetric_differecesymmetric_differece_update(other)
获取和另一个集合的差集并就地修改^=
等同于symmetric_differece_update
In [17]: a = {1,2,3,4}
In [18]: b = {2,3,4}
In [19]: a ^ b
Out[19]: {1}
In [20]: a ^= b
In [21]: a
Out[21]: {1}
集合运算
issubset(other)、<=
判断当前集合是否是另一个集合的子集set1 < set2
判断set1是否是set2的真子集issuperset(other)、>=
判断当前集合是否是other的超集set1 > set2
判断set1是否是set的真超集isdisjoint(other)
当前集合和另一个集合没有交集
没有交集,返回Ture
In [1]: a = {1,2,3}
In [2]: b = {1,2,3,4}
In [3]: b.issuperset(a)
Out[3]: True
set 和线性结构
- 线性结构的查询时间复杂度是O(n),即随着数据规模的增大而增加耗时
- set、dict 等结构,内部使用hash值作为key,时间复杂度可以做O(1),查询时间和数据规模无关
可hash 的数据类型
数据型 int、float、complex
布尔型 True、False
字符串string、bytes
tuple
None
以上都是不可变类型,成为可哈希类型 ,hashble
- set 的元素必须是可hash的
简单选择排序
- 属于选择排序
- 两两比较在大小,找出极值(极大值或极小值)被放置在固定的位置,这个固定位置一般指的是某一端
- 结果分为升序和降序列
降序
n 个数从左至右,索引从0开始到n-1,两两依次比较,记录大值过引,此轮所有数比较完比,将大数和索引0数效换,如果大数就是索引1,不交换,第二轮,从1开始比较,找到最大值,将它和过引1位置交换,如果它就在过引1 位置则不交换。今次类推,每次左边都会固定下一个大数。
升序
和降序相反
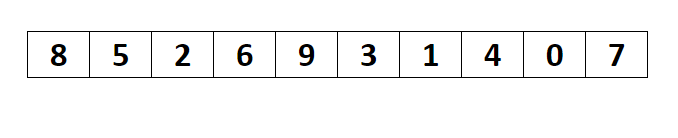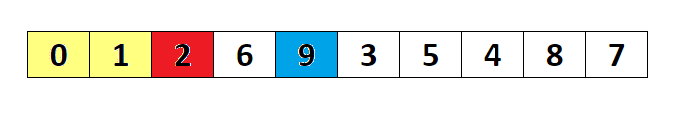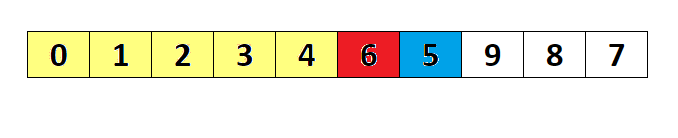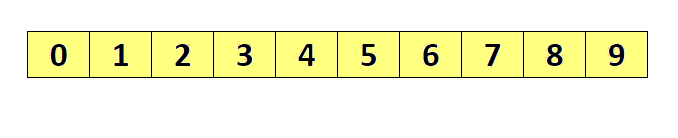
简单选择排序代码实现(一)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
m_list = [
[1,9,8,5,6,7,4,3,2],
[1,2,3,4,5,6,7,8,9],
[9,8,7,6,5,4,3,2,1]
]
nums = m_list[1]
length = len(nums)
print(nums)
count_swap = 0
count_iter = 0
for i in range(length):
maxindex = i
for j in range(i+1,length):
count_iter +=1
if nums[maxindex] < nums[j]:
maxindex = j
if i != maxindex:
tmp = nums[i]
nums[i] = nums[maxindex]
nums[maxindex] = tmp
count_swap +=1
print(nums,count_swap,count_iter)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
[9, 8, 7, 6, 5, 4, 3, 2, 1] 4 36
简单选择排序代码实现(二),二元排序法
#!/usr/bin/env python
# -*- coding: utf-8 -*-
m_list = [
[1,9,8,5,6,7,4,3,2],
[1,2,3,4,5,6,7,8,9],
[9,8,7,6,5,4,3,2,1]
]
nums = m_list[1]
length = len(nums)
print(nums)
count_swap = 0
count_iter = 0
for i in range(length // 2):
maxindex = i
minindex = -i -1
minorigin = minindex
for j in range(i + 1, length -i):
count_iter += 1
if nums[maxindex] < nums[j]:
maxindex = j
if nums[minindex] > nums[-j -1]:
minindex = -j -1
print(maxindex,minindex)
if i != maxindex:
tmp = nums[i]
nums[i] = nums[maxindex]
nums[maxindex] = tmp
count_swap += 1
if i == minindex or i == length + minindex:
minindex = maxindex
if minorigin != minindex:
tmp = nums[minorigin]
nums[minorigin] = nums[minindex]
nums[minindex] = tmp
count_swap +=1
print(nums, count_swap,count_iter)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
1 -2
2 -3
3 -4
4 -5
5 -6
6 -7
7 -8
8 -9
2 -3
3 -4
4 -5
5 -6
6 -7
7 -8
3 -4
4 -5
5 -6
6 -7
4 -5
5 -6
[9, 8, 7, 6, 5, 4, 3, 2, 1] 8 20
简单选择排序总结
- 简单选择排序需要数据一轮轮比较,并在每一轮中发现极值
- 没有办法知道当前轮是否已经达到排序要求,但是可以知道极值是滞在目标索引位置上
- 遍历次数1,…,n-1之后n(n-1)/2
