






MongoDB NoSQL使用
[toc]
NoSQL: Not Only SQL
![]()
常用需求及实现
大数据问题: BigData
并行数据库系统,无共享体系结构中,采用关系结构模型,像MySQL的水平切片技术,分区查询;
NoSQL数据库管理系统: 不是一种单一单纯的技术,非关系模型、分布式、不支持ACID数据库设计范式;
简单数据模型;
元数据和数据分离;
弱一致性;
高吞吐量;
高水平扩展能力和低端硬件集群;
NewSQL数据库管理系统
相关产品: Clustrix、 GenleDB 、ScaleBase、NimbusDB、mysql(NDBCluster、Drizzle)
云数据管理系统:
相关产品: DBAAS,RDS
大数据的分析处理:
常见的有MapReduce机制:将大的数据映射成键值对,而后对各各键值对处理后进行聚合;
而hadoop 就是类似于这种系统; habase也是NoSQL的一种;
CAP: 强一致性;可用性;分区容错性(出现脑裂的时候可否处理业务需求);
最终一致性细分:
困果一致性;
读自己写一致性;
会话一致性;
单调读一致性;
时间轴一致性;
ACID & BASE
Atomicity 原子性;
Consistency 一致性;
Isolation 隔离性 ;
Durability 持久性;
BASE 基本可用;
ACID特性: 强一致性、隔离性、采用悲观保守的方法、难以变化;
BASE特性: 弱一致性、可用性优先、采用乐观的方法、更简单、更快;
数据一致性的实现技术:
NRW
2PC
Paxos
Vecotr Clock
数据存储模型: www.nosql-databases.org
列式存储模型
文档存储模型
键值数据模型
图式数据模型
列式模型:
应用场景: 在分布式文件系统之上提供支持随机读写分布式数据存储;
典型产品: HBase、Hypertable、Cassandra
数据模型: 以"列"为中心进行存储 ,将同一列数据存储在一起;
优点: 快速查询、高可扩展性、易于实现分布式扩展;
文档模型:
应用场景:非强事务需求的web应用;
典型产品:MongoDB、ElasticSearch(构建的搜索引擎工具)、CouchDB、CouchBase Server
数据模型: 键值模型,存储为文档;
优点: 数据模型无需事先定义
键值模型:
应用场景: 内容缓存,用于大量并行数据访问高载场景;
典型产品: Redis、DynamoDB、Riak、Redis;
数据模型: 基于哈希表实现的key-value模型;
优点: 查询迅速, 缺点:数据没有结构;
图式模型:
应用场景: 社交网络、推荐系统、关系图普
典型产品: Neo4J 、TITAN 、 Infinite Graph
数据模型: 图式结构
优点: 适应于图式计算场景
MongoDB: NoSQL、文档存储、Json数据模型
适用场景:
Websites
Caching
High volume, low value
High scalability
Storage of program objects and json
不适用场景:
Hightly transactional
Ad-hoc business intelligence
Problems requiring SQL
mongo 的安装与使用
# vim /etc/yum.repos.d/mongodb.repo
[mongodb-org-3.4]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/3.4/x86_64/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-3.4.asc
# yum clean all
# yum makeacahe
# yum -y install mongodb-org
server包生成的关键文件
# rpm -ql mongodb-org-server
/etc/mongod.conf
/lib/systemd/system/mongod.service
/usr/bin/mongod
/var/lib/mongo
/var/log/mongodb
/var/log/mongodb/mongod.log
/var/run/mongodb
shell包生成的关键文件
# rpm -ql mongodb-org-shell
/usr/bin/mongo
tools包生成的关键文件
# rpm -ql mongodb-org-tools
/usr/bin/bsondump
/usr/bin/mongodump
/usr/bin/mongoexport
/usr/bin/mongofiles
/usr/bin/mongoimport
/usr/bin/mongooplog
/usr/bin/mongoperf
/usr/bin/mongorestore
/usr/bin/mongostat
/usr/bin/mongotop
server端配置项
# vim /etc/mongod.conf
Mongo基本操作
help # 查看常用的使用帮助命令;
db.help() # 查看对库操作的使用帮助;
db.mycoll.cind().help()
db.mycoll.help()
show dbs # 查看目前存在哪些库;
show collections # 列出列表;
use testdb # 切换至哪个库,或者新建哪个库
db.status() #查看当前库的状态;
db.version() # 查看当前库的版本;
db.serverStatus() # 查看当前MongoDB服务的状态;