- 时间复杂度O(n2次方)
- 减少了交换次数,提高了效率,性能略好于冒泡法
字典dict
可变的、无序的 、key 不重复
字典dict定义 初始化
- d = dict() 或者
d={} - dict(**kwargs)使用name=value 对初始化一个字典
- dcit(iterable,**kwarg) 使用可迭代对象征和name=value对构造字典,不过可迭代对象的元素必须是一个二元结构
- d = dict(((1,’a’),(2,’b’))) 或者 d = dict(([1,’a’],[2,’b’]))
- dict(mapping, ** kwarg)使用一个字典构建另一个字典
d = {'a':10,'b':20,'c':None,'d':[1,2,3]}
例: 常用的变量赋值
In [1]: d = dict(a=5,b=6,z=[123])
In [2]: d
Out[2]: {'a': 5, 'b': 6, 'z': [123]}
In [43]: d = dict(((1,'a'),))
In [44]: d
Out[44]: {1: 'a'}
In [45]: d = dict(([1,'a'],[2,'b']))
In [46]: d
Out[46]: {1: 'a', 2: 'b'}
类方法使用时需要注意
In [47]: d1 = dict.fromkeys(range(1,11),[1,2])
In [48]: d1
Out[48]:
{1: [1, 2],
2: [1, 2],
3: [1, 2],
4: [1, 2],
5: [1, 2],
6: [1, 2],
7: [1, 2],
8: [1, 2],
9: [1, 2],
10: [1, 2]}
In [49]: d1[10].append(3)
In [50]: d1
Out[50]:
{1: [1, 2, 3],
2: [1, 2, 3],
3: [1, 2, 3],
4: [1, 2, 3],
5: [1, 2, 3],
6: [1, 2, 3],
7: [1, 2, 3],
8: [1, 2, 3],
9: [1, 2, 3],
10: [1, 2, 3]}
字典元素的访问
d[key]
返回key对应的值value
key 不存在抛出KeyError异常get(key[,default])
返回key对应的值value
key不存在返回缺省值,如果没有设置缺省值就返回None- setdefault(key[,default])
返回key对应的值value
key不存在,添加kv对,value为default,并返回default,如果default没有设置,缺省为None
In [51]: d2 = dict(([(1,3,4),{1,2,3,4,5,6}],))
In [52]: d2
Out[52]: {(1, 3, 4): {1, 2, 3, 4, 5, 6}}
In [53]: d2[(1,3,4)]
Out[53]: {1, 2, 3, 4, 5, 6}
In [54]: f = d2.get((1,3,4))
In [55]: f
Out[55]: {1, 2, 3, 4, 5, 6}
In [56]: type(f)
Out[56]: set
#如果不存在,则返回
In [57]: d2.get(1,50)
Out[57]: 50
# 如果存在,则返回
In [59]: d2.get((1,3,4),50)
Out[59]: {1, 2, 3, 4, 5, 6}
In [60]: f = d2.setdefault(4,400)
In [61]: f
Out[61]: 400
In [62]: d2
Out[62]: {(1, 3, 4): {1, 2, 3, 4, 5, 6}, 4: 400}
字典增加和修改
- d[key] = value
将key对应的值修改为value
key 不存在添加新的kv对 - update([other]) -> None
使用一个字典的kv对更新本字典
key不存在,就添加
key存在,覆盖已经存在的key对应的值
就地修改
d.upadte(red=1)
d.update((('red',2),))
d.update({'red':3})
In [63]: d2[100] = 100
In [64]: d2
Out[64]: {(1, 3, 4): {1, 2, 3, 4, 5, 6}, 4: 400, 100: 100}
In [67]: d2
Out[67]: {(1, 3, 4): {1, 2, 3, 4, 5, 6}, 4: 300, 100: 100}
In [68]: d3 = {100:1000, 5:'abc'}
In [69]: d3
Out[69]: {100: 1000, 5: 'abc'}
In [70]: d2.update(d3,red =1)
In [71]: d2
Out[71]: {(1, 3, 4): {1, 2, 3, 4, 5, 6}, 4: 300, 100: 1000, 5: 'abc', 'red': 1}
字典删除
- pop(key[,default])
key 存在,移除它,并返回它的value
key 不存在,返回给定的default
default未设置,key不存在则抛出KeyError异常 popitem()
移除并返回一个任意的键值对
字典为empty,抛出KeyError异常clear()
清空字典
字典删除
del语句
In [72]: a = True
In [73]: b = [6]
In [76]: d = {'a':1,'b':b,'c':[1,3,5]}
In [77]: del a
In [78]: a
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-78-3f786850e387> in <module>()
----> 1 a
NameError: name 'a' is not defined
In [79]: del d['c']
In [80]: d
Out[80]: {'a': 1, 'b': [6]}
In [81]: del b
In [82]: d