show users # 查看当前存在哪些用户;
show logs # 查看Mongo开启了哪些日志记录;
user db.help() # 查寻帮助;
db.getCollectionNames() # 查看列表名称;
db.students.status() #查看某个库,某张表的状态;
# Collection Query Criteria Modifier
db.users.find( {age: {$gt: 18} } ).sort( {age: 1} )
JSON: JavaScript Object Notation
名称/值对象的集合;
值的有序列表;
db.students.inert( {name:"tome", age:23} )
show clollections
show dbs
db.status
db.students.stats()
db.getCollectionNames()
db.students.insert([name:''renjin",age:23,gender:"M"])
db.students.find()
db.students.insert([name:"ssjinyao",Age:23,Course:"PieXieJianFa"])
find() 的高级用法:
比较操作:
$gt, 语法格式{filed: {$gt VALUE}}
db.statuents.find({Age:{$gt 23}})
$gte
$lt
$lte
$ne
$in,语法格式{filed: {$in: ['value']}}
db.students.find{Age:{$in: [20,23]}}
组合条件: 逻辑运算
$or: 或运算,语法格式{$or: {<expression1>,...}}
db.students.find({$or: {Age: {$nin: [20,40], age {$nin:[20,40]}}})
db.students.find({$or: [{Age: {$nin: [20,40]}}, {age: {$nin: [20,40]}}]})
$and: 与运算
$not: 非运算
$nor: 反运算,返回不符指定件的所有文档
元素查询: 根据文档中是否存在指定的字段进行查询;
$exists: 语法格式{$filed:{$exists:<boolean>}}
db.students.find({gender: {$exits: false}})
$mod:
$type: 返回指定的字段的值的类型为指定类型的文档,语法格式{field:{$type: <BSON type>}}
Double,String,Object, Arrary, Binary data, Undefined, Boolean,Data ,Null, Regular Expression, JavaScript, Timestamp
更新操作:
db.mycoll.update()
$set: 修改字段的值为新指定的值: 语法格式{filed: value}, {$set: {filed: new_value}})
$unset: 删除指定字段;语法格式({filed: value}, {$unset:{filed1, field2,....}})
db.students.update({name: "renjin"}, {$set: {age: 22}})
$rename: 更改字段名,语法格式({$rename: {oldname: newname, oldname: newname}})
db.students.update({$rename: {age:Age})
$inc
删除操作:
db.mycoll.remove(<query>,<justOne>)
db.students.remove({age:21})
db.students.findOne({Age: {$gt:10}})
删除collection:
db.mycoll.drop()
db.studetns.drop()
删除database:
db.dropDatabase()
php+mongodb
php的mongo扩展
MongoDB Indexes and Administration
索引
类型: B+ Tree、hash、空间索引、全文索引
MongoDB索引类型
单字段索引
组合索引(多字段索引)
多键索引
空间索引
文本索引
hash索引 hash 索引只支持精确值查找
db.people.ensureIndex({ zipcode:1}, {background: ture})
db.account.ensureIndex( { username: 1 } , {unique: ture, dropDups: true })
MongoDB与索引相关的方法:
db.mycoll.ensureIndex(field[,options])
name、unique、dropDups、sparse
db.mycoll.dropIndex(index_name)
db.mycoll.dropIndexes()
db.mycoll.getIndexes()
db.mycoll.reIndex()
mongodb 用for 循环来连续插入数据
use testdb
for (i=1; i<=1000;i++) db.students.insert({name:"student"+i, age:(i%120), address:"#85 Wenhua Road, Zhengzhou, China"})