Out[82]: {'a': 1, 'b': [6]}
In [84]: del d['b']
In [85]: d
Out[85]: {'a': 1}
# del d['b'] 看着像删除了一个对象,本质上减少了一个对象引用,del实际上删除的是名称,而不是对象
字典遍历
默认打印的是keys
In [86]: d2
Out[86]: {(1, 3, 4): {1, 2, 3, 4, 5, 6}, 4: 300, 100: 1000, 5: 'abc', 'red': 1}
In [87]: for item in d2:
...: print(item)
...:
(1, 3, 4)
4
100
5
red
打印value 和key
In [89]: for item in d2.values():
...: print(item)
...:
{1, 2, 3, 4, 5, 6}
300
1000
abc
1
In [90]: for item in d2.keys():
...: print(item)
...:
(1, 3, 4)
4
100
5
red
字典解构
In [92]: for k,b in d2.items():
...: print(k,b)
...:
(1, 3, 4) {1, 2, 3, 4, 5, 6}
4 300
100 1000
5 abc
red 1
#只取key的情况
In [91]: for k,_ in d2.items():
...: print(k)
...:
(1, 3, 4)
4
100
5
red
总结
- Python3 中 ,keys、values、 items()方法返回一个类似一个生器的可迭代对象,不会把函数的反回结果复制到内存中
- Python2 中,上面的方法会返回一个新的列表,占据新的内存空间,所以Python2 建议使用iterkeys、itervalues版本,返回一个迭代器,而不是一个copy
标准库datetime
datetime模块
对日期、时间 、时间戳的处理datetime类
类方法
today() 返回本地时区当前时间的datetime对象
now(tz=None)返回当前时间的datetime对象,时间到微秒,如果tz为None,返回和today()一样
utcnow() 没有时区的当前时间
fromtimestamp(timestamp,tz=None)从一个时间戳返回一个datetime对象- datetime对象
timestamp()返回一个到微秒的时间戳
时间戳:格林威治时间1970年1月1日0点到现在秒数
In [2]: datetime.datetime.now()
Out[2]: datetime.datetime(2020, 7, 30, 21, 3, 4, 140745)
In [3]: datetime.datetime.now().timestamp()
Out[3]: 1596114189.706269
标准库datetime
构造方法 datetime.datetime(2016,12,6,16,29,43,79043)
year、 month、 day、hour、minute、 second、 microsecond,取datetime对象的年月日时分秒及微秒
weekday() 返回星期的天,周一0,周日6
isoweekday()返回星期的天,周一1,周日7
date()返回日期date对象
time()返回时间time对象
repliace()修改并返回新的时间
isocalendar()返回一个三元组(年,周数,周的天)
In [2]: datetime.datetime.now()
Out[2]: datetime.datetime(2020, 7, 30, 21, 3, 4, 140745)
In [3]: datetime.datetime.now().timestamp()
Out[3]: 1596114189.706269
In [4]: a = datetime.datetime.now()
In [5]: a
Out[5]: datetime.datetime(2020, 7, 30, 21, 14, 47, 500215)
In [6]: a.weekday()
Out[6]: 3
标准库datetime
- 日期格式化
类方法strptime(date_string,format),返回datetime对象
对象方法strftime(format),返回字符串
字符串format函数格式化
In [16]: dt = datetime.datetime.now()
In [17]: dt = dt.strftime('%Y-%m-%d-%H-%M-%S')
In [18]: dt
Out[18]: '2020-07-30-21-21-39'
利用format 格式化
In [26]: a = datetime.datetime.now()
In [27]: '{}-{}-{}-{}-{}-{}'.format(a.year,a.month,a.day,a.hour,a.minute,a.second)
Out[27]: '2020-7-30-21-27-33'
标准库datetime
timedelta对象
datetime2 = datetime1 + timedelta
datetime2 = datetime1 - timedelta
timedelta = datetime1 - datetime2构造方法
datetime.timedelta(days=0,seconds=0,microseconds=0,milliseconds=0,minutes=0,hours=0,weeks=0)
year = datetime.timedelta(days=365)
total_seconds()返回时间差的总秒数
In [36]: h
Out[36]: datetime.timedelta(days=1)
In [37]: h = datetime.timedelta(hours=24)
In [38]: h
Out[38]: datetime.timedelta(days=1)
In [39]: datetime.datetime.now() - h
Out[39]: datetime.datetime(2020, 7, 29, 21, 37, 6, 827493)
标准库time
将调用的线程挂起指定的秒数 ~
In [40]: import time
In [41]: time.sleep(1)
列表解析List
语法
[返回值for 元素 in 可迭代对象 if 条件]
使用中括号[],内部是for循环,if条件语句可选
返回一个新的列表列表解析式是一种语法糖
编译器会优化,不会为简写而影响效率,反而因优化提交了效率;
减少程序员工作量,减少出错;
简化了代码,但可读性增强
In [9]: newlist1 = [(i+1)**2 for i in range(10)]
In [10]: newlist1
Out[10]: [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
举例1、获取10以内的偶数,比较执行效率
even = []
In [11]: even = []
In [12]: for x in range(10):
...: if x % 2 == 0:
...: even.append(x)
In [13]: even
Out[13]: [0, 2, 4, 6, 8]
In [15]: even = [ x for x in range(10) if x%2 ==0]
In [16]: even
Out[16]: [0, 2, 4, 6, 8]
举例三种输出结果
In [19]: list1 = [(i,j)for i in range(7) if i>4 for j in range(20,25) if j>23]
In [20]: list1
Out[20]: [(5, 24), (6, 24)]
In [23]: list2 = [(i,j) for i in range(7) for j in range(20,25) if i>4 if j>23]
In [24]: list2
Out[24]: [(5, 24), (6, 24)]
In [28]: list3 = [(i,j) for i in range(7) for j in range(20,25) if i>4 and j>23]
...:
In [29]: list3
Out[29]: [(5, 24), (6, 24)]
练习,生成1-10 平方的列表
print([i**2 for i in range(1,11)])
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
练习,有一个列表lst = [1,4,9,16,2,5,10,15],生成一个新列表,要求新列表元素是lst想领2项的和
In [34]: lst = [1,4,9,16,2,5,10,15]
In [35]: [ lst[i] + lst[i+1] for i in range(len(lst)-1)]
Out[35]: [5, 13, 25, 18, 7, 15, 25]
In [44]: lst = [1,4,9,16,2,5,10,15]
In [45]: for i in range(len(lst)-1):
...: newlist= lst[i] + lst[i+1]
...: print(newlist)
...:
5
13
25
18
7
15
25
用一行代码打印9 9乘法表
In [56]: print('\n'.join([''.join(['{}*{}={}\t'.format(x,y,y*x) for x in range(1,y+1)]) for y in range(1,10)]))
1*1=1
1*2=2 2*2=4
1*3=3 2*3=6 3*3=9
1*4=4 2*4=8 3*4=12 4*4=16
1*5=5 2*5=10 3*5=15 4*5=20 5*5=25
1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36
1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49
1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64
1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81
高效方法二
In [86]: print(''.join(['{}*{}={:<3}{}'.format(j,i,i*j,'\n' if i==j else'') for i in range(1,10) for j in range(1,i+1)]))
1*1=1
1*2=2 2*2=4
1*3=3 2*3=6 3*3=9
1*4=4 2*4=8 3*4=12 4*4=16
1*5=5 2*5=10 3*5=15 4*5=20 5*5=25
1*6=6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36
1*7=7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49
1*8=8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64
1*9=9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=81
练习
“0001.abadicddws” 是ID格式,要求ID格式是以点号分割, 左夯实是4位从1开始的整数,右边是10位随机小写英文字母。今次生成前100个列表
In [100]: ['{:04}.{}'.format(n,''.join([random.choice(bytes(range(97,123)).decode()) for _ in range(10)])) for n in range(1,101)]
Out[100]:
['0001.yibbcfebfn',
'0002.wvomuwuiaj',
'0003.bplvnhkgfp',
'0004.tnrjwiuipv',
...