{ "_id" : ObjectId("5acdb56cdf2f304c1068d56c"), "name" : "student1", "age" : 1, "address" : "#85 Wenhua Road, Zhengzhou, China" }
{ "_id" : ObjectId("5acdb56cdf2f304c1068d56d"), "name" : "student2", "age" : 2, "address" : "#85 Wenhua Road, Zhengzhou, China" }
{ "_id" : ObjectId("5acdb56cdf2f304c1068d56e"), "name" : "student3", "age" : 3, "address" : "#85 Wenhua Road, Zhengzhou, China" }
{ "_id" : ObjectId("5acdb56cdf2f304c1068d56f"), "name" : "student4", "age" : 4, "address" : "#85 Wenhua Road, Zhengzhou, China" }
{ "_id" : ObjectId("5acdb56cdf2f304c1068d570"), "name" : "student5", "age" : 5, "address" : "#85 Wenhua Road, Zhengzhou, China" }
{ "_id" : ObjectId("5acdb56cdf2f304c1068d571"), "name" : "student6", "age" : 6, "address" : "#85 Wenhua Road, Zhengzhou, China" }
{ "_id" : ObjectId("5acdb56cdf2f304c1068d572"), "name" : "student7", "age" : 7, "address" : "#85 Wenhua Road, Zhengzhou, China" }
{ "_id" : ObjectId("5acdb56cdf2f304c1068d573"), "name" : "student8", "age" : 8, "address" : "#85 Wenhua Road, Zhengzhou, China" }
{ "_id" : ObjectId("5acdb56cdf2f304c1068d574"), "name" : "student9", "age" : 9, "address" : "#85 Wenhua Road, Zhengzhou, China" }
{ "_id" : ObjectId("5acdb56cdf2f304c1068d575"), "name" : "student10", "age" : 10, "address" : "#85 Wenhua Road, Zhengzhou, China" }
{ "_id" : ObjectId("5acdb56cdf2f304c1068d576"), "name" : "student11", "age" : 11, "address" : "#85 Wenhua Road, Zhengzhou, China" }
{ "_id" : ObjectId("5acdb56cdf2f304c1068d577"), "name" : "student12", "age" : 12, "address" : "#85 Wenhua Road, Zhengzhou, China" }
{ "_id" : ObjectId("5acdb56cdf2f304c1068d578"), "name" : "student13", "age" : 13, "address" : "#85 Wenhua Road, Zhengzhou, China" }
{ "_id" : ObjectId("5acdb56cdf2f304c1068d579"), "name" : "student14", "age" : 14, "address" : "#85 Wenhua Road, Zhengzhou, China" }
{ "_id" : ObjectId("5acdb56cdf2f304c1068d57a"), "name" : "student15", "age" : 15, "address" : "#85 Wenhua Road, Zhengzhou, China" }
{ "_id" : ObjectId("5acdb56cdf2f304c1068d57b"), "name" : "student16", "age" : 16, "address" : "#85 Wenhua Road, Zhengzhou, China" }
{ "_id" : ObjectId("5acdb56cdf2f304c1068d57c"), "name" : "student17", "age" : 17, "address" : "#85 Wenhua Road, Zhengzhou, China" }
{ "_id" : ObjectId("5acdb56cdf2f304c1068d57d"), "name" : "student18", "age" : 18, "address" : "#85 Wenhua Road, Zhengzhou, China" }
{ "_id" : ObjectId("5acdb56cdf2f304c1068d57e"), "name" : "student19", "age" : 19, "address" : "#85 Wenhua Road, Zhengzhou, China" }