生成器表达式(Generator expression)
- 语法
(返回值for 元素 in 可迭代对象if条件)
列表解析式的中括号抱成小括号就行了
返回一个生成器 - 和列表解析式的区别
生成器表达式是按按需计算(或称惰性求值、延迟计算),需要的时候才计算值
列表解析式是立即返回值 - 生成器
可迭代对象
迭代器
生成器表达式
和列表解析式的对比
计算方式
生成器表达式延迟计算,列表解析式立即计算内存占用
单从返回值本身来说,生成器表达式省内存,列表解析式返回新的列表
生成器没有数据,内存占用少,但是使用的时候,虽然一个个返回数据,但是合起来占用的内存也差不多
列表解析式构造新的列表需要占用内存计算速度
单看计算时间看,生成器表达式耗时非常短,列表解析式耗时长
但是生成器本身并没有返回任何值,只返回了一个生成器对象
列表解析式构造并返回了一个新的列表
集合解析式
语法
(返回值 for 元素 in 可迭代对象 if 条件)
列表解析式的中括号换成大括号{}就行了
立即返回一个集合用法
{(x,x+1) for x in range(10)}
{{x} for x in range(10)}
字典解析式
语法
(返回值 for 元素in可迭代对象if条件)
列表解析式的中括号换成大括号{}就可行了
使用key:value 形势
立即返回一个字典用法
{x:(x,x+1) for x in range(10)}
{x:[x,x+1] for x in range(10)}
{(x,):[x,x+1] for x in range(10)}
{[x]:[x,x+1] for x in range(10)}
{chr(0x41+1):x**2 for x in range(10)}
{str(x):y for x in range(3) for y in range(4)}
In [3]: {chr(0x41+x):x**2 for x in range(5)}
Out[3]: {'A': 0, 'B': 1, 'C': 4, 'D': 9, 'E': 16}
In [4]: {str(x):y for x in range(3) for y in range(4)}
Out[4]: {'0': 3, '1': 3, '2': 3}
# 等价于
In [13]: ret = {}
In [14]: for x in range(3):
...: for y in range(4):
...: ret[str(x)] = y
...:
In [15]: print(ret)
{'0': 3, '1': 3, '2': 3}
总结
- Python2 引入了列表解析式
- Python2.4引入了生成器表达式
- Python3 引入集合、字典解析式,并迁移到了2.7
- 一般来说,应该多应用解析式,简短、高效
- 如果一个解析式非常复杂,难以读懂,要考虑拆解成for循环
- 生成器和迭代器是不同的对象,但都是可迭代对象。
内建函数
标识 id
返回对象的唯一标识,CPython 返回内存中类型hash()
返回一个对象的哈希值
- 类型type()
返回对象的类型
- 类型转换
float() int() bin() hex() oct() bool() list() tuple() dict() set() complex() bytes() bytearray()
- 输入input([prompt])
接收用户输入,返回一个字符串
- 打印 print(*objects, sep=’’,end=’\n’,file=sys.stdout, flush=False)
打印输出,默认使用空格分割、换行结尾,输出到控制台
- 对象长度len(s)
返回一个集合类型的元素个数
- isinstance(obj,class_or_tuple)
判断对象obj是否属于某种类型或者元组中列出的某个类型
isinstance(True,init)
- issubclass(cls,calss_or_tuple)
判断类型cls是否是某种类型的了类或元组中列出的某个类型的子类
issubclass(bool,int)
- 绝对值abs(x) x 为数值
- 最大值max() 最小值min()
返回可迭代对象中最大或最小值
返回多个参数中最大或最小值 - round(x) 四舍六入五取偶, round(-0.5)
- pow(x,y) 等价于x**y
range(stop)从0开始到stop-1 的可迭代对象; range(start,stop,[,step]) 从start开始到stop-1 结束步长为step 的可迭代对象
divmod(x,y) 等价于tuple(x//y,x%y)
- sum(oterable[,start])对可迭代对象的所有数值元素求和
sum(range(1,100,2))
补充列表全部拷贝
In [17]: lst = [1,2,3]
In [18]: test = lst[:]
In [19]: test
Out[19]: [1, 2, 3]
python 求一到100的和
In [20]: sum(range(1,101))
Out[20]: 5050
chr(i) 给一个一定范围的整数返回对应的字符
chr(97) chr(20013)ord(c) 返回字符对应的整数
ord(‘a’) ord(‘中’)
str() 、 repr()、 ascii()
sorted(iterable)
sorted(iterable[,key][,reverse])排序
返回一个新的列表,默认升序
reverse 是反转
sorted([1,3,5])
sorted([1,3,5], reverse=True)