{ "_id" : ObjectId("5acdb56cdf2f304c1068d57f"), "name" : "student20", "age" : 20, "address" : "#85 Wenhua Road, Zhengzhou, China" }
Type "it" for more
> it
# mongo为了结省服务器资源,不会将所有的字段一下子列出来,而需要输入it来翻页查看,与more类似
在name 1 上构建升序索引
db.students.ensureIndex({name: 1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
db.students.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "testdb.students"
},
{
"v" : 2,
"key" : {
"name" : 1
},
"name" : "name_1",
"ns" : "testdb.students"
}
]
移除之前建立的索引
db.students.dropIndex("name_1")
{ "nIndexesWas" : 2, "ok" : 1 }
查看索引是否被移除
db.students.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "testdb.students"
}
]
建立维一键索引
db.students.ensureIndex({name: 1},{unique: true})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
>
>
> db.students.getIndexes()
[
{
"v" : 2,
"key" : {
"_id" : 1
},
"name" : "_id_",
"ns" : "testdb.students"
},
{
"v" : 2,
"unique" : true,
"key" : {
"name" : 1
},
"name" : "name_1",
"ns" : "testdb.students"
}
]
利用索引快速查询
db.students.find({name: "student500"})
{ "_id" : ObjectId("5acdb56cdf2f304c1068d75f"), "name" : "student500", "age" : 20, "address" : "#85 Wenhua Road, Zhengzhou, China" }
db.students.find({name: "student500"}).explain()
查看索引执行过程
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "testdb.students",
"indexFilterSet" : false,
"parsedQuery" : {
"name" : {
"$eq" : "student500"
}
},
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"name" : 1
},
"indexName" : "name_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"name" : [ ]
},
"isUnique" : true,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"name" : [
"[\"student500\", \"student500\"]"
]
}
}
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "ssjinyao",
"port" : 27017,
"version" : "3.4.14",
"gitVersion" : "fd954412dfc10e4d1e3e2dd4fac040f8b476b268"
},
"ok" : 1
}
Mongod的常用先项:
General option: 通用选项
fork = {true|false}: mongod是否运行在后台;
bind_ip = IP: 指定监听的地址;
port=PORT:指定监听的端口,默认为27017,httpd访问28017;
maxConns=: 并发最大连接数;
pidfilepath=: pid 文件位置;
httpinterface=:内置httpd统计信息等;
keyFile=:主从同步基于密钥的认证;
auth: 是否开启认证功能;
repair: 服务器意外重启,或未正重关闭时,要使用repair来修复;
journal:是否启用日志功能;
jounalCommit: 日志提交的时间间隔;
cpu: 间断性的显示内存CPU的使用率;
slowms arg: 超出指定值后采用慢查询;
Replication options 复制选项
Master/slvae options 主从复制选项
Replica set options 复制集选项
Sharding options 跟切片相关的选项
MongoDB的复制功能
两种类型:
master/slave
replica set: 复制集、副本集
两种类型: 主节点支持读写操作,而从节点仅支持读操作;
服务于同一数据集的多个mongodb实例;
主节点操作数据修改操作保存至oplog中;
arbiter: 仲裁者,即便用不上三个节点,也添加三个节点,以避免脑裂;
工作特性:至少三个,且应该为奇数据个节点;可以使用arbiter来参与选举;
hertbeat(默认2s传递一次),自动失效转移(通过选举方式实现)
复制集的中节点分类的集中类型:
0优先级的节点: 准备节点,这种节点不会选举成为主节点,但可以参与选举过程;
被隐藏的从节点: 首先是一个0优先级的从节点,且地客户端不可见;
延迟复制的从节点: 当在主节点误删除数据时,可以立即断开主从,可保留从节点上未改变的数据;
首先是一个0优先级的从节点,且复制时间落后于主节点一个固定时长;
arbiter:
MongoDB的复制架构:
oplog
heartbeat
oplog: 大小固定的文件,存储在local数据库中;
即便从节点有aplog也不会使用;
初始同步(initial sync)
回滚后追赶(post-rollback catch-up)
切分块迁移(sharding chunk migrations)
local: 存放了副本集的所有元数据和oplog: 用于存储aplog的是一个名为oplog.rs的collection
aplog.rs 的大小依赖于OS 及文件系统 ;
Mongo的数同步类型 :
初始同步:
节点没有任何数据时
节点丢失副本复制历史
复制
初始同步的步骤:
1、克隆所有数据;
2、应用数据集的所有改变,复制oplog并应用于本地;
3、为所有collection构建索引;
Mongod 数据同步过程
初始同步:
节点没有任何数据
从节点丢失复本,复制历史数据;
初始同步的步骤:
1、克隆所有数据库;
2、应用数据集的所有改变;复制oplog并应用在本地;
3、为所有的collection构建索引;
这样初始同步就完成了;
优于MySQL的地方, MongoDB 支持多线程复制功能;
# vim /etc/mongd.conf
replSet=testSet
replIndexPrefetch=_id_only
# systemctl mongod restart
show dbs
use local
show collections
# node2的配置
# 将需要安装的rpm 包复制到第二个节点上,或者在另一台服务器上配置mongo的yum源;
# yum -y install mongodb-org-server
# mkdir -pv /mongodb/data
# chown -R mongod.mongod /mongodb
# node3的配置
# 将需要安装的rpm 包复制到第三个节点上,或者在另一台服务器上配置mongo的yum源;
# yum -y install mongodb-org-server
# mkdir -pv /mongodb/data
# chown -R mongod.mongod /mongodb
# scp /etc/mongod.conf root@node2:/etc/
# scp /etc/mongod.conf root@node3:/etc/
# 保证三个节点的配置文件一致,并将服务器启动;
rs.conf()
rs.status()
rs.initiate()
rs.status()
rs.help() # 查找mongo的帮助文档,查看如何添加主机进来, rs. 主要指mongo的分布式配置;
rs.add("172.16.55.128") # 在主节点的mongo中执行;
show dbs
# 从节点默认是不支持查询的,因此需要手动开启;
# 在node2 节点中,将当前服务器节点改为从节点;
rs.salveOK()
rs.status()
rs.isMaster() # 查看自己是否为主节点;
# 因此,当服务器改为从节点之后可以在从节点上查询信息;
# db.statudents.findOne();
# 第三个节点
rs.add("172.16.55.129") # 在主节点的mongo中执行
# 在 node3 节点中,将当前服务器节点改为从节点;
rs.salveOK()
# 注要写数据的时候,还是要到主节点中支写;
db.classes.insert({class: "One", nostu: 40}) # 尝试在主节点中插入数据;
show collections # 这里主服务器对应的数据已经有了;
db.classes.findOne() # 尝试在从服务器中查找数据,如查有数据,则说明数据同步没有问题;
# 从节点中是不能写入数据;
rs.stepDown() # 将主节点强制成为从节点;
rs.status() # 可以看出,其中有一个节点会自动成为主节点;
db.printReplicationInfo() # 查看产中事件的间时,大小;
副本集的重新先举的影响条件:
心跳信息
优先级
optime
网络连接
网络分区
先举机制:
触发选举的事件
新副本集初始化时;
从节点联系不到主节点时;
主节点"下台"时;
主节点收到stepDown()命令时;
某从节点有更高的优先级且已经满足了成主节点的其它所有条件;
主节点无法联系到副本集的"多数方";
cfg= rs.conf() # 保存当前mongo的配置;
cfg.member[1].priority=2
rs.conf() # 这时的配置依然是1
rs.reconfig(cfg) # 生效配置则必需要在主节点中进行;
# 触发新的选举机制;
cfg = rs.confg()
cfg.member[2].abiterOnly=ture # 设置abiterOnly 属性;
rs.reconfgi(cfg)
rs.conf()
rs.printSlaveReplicationInfo() # 同时也可以看是每个从节点是否落后于主节点;
MongoDB的分片:
sharding 分片
# 随着公司业务的分展,数据集会变的越来越大;
# 会在某一个时刻,CPU,内存,IO 等单机上出现瓶颈;
# 因此向上外向外扩展,向上扩展是经济形势的解决方案,而从技术角度,我们可以向外扩展;
MySQL: Gizzard, HivedDB(独立的项目,转门来对MySQL来实现分片的),MySQL Proxy + HSACLE, Hibernate Shared Pyshards
# 分片架构中的角色:
mongos: Router;
config server: 元数据服务器;
shard: 数据节点,也称mongod实例节点; 负责将数据存下来,并响应客户端的;
zookeeper: 通常用于分布式节点的协调;
# 基于范围切片
range
# 基于列表切片
list
# 基于hash切片
hash
写离散,读要集中
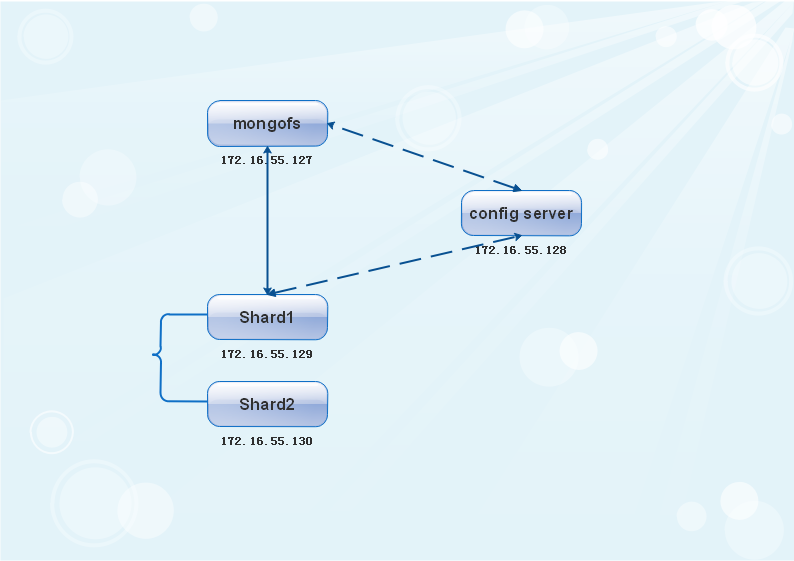
分片式架构配置
# rm -rf /mongodb/data/ # 注: 在生产中,这个操作非常危险!需要将数据库用mongodump 备份;
# 将mongodb 安装的rpm包,或者yum的配置文件用ansible 或scp 同步到其它四个节点上去;
# 在四个节点将mongodb 相关软件包都安装好
# 先要配置config server --> mongos --> Shard1 --> Shard2
-------------------------> confiserver 服务器配置
# vim /etc/mongod.conf
# replSet=testSet
# replIndexPrefetch=id_only #
dbpath=/mongodb/data
configsvr=true
# chown -R mongod.mongod /mongodb
# install -o mongod -g mongod -d /mongodb/data # 建立数据库的元数据 ;
# systemctl start mongod mongo # config server 默认监听在27019的端口上;
-----------------------> mongofs 服务器配置
# yum -y insetall mongodb-org-mongos #
# 启动 mongofs 节点
# mongos --configdb=172.16.55.172.16.55.128 --fork --logpath=/var/log/mongodb/mongo.log
# mongo --host 172.16.55.127
help
sh.status()
# 以下节点起动后
sh.addShard("172.16.55.129")
ss.addShard("172.16.55.120")
sh.enableShareding("testdb") # 在testdb中启有shard功能;
sh.help() # 查找shards集群相关的配置项;
sh.enableSharding(dbname) # 在哪个节点起用sharding;
sh.shardCollection(fullName,key,unique) # 在collection哪个键,索引上做sharding ;
sh.shardCollection("students", {"age" : 1 })
sh.status() # 此时就可以查看分片信息了;
use testdb;
for (i=1; i<=100000;i++) db.students.insert({name:"studentt"+i, age:(i%120),classes:"class"+(i%10),address:"www.ssjinyao.com, Magedu, #85 WenhuaRoad, BeiJin, China"}) # 批量插入测试数据;
use testdb
db.students.find().count()
sh.status() # 可以看到分片存储的信息;
db.databases.find("partitioned":true)
db.runCommands("listShards")
use admin
db.runCommand("listShards")
db.printShardingStatus()
sh.isBalancerRunning() # 查看均衡器状态,它会在需要时自动启动;
sh.getBalancerState() # 查看BlancerSate的状态;
-----------------------> Shard1 服务器配置
# vim /etc/mongod.conf
# replSet=testSet
# replIndexPrefetch=id_only # 注释以上配置
# dbpath=/mongodb/data
# chown -R mongod.mongod /mongodb
# systemctl start mongod
-----------------------> Shard2 服务器配置
# vim /etc/mongod.conf
# replSet=testSet
# replIndexPrefetch=id_only # 注释以上配置
# dbpath=/mongodb/data
# chown -R mongod.mongod /mongodb
# systemctl start mongod