sorted({'c':1, 'b':2, 'a':1})
In [5]: lst = [1,4,3,5,8,7]
In [6]: sorted(lst)
Out[6]: [1, 3, 4, 5, 7, 8]
In [7]: sorted(lst,reverse=True)
Out[7]: [8, 7, 5, 4, 3, 1]
翻转 reversed(seq)
返回一个翻转元素的迭代器
list(reversed(*13579*))
for x in reversed(["c","b","c"]: )
In [13]: for k,v in enumerate(range(5)):
...: print(k,v,end='\t')
...:
0 0 1 1 2 2 3 3 4 4
In [14]: for k,v in enumerate("mnopq",start=10):
...: print(k,v,end='\t')
...:
10 m 11 n 12 o 13 p 14 q
- 迭代器和取元素iter(terable)、next(iterator)
iter 将一个可迭代对象封装成一个迭代器
next对一个迭代器取下一个元素。如果全部元素都取过了,再次next会抛StopIteration异常
it = iter(range(5))
nex(it)
it = reversed([1, 3, 5])
next(it)
可迭代对象
能够通过迭代一次次返回不同的元素的对象。所谓相同不是指值是否相同。而元素在容器中是否是同一个,例如列表中值可以重复。
可以迭代,但是未必有序,未必可索引。
可迭代对象有: list、tuple、string、bytes、bytearray、range、set、dict、生成器等;
可以使用成员操作符in 、 not in,in本质上就是在遍历对象;
3 in range(10)
3 in (x for x in range(10))
3 in {x:y for x,y in zip(range(4),range(4,10))}
迭代器
特殊的对象,一定是可迭代对象,具备可迭代对象的特征;
通过iter方法把一个可迭代对象封闭成迭代器;
通过next 方法, 迭代 迭代器对象;
生成器对象,就是迭代器对象
In [1]: for x in iter(range(10)):
...: print(x)
In [3]: g = (x for x in range(10))
In [4]: print(type(g))
<class 'generator'>
In [5]: print(next(g))
0
In [6]: print(next(g))
1
In [7]: print(next(g))
2
In [8]: print(next(g))
3
- 拉链函数zip(*iterables)
像拉链一样,把多个可迭代对象合并在一起,返回一个迭代器
将每次从不同对象中取到的元素合并成一个元组
list(zip(range(10),range(10)))
list(zip(range(10),range(10),range(5),range(10)))
dict(zip(range(10),range(10)))
{str(x):y for x,y in zip(range(10),range(10))}
字典练习
打印每一位数字及期重复的次数
while True:
num = input('Please input a positice intteger >>').strip()
if num.isdigit():
break
else:
print('Only digits are allowed! ')
record = {}
for i in num:
record[i] = record.get(i,0) +1
print(num,record,sep='\n')
方法二
#!/usr/bin/env python
# -*- coding: utf-8 -*-
num = input('>> ')
d = {}
for c in num:
if not d.get(c):
d[c] = 1
continue
d[c] +=1
print(d)
d = {}
for c in num:
if c not in d.keys():
d[c] =1
else:
d[c] += 1
print(d)
>> 18933
{'1': 1, '8': 1, '9': 1, '3': 2}
{'1': 1, '8': 1, '9': 1, '3': 2}
字符串重复统计
字符表’abcdefghijklmnopqrstuvwxyz’
随机挑选2个字母组成字符串,共挑选100个
降序输出这100个字符串及重复的次数
import random
import string
strs = 'abcdefghijklmnopqrstuvwxyz'
dic = {}
for _ in range(100):
randstr = ''.join(random.sample(strs,2))
# randstr = ''.join(random.choice(strs) for _ in range(0,2))
# randstr = ''.join(random.sample(string.ascii_lowercase,2))
if randstr not in dic:
dic.setdefault(randstr,1)
else:
dic[randstr] +=1
sortstr = sorted(dic.keys())
for i in sortstr:
print('{:<4} {:<4}'.format(i,dic[i]